Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Sotaro Kimura
PPTX, PDF
8,522 views
Kafkaを活用するためのストリーム処理の基本
2016/05/31 Apache Kafka Meetup Japan #1 での発表資料
Engineering
◦
Read more
24
Save
Share
Embed
Embed presentation
Download
Downloaded 98 times
1
/ 22
2
/ 22
Most read
3
/ 22
4
/ 22
5
/ 22
6
/ 22
7
/ 22
8
/ 22
9
/ 22
10
/ 22
11
/ 22
12
/ 22
13
/ 22
14
/ 22
15
/ 22
16
/ 22
17
/ 22
18
/ 22
19
/ 22
20
/ 22
21
/ 22
22
/ 22
More Related Content
PDF
噛み砕いてKafka Streams #kafkajp
by
Yahoo!デベロッパーネットワーク
PPTX
え、まって。その並列分散処理、Kafkaのしくみでもできるの? Apache Kafkaの機能を利用した大規模ストリームデータの並列分散処理
by
NTT DATA Technology & Innovation
PDF
IoT時代におけるストリームデータ処理と急成長の Apache Flink
by
Takanori Suzuki
PDF
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
PDF
Apache Hadoopの新機能Ozoneの現状
by
NTT DATA OSS Professional Services
PDF
Apache Kafka & Kafka Connectを に使ったデータ連携パターン(改めETLの実装)
by
Keigo Suda
PDF
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
噛み砕いてKafka Streams #kafkajp
by
Yahoo!デベロッパーネットワーク
え、まって。その並列分散処理、Kafkaのしくみでもできるの? Apache Kafkaの機能を利用した大規模ストリームデータの並列分散処理
by
NTT DATA Technology & Innovation
IoT時代におけるストリームデータ処理と急成長の Apache Flink
by
Takanori Suzuki
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
Apache Hadoopの新機能Ozoneの現状
by
NTT DATA OSS Professional Services
Apache Kafka & Kafka Connectを に使ったデータ連携パターン(改めETLの実装)
by
Keigo Suda
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
What's hot
PPTX
分散トレーシングAWS:X-Rayとの上手い付き合い方
by
Recruit Lifestyle Co., Ltd.
PDF
KafkaとPulsar
by
Yahoo!デベロッパーネットワーク
PDF
負荷テストを行う際に知っておきたいこと 初心者編
by
まべ☆てっく運営
PPTX
データ履歴管理のためのテンポラルデータモデルとReladomoの紹介 #jjug_ccc #ccc_g3
by
Hiroshi Ito
PPTX
その Pod 突然落ちても大丈夫ですか!?(OCHaCafe5 #5 実験!カオスエンジニアリング 発表資料)
by
NTT DATA Technology & Innovation
PDF
Docker Compose 徹底解説
by
Masahito Zembutsu
PPTX
大規模データ活用向けストレージレイヤソフトのこれまでとこれから(NTTデータ テクノロジーカンファレンス 2019 講演資料、2019/09/05)
by
NTT DATA Technology & Innovation
PPTX
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~(Kubernetes Meetup Tokyo #33 発表資料)
by
NTT DATA Technology & Innovation
PPTX
Cisco Modeling Labs (CML)を使ってネットワークを学ぼう!(基礎編)配布用
by
シスコシステムズ合同会社
PPTX
大量のデータ処理や分析に使えるOSS Apache Spark入門(Open Source Conference 2021 Online/Kyoto 発表資料)
by
NTT DATA Technology & Innovation
PDF
Java Clientで入門する Apache Kafka #jjug_ccc #ccc_e2
by
Yahoo!デベロッパーネットワーク
PDF
ストリーム処理を支えるキューイングシステムの選び方
by
Yoshiyasu SAEKI
PPTX
Redisの特徴と活用方法について
by
Yuji Otani
PDF
【第26回Elasticsearch勉強会】Logstashとともに振り返る、やっちまった事例ごった煮
by
Hibino Hisashi
PDF
AWSにおけるバッチ処理の ベストプラクティス - Developers.IO Meetup 05
by
都元ダイスケ Miyamoto
PDF
そんなトランザクションマネージャで大丈夫か?
by
takezoe
PDF
今話題のいろいろなコンテナランタイムを比較してみた
by
Kohei Tokunaga
PDF
ストリーム処理プラットフォームにおけるKafka導入事例 #kafkajp
by
Yahoo!デベロッパーネットワーク
PDF
KafkaとAWS Kinesisの比較
by
Yoshiyasu SAEKI
PDF
NetflixにおけるPresto/Spark活用事例
by
Amazon Web Services Japan
分散トレーシングAWS:X-Rayとの上手い付き合い方
by
Recruit Lifestyle Co., Ltd.
KafkaとPulsar
by
Yahoo!デベロッパーネットワーク
負荷テストを行う際に知っておきたいこと 初心者編
by
まべ☆てっく運営
データ履歴管理のためのテンポラルデータモデルとReladomoの紹介 #jjug_ccc #ccc_g3
by
Hiroshi Ito
その Pod 突然落ちても大丈夫ですか!?(OCHaCafe5 #5 実験!カオスエンジニアリング 発表資料)
by
NTT DATA Technology & Innovation
Docker Compose 徹底解説
by
Masahito Zembutsu
大規模データ活用向けストレージレイヤソフトのこれまでとこれから(NTTデータ テクノロジーカンファレンス 2019 講演資料、2019/09/05)
by
NTT DATA Technology & Innovation
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~(Kubernetes Meetup Tokyo #33 発表資料)
by
NTT DATA Technology & Innovation
Cisco Modeling Labs (CML)を使ってネットワークを学ぼう!(基礎編)配布用
by
シスコシステムズ合同会社
大量のデータ処理や分析に使えるOSS Apache Spark入門(Open Source Conference 2021 Online/Kyoto 発表資料)
by
NTT DATA Technology & Innovation
Java Clientで入門する Apache Kafka #jjug_ccc #ccc_e2
by
Yahoo!デベロッパーネットワーク
ストリーム処理を支えるキューイングシステムの選び方
by
Yoshiyasu SAEKI
Redisの特徴と活用方法について
by
Yuji Otani
【第26回Elasticsearch勉強会】Logstashとともに振り返る、やっちまった事例ごった煮
by
Hibino Hisashi
AWSにおけるバッチ処理の ベストプラクティス - Developers.IO Meetup 05
by
都元ダイスケ Miyamoto
そんなトランザクションマネージャで大丈夫か?
by
takezoe
今話題のいろいろなコンテナランタイムを比較してみた
by
Kohei Tokunaga
ストリーム処理プラットフォームにおけるKafka導入事例 #kafkajp
by
Yahoo!デベロッパーネットワーク
KafkaとAWS Kinesisの比較
by
Yoshiyasu SAEKI
NetflixにおけるPresto/Spark活用事例
by
Amazon Web Services Japan
Similar to Kafkaを活用するためのストリーム処理の基本
PDF
ストリーム処理はデータを失うから怖い?それ、何とかできますよ! 〜Apahe Kafkaを用いたストリーム処理における送達保証〜 (Open Source...
by
NTT DATA Technology & Innovation
PDF
Apache Kafkaによるログ転送とパフォーマンスチューニング - Bonfire Backend #2 -
by
Yahoo!デベロッパーネットワーク
PDF
20191120 AWS Black Belt Online Seminar Amazon Managed Streaming for Apache Ka...
by
Amazon Web Services Japan
PDF
Apache Kafkaでの大量データ処理がKubernetesで簡単にできて嬉しかった話
by
MicroAd, Inc.(Engineer)
PDF
[DI06] 並列分散処理の考え方とオープンソース分散処理系の動向
by
de:code 2017
PDF
Kafka Summit NYCに見るストリーミングデータETLの話 #streamdatajp
by
Yahoo!デベロッパーネットワーク
PDF
Reactive Kafka with Akka Streams
by
scalaconfjp
PDF
Kafka Streamsによるスケーラブルで非環境依存なストリーム/バッチ処理アーキテクチャ
by
Kazuki Ogiwara
PPTX
鹿駆動勉強会 青江発表資料
by
Takashi Aoe
PDF
2025/9/20 LT kintone Café 徳島 Vol.9 スダチの季節 - ストリーミングデータをKintoneで取り扱う
by
nakamuraryota582
PPTX
Spark Structured StreamingでKafkaクラスタのデータをお手軽活用
by
Sotaro Kimura
PDF
最近のストリーム処理事情振り返り
by
Sotaro Kimura
PDF
スキーマつきストリーム データ処理基盤、 Confluent Platformとは?
by
Sotaro Kimura
PPTX
Spark Structured Streaming with Kafka
by
Sotaro Kimura
PDF
[de:code 2017] 並列分散処理の考え方とオープンソース分散処理系の動向
by
Naoki (Neo) SATO
PPTX
Kafka integration with flume, hive and presto
by
Takafumi Saito
PDF
Akka stream
by
KasaiHaruki
ストリーム処理はデータを失うから怖い?それ、何とかできますよ! 〜Apahe Kafkaを用いたストリーム処理における送達保証〜 (Open Source...
by
NTT DATA Technology & Innovation
Apache Kafkaによるログ転送とパフォーマンスチューニング - Bonfire Backend #2 -
by
Yahoo!デベロッパーネットワーク
20191120 AWS Black Belt Online Seminar Amazon Managed Streaming for Apache Ka...
by
Amazon Web Services Japan
Apache Kafkaでの大量データ処理がKubernetesで簡単にできて嬉しかった話
by
MicroAd, Inc.(Engineer)
[DI06] 並列分散処理の考え方とオープンソース分散処理系の動向
by
de:code 2017
Kafka Summit NYCに見るストリーミングデータETLの話 #streamdatajp
by
Yahoo!デベロッパーネットワーク
Reactive Kafka with Akka Streams
by
scalaconfjp
Kafka Streamsによるスケーラブルで非環境依存なストリーム/バッチ処理アーキテクチャ
by
Kazuki Ogiwara
鹿駆動勉強会 青江発表資料
by
Takashi Aoe
2025/9/20 LT kintone Café 徳島 Vol.9 スダチの季節 - ストリーミングデータをKintoneで取り扱う
by
nakamuraryota582
Spark Structured StreamingでKafkaクラスタのデータをお手軽活用
by
Sotaro Kimura
最近のストリーム処理事情振り返り
by
Sotaro Kimura
スキーマつきストリーム データ処理基盤、 Confluent Platformとは?
by
Sotaro Kimura
Spark Structured Streaming with Kafka
by
Sotaro Kimura
[de:code 2017] 並列分散処理の考え方とオープンソース分散処理系の動向
by
Naoki (Neo) SATO
Kafka integration with flume, hive and presto
by
Takafumi Saito
Akka stream
by
KasaiHaruki
More from Sotaro Kimura
PPTX
Apache NiFiと 他プロダクトのつなぎ方
by
Sotaro Kimura
PPTX
JVM上でのストリーム処理エンジンの変遷
by
Sotaro Kimura
PPTX
スキーマ 付き 分散ストリーム処理 を実行可能な FlinkSQLClient の紹介
by
Sotaro Kimura
PDF
Stream dataprocessing101
by
Sotaro Kimura
PDF
利用者主体で行う分析のための分析基盤
by
Sotaro Kimura
PDF
Kinesis Analyticsの適用できない用途と、Kinesis Firehoseの苦労話
by
Sotaro Kimura
PDF
Gearpump, akka based Distributed Reactive Realtime Engine
by
Sotaro Kimura
PPTX
Modern stream processing by Spark Structured Streaming
by
Sotaro Kimura
PPTX
Custom management apps for Kafka
by
Sotaro Kimura
PDF
リアルタイム処理エンジン Gearpumpの紹介
by
Sotaro Kimura
PPTX
Hadoop基盤上のETL構築実践例 ~多様なデータをどう扱う?~
by
Sotaro Kimura
Apache NiFiと 他プロダクトのつなぎ方
by
Sotaro Kimura
JVM上でのストリーム処理エンジンの変遷
by
Sotaro Kimura
スキーマ 付き 分散ストリーム処理 を実行可能な FlinkSQLClient の紹介
by
Sotaro Kimura
Stream dataprocessing101
by
Sotaro Kimura
利用者主体で行う分析のための分析基盤
by
Sotaro Kimura
Kinesis Analyticsの適用できない用途と、Kinesis Firehoseの苦労話
by
Sotaro Kimura
Gearpump, akka based Distributed Reactive Realtime Engine
by
Sotaro Kimura
Modern stream processing by Spark Structured Streaming
by
Sotaro Kimura
Custom management apps for Kafka
by
Sotaro Kimura
リアルタイム処理エンジン Gearpumpの紹介
by
Sotaro Kimura
Hadoop基盤上のETL構築実践例 ~多様なデータをどう扱う?~
by
Sotaro Kimura
Recently uploaded
PPTX
【ASW22-01】STAMP:STPAロスシナリオの発想・整理支援ツールの開発 ~astah* System Safetyによる構造化・階層化機能の実装...
by
csgy24013
PDF
サーバーサイド Kotlin を社内で普及させてみた - Server-Side Kotlin Night 2025
by
Hirotaka Kawata
PDF
Kubernetes Release Team Release Signal Role について ~Kubernetes Meetup Tokyo #72~
by
Keisuke Ishigami
PDF
0.0001秒の攻防!?快適な運転を支えるリアルタイム制御と組み込みエンジニアの実践知【DENSO Tech Night 第四夜】
by
dots.
PPTX
「グローバルワン全員経営」の実践を通じて進化し続けるファーストリテイリングのアーキテクチャ
by
Fast Retailing Co., Ltd.
PDF
Rin Ukai_即興旅行の誘発を目的とした口コミ情報に基づく雰囲気キーワード_EC2025.pdf
by
Matsushita Laboratory
PDF
Nanami Doikawa_寄り道の誘発を目的とした旅行写真からのスポット印象語彙の推定に関する基礎検討_EC2025
by
Matsushita Laboratory
【ASW22-01】STAMP:STPAロスシナリオの発想・整理支援ツールの開発 ~astah* System Safetyによる構造化・階層化機能の実装...
by
csgy24013
サーバーサイド Kotlin を社内で普及させてみた - Server-Side Kotlin Night 2025
by
Hirotaka Kawata
Kubernetes Release Team Release Signal Role について ~Kubernetes Meetup Tokyo #72~
by
Keisuke Ishigami
0.0001秒の攻防!?快適な運転を支えるリアルタイム制御と組み込みエンジニアの実践知【DENSO Tech Night 第四夜】
by
dots.
「グローバルワン全員経営」の実践を通じて進化し続けるファーストリテイリングのアーキテクチャ
by
Fast Retailing Co., Ltd.
Rin Ukai_即興旅行の誘発を目的とした口コミ情報に基づく雰囲気キーワード_EC2025.pdf
by
Matsushita Laboratory
Nanami Doikawa_寄り道の誘発を目的とした旅行写真からのスポット印象語彙の推定に関する基礎検討_EC2025
by
Matsushita Laboratory
Kafkaを活用するためのストリーム処理の基本
1.
Kafkaを活用するための ストリーム処理の基本 2016/05/31 Apache Kafka
Meetup Japan #1 木村宗太郎(@kimutansk) https://www.flickr.com/photos/gruenewiese/13194312524
2.
自己紹介 • 木村 宗太郎(Sotaro
Kimura) • ビッグデータ界隈に生息する何でも屋 • バックエンドからフロントエンド、技術検証から運用、 ドキュメント書きまで色々 • Kafkaとの出会いは3年程前に Stormとの連携を試したのがキッカケ。 • だが、その後大規模なものをやる機会には恵まれず... • 自宅サーバには常に入っています。 • Twitter他 : @kimutansk 1
3.
アジェンダ 1. Kafkaのデータ活用モデル 2. ストリーム処理とは? 3.
ストリーム処理プロダクト概況 4. ストリーム処理で考えるべきこと 2
4.
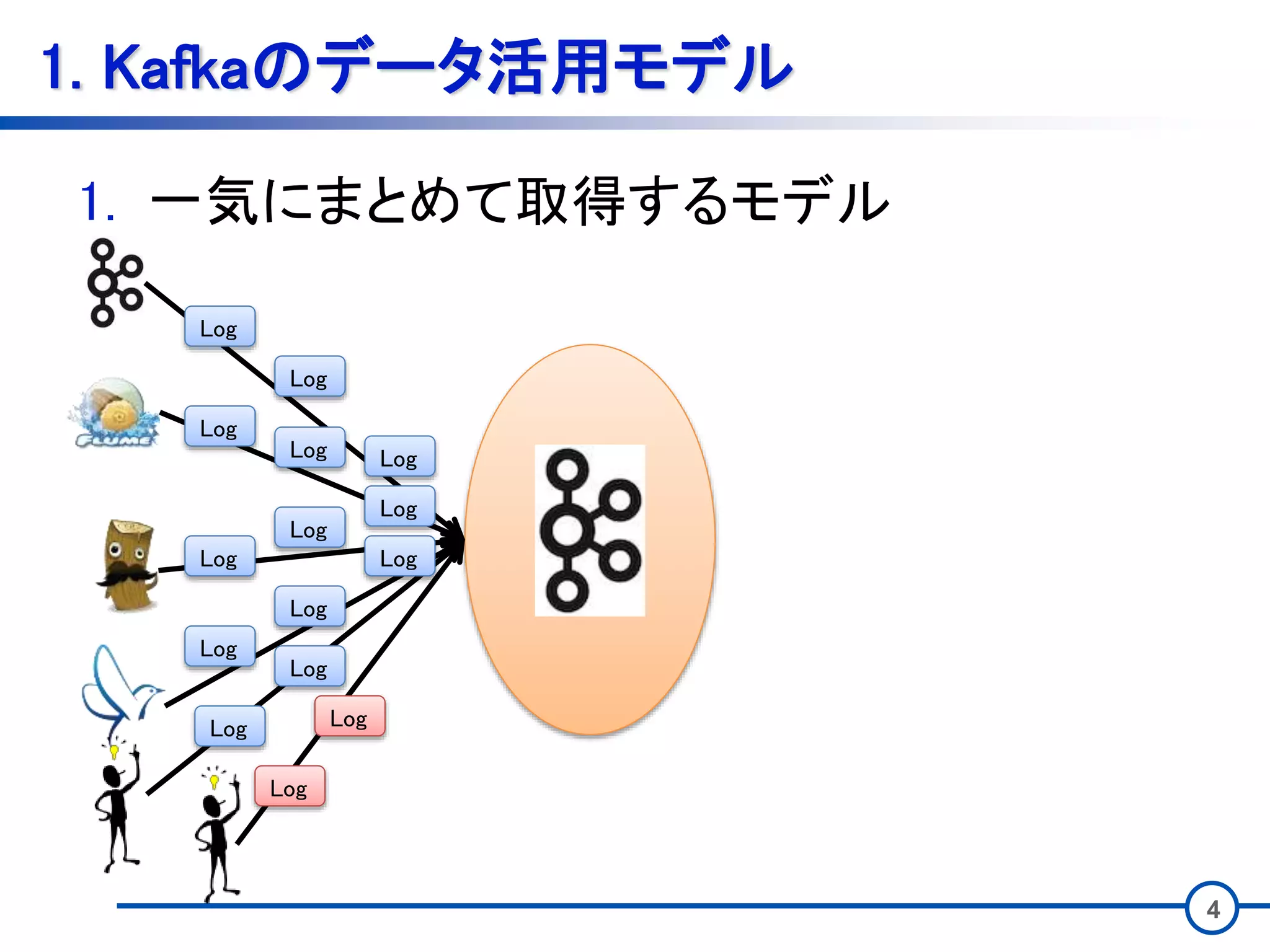
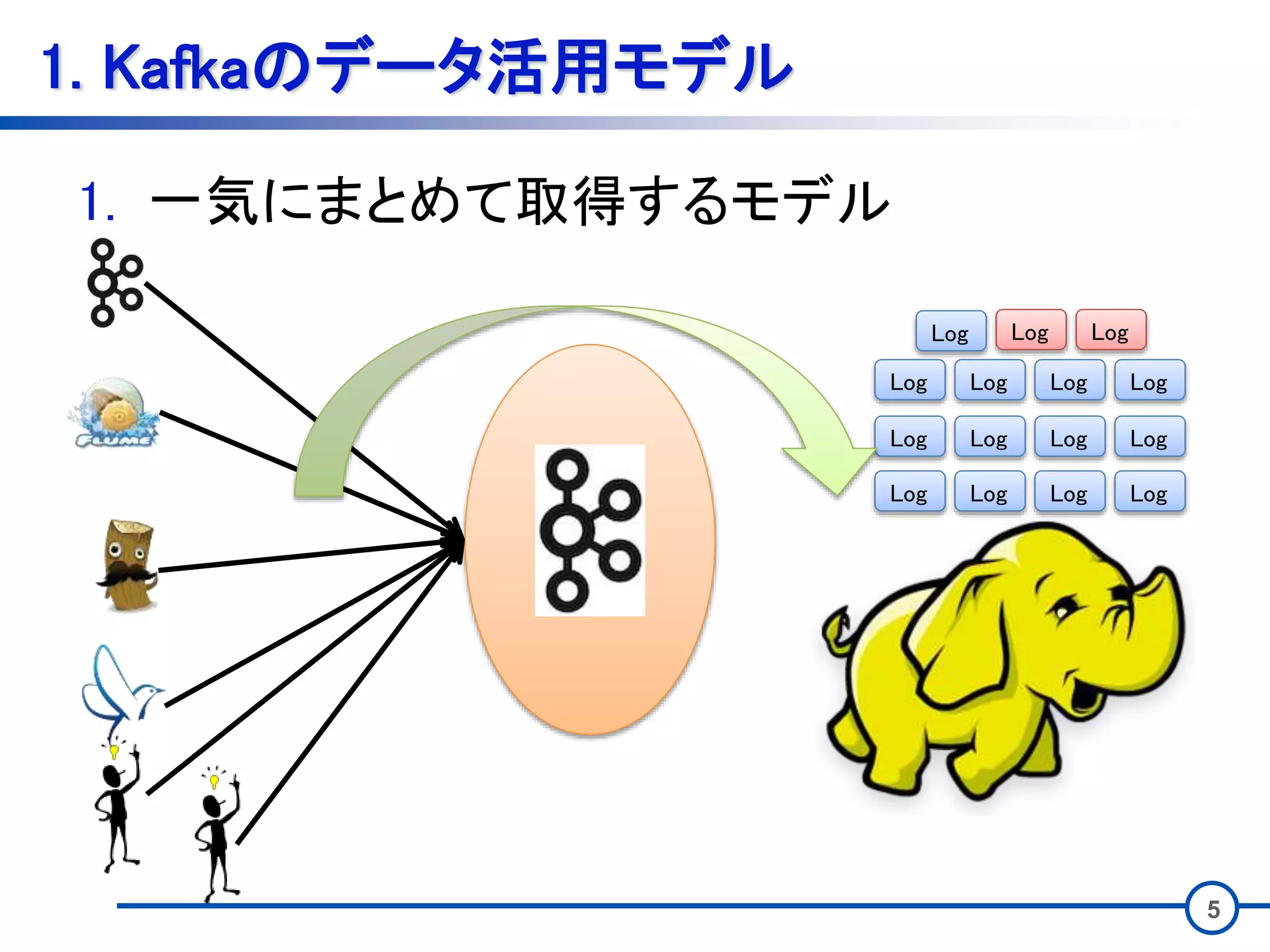
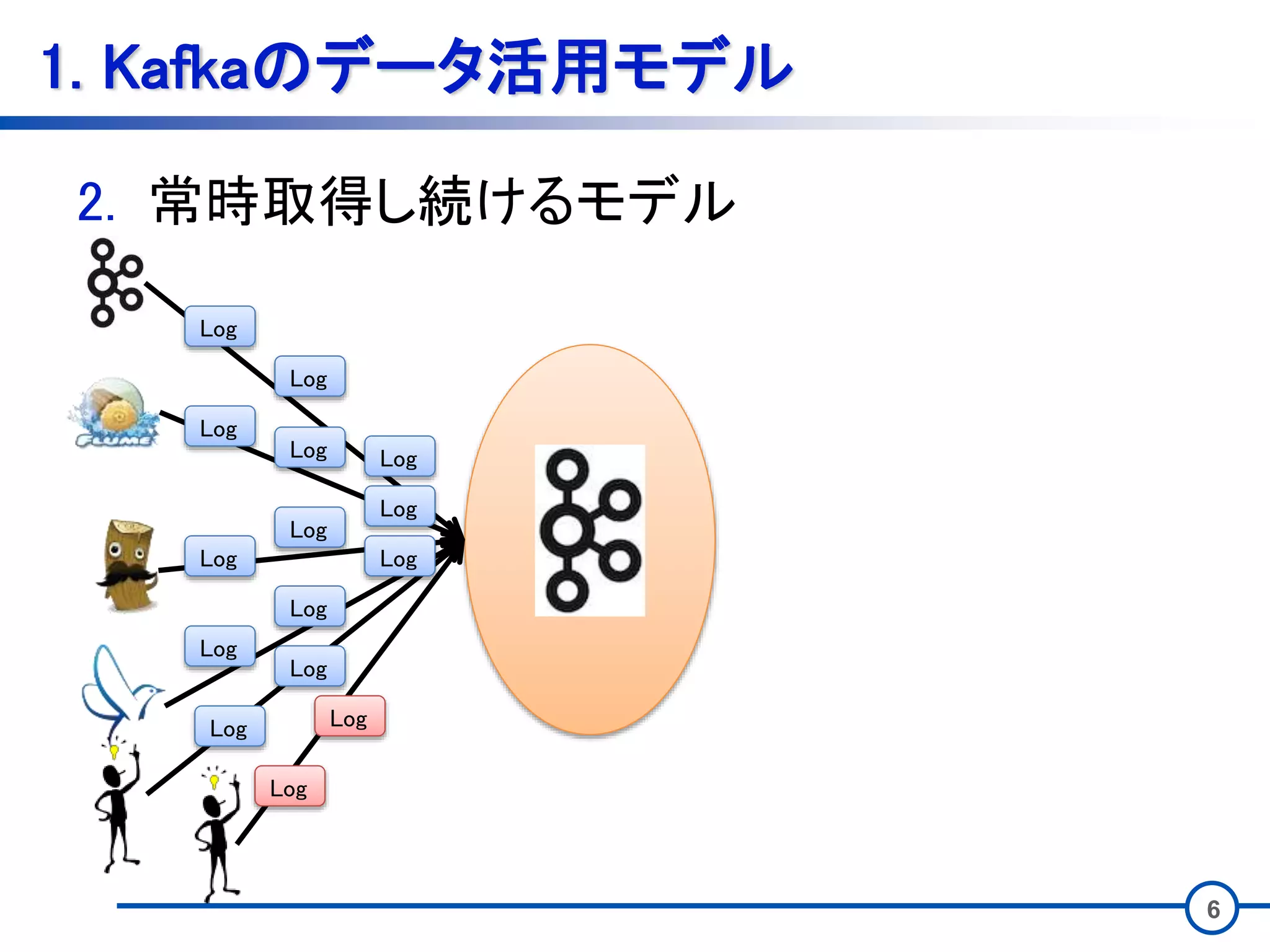
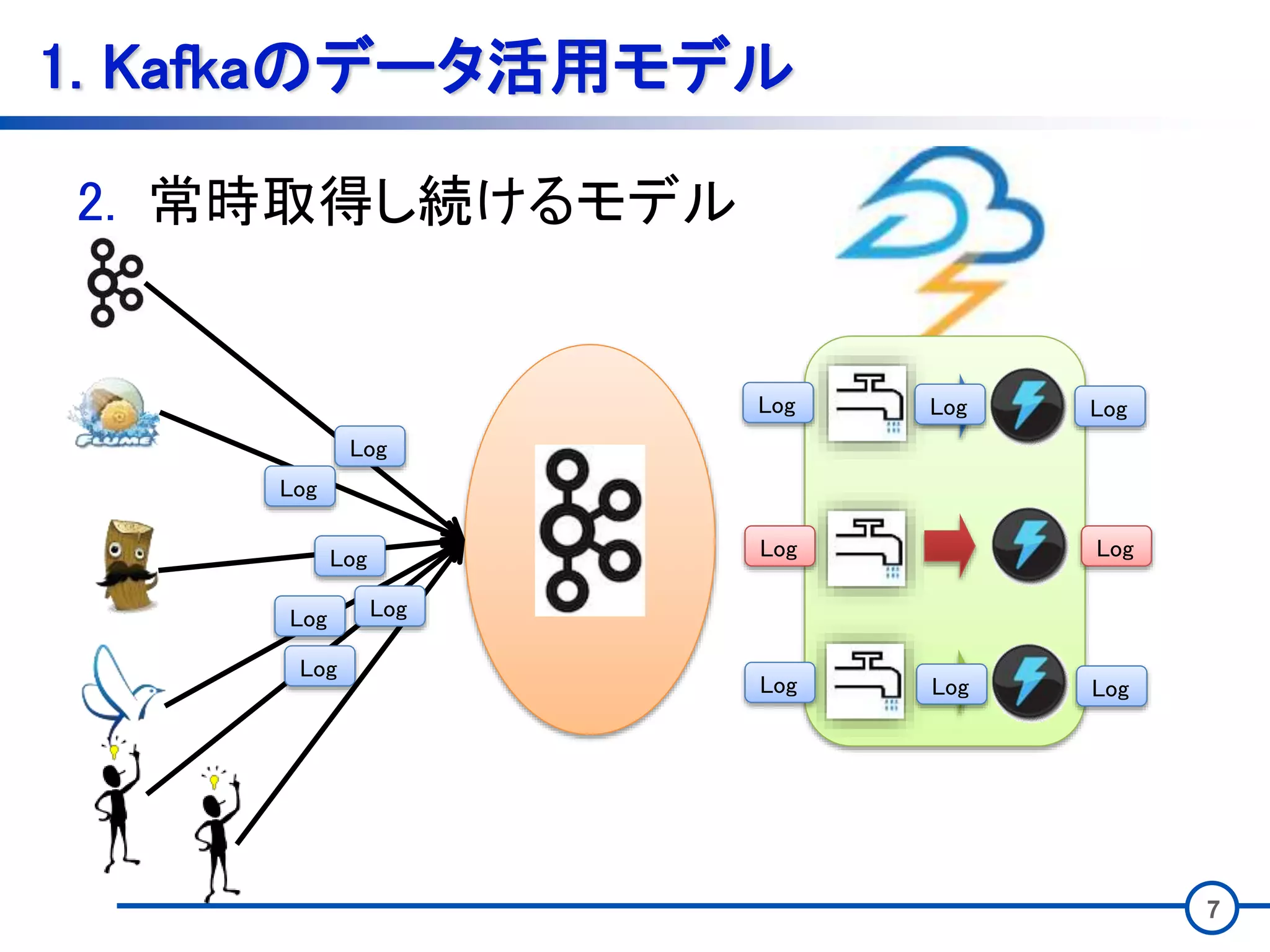
3 1. Kafkaのデータ活用モデル • Kafkaのデータの用い方は大きく2つある。 1.
一気にまとめて取得するモデル 2. 常時取得し続けるモデル
5.
4 1. Kafkaのデータ活用モデル 1. 一気にまとめて取得するモデル Log Log Log Log Log Log Log Log
Log Log Log Log Log Log Log
6.
5 1. Kafkaのデータ活用モデル 1. 一気にまとめて取得するモデル Log
LogLog Log Log Log Log Log LogLog Log Log LogLog Log
7.
6 1. Kafkaのデータ活用モデル 2. 常時取得し続けるモデル Log Log Log Log Log Log Log Log
Log Log Log Log Log Log Log
8.
7 1. Kafkaのデータ活用モデル 2. 常時取得し続けるモデル Log Log Log Log Log Log
Log Log Log Log Log LogLog Log
9.
8 2. ストリーム処理とは? バッチ処理 対話型クエリ
ストリーム処理 実行タイミング 手動起動 定期実行 手動起動 定期実行 常時実行 処理単位 保存済みデータを 一括処理 保存済みデータを 一括処理 1~少数の フローデータを処理 実行時間 分~時間 秒~分 永続実行 データサイズ TBs~PBs GBs~TBs Bs~KBs(1件あたり) 処理時間 分~時間 秒~分 ミリ秒~秒 主な用途 ETL ビジネスレポート生成 機械学習モデリング インタラクティブBI 分析 異常/不正検知 レコメンド 可視化 代表的 OSSプロダクト MapReduce Spark Tez Impala Drill Presto (後述) • ビッグデータの処理モデルは主に3つある。
10.
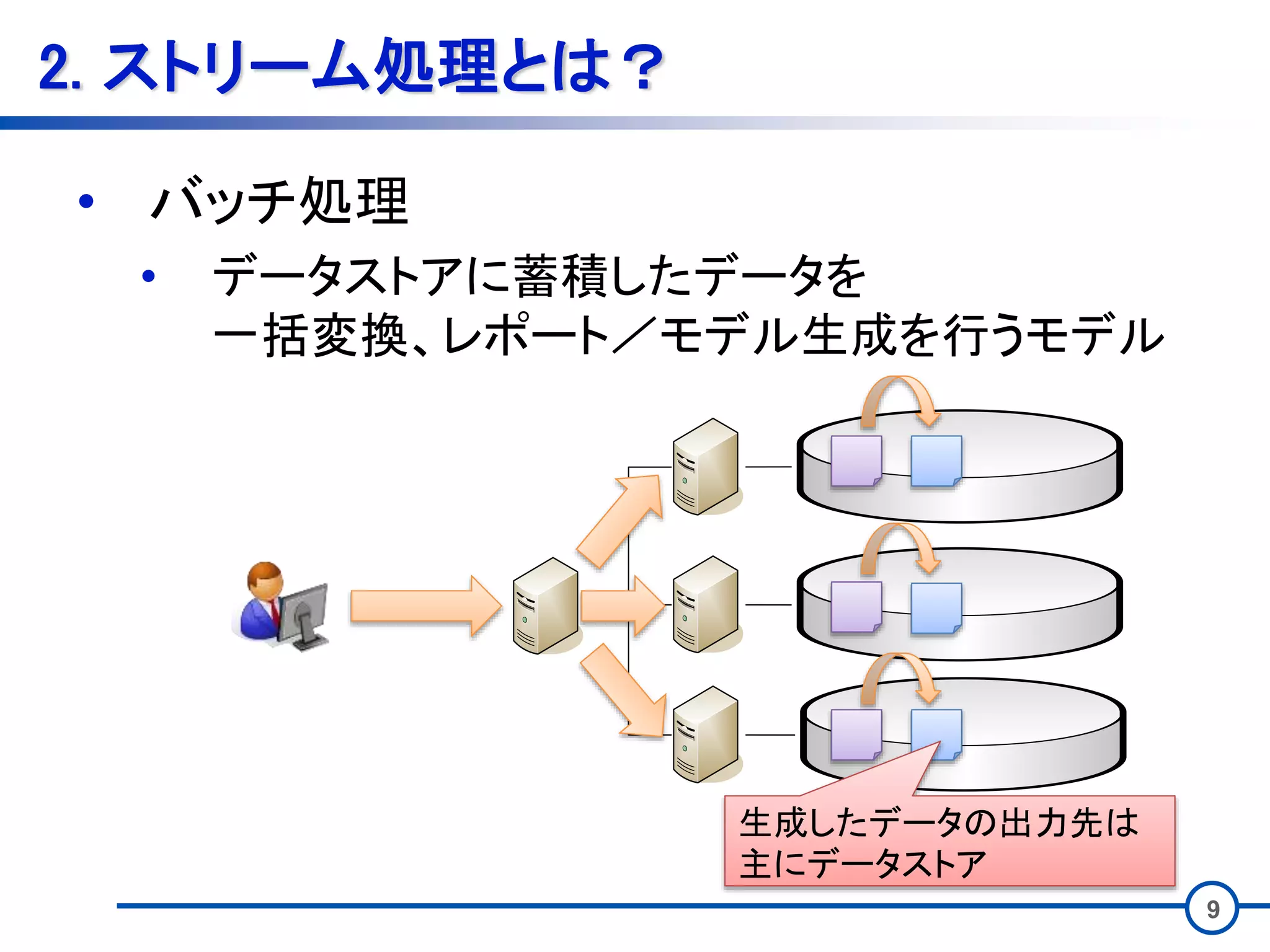
9 2. ストリーム処理とは? • バッチ処理 •
データストアに蓄積したデータを 一括変換、レポート/モデル生成を行うモデル 生成したデータの出力先は 主にデータストア
11.
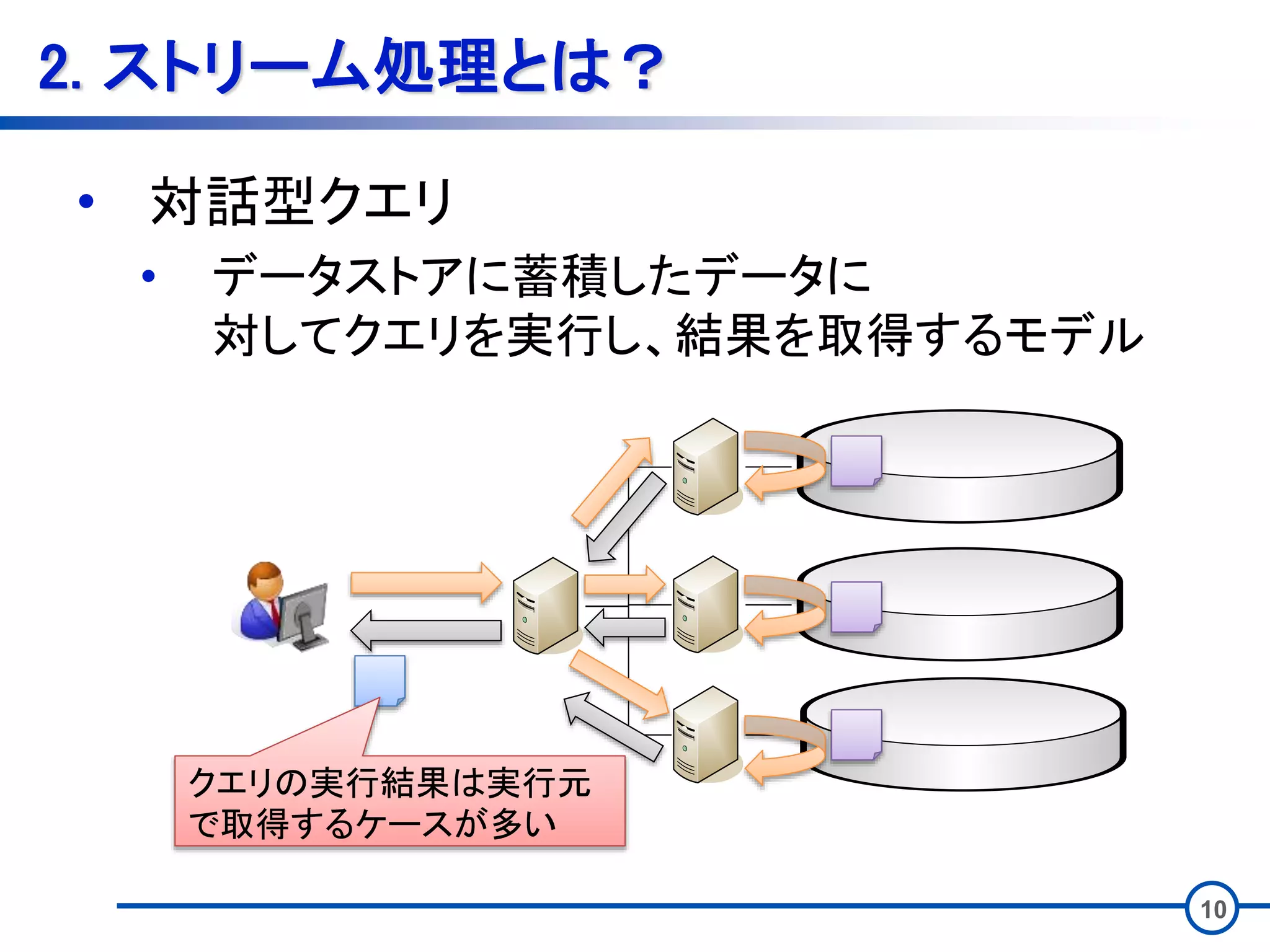
10 2. ストリーム処理とは? • 対話型クエリ •
データストアに蓄積したデータに 対してクエリを実行し、結果を取得するモデル クエリの実行結果は実行元 で取得するケースが多い
12.
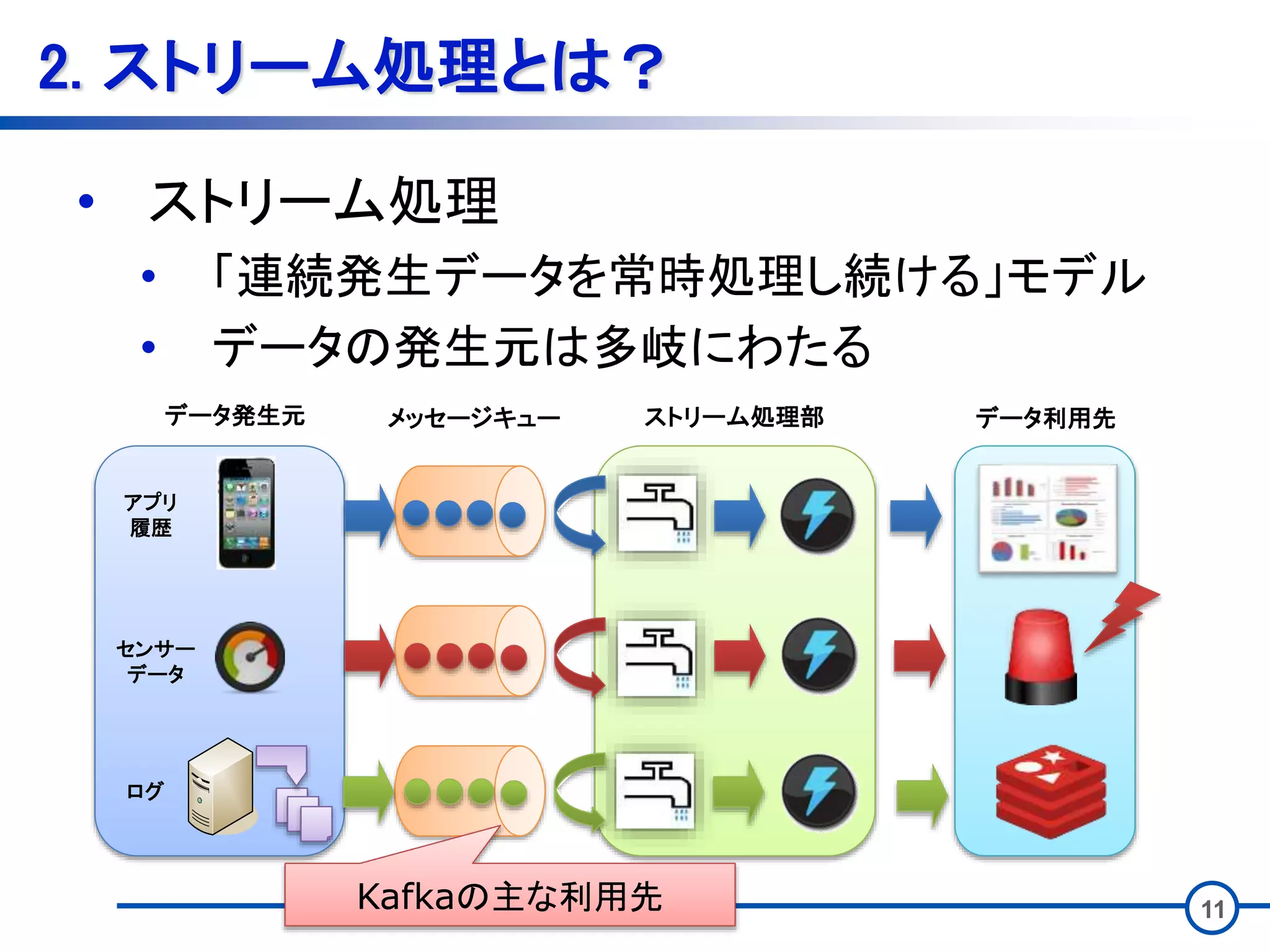
11 2. ストリーム処理とは? • ストリーム処理 •
「連続発生データを常時処理し続ける」モデル • データの発生元は多岐にわたる センサー データ ログ アプリ 履歴 データ発生元 メッセージキュー ストリーム処理部 データ利用先 Kafkaの主な利用先
13.
12 2. ストリーム処理とは? バッチ処理 対話型クエリ
ストリーム処理 実行タイミング 手動起動 定期実行 手動起動 定期実行 常時実行 処理単位 保存済みデータを 一括処理 保存済みデータを 一括処理 1~少数の フローデータを処理 実行時間 分~時間 秒~分 永続実行 データサイズ TBs~PBs GBs~TBs Bs~KBs(1件あたり) 処理時間 分~時間 秒~分 ミリ秒~秒 主な用途 ETL ビジネスレポート生成 機械学習モデリング インタラクティブBI 分析 異常/不正検知 レコメンド 可視化 代表的 OSSプロダクト MapReduce Spark Tez Impala Drill Presto (後述) • 今回の対象となるのは「ストリーム処理」
14.
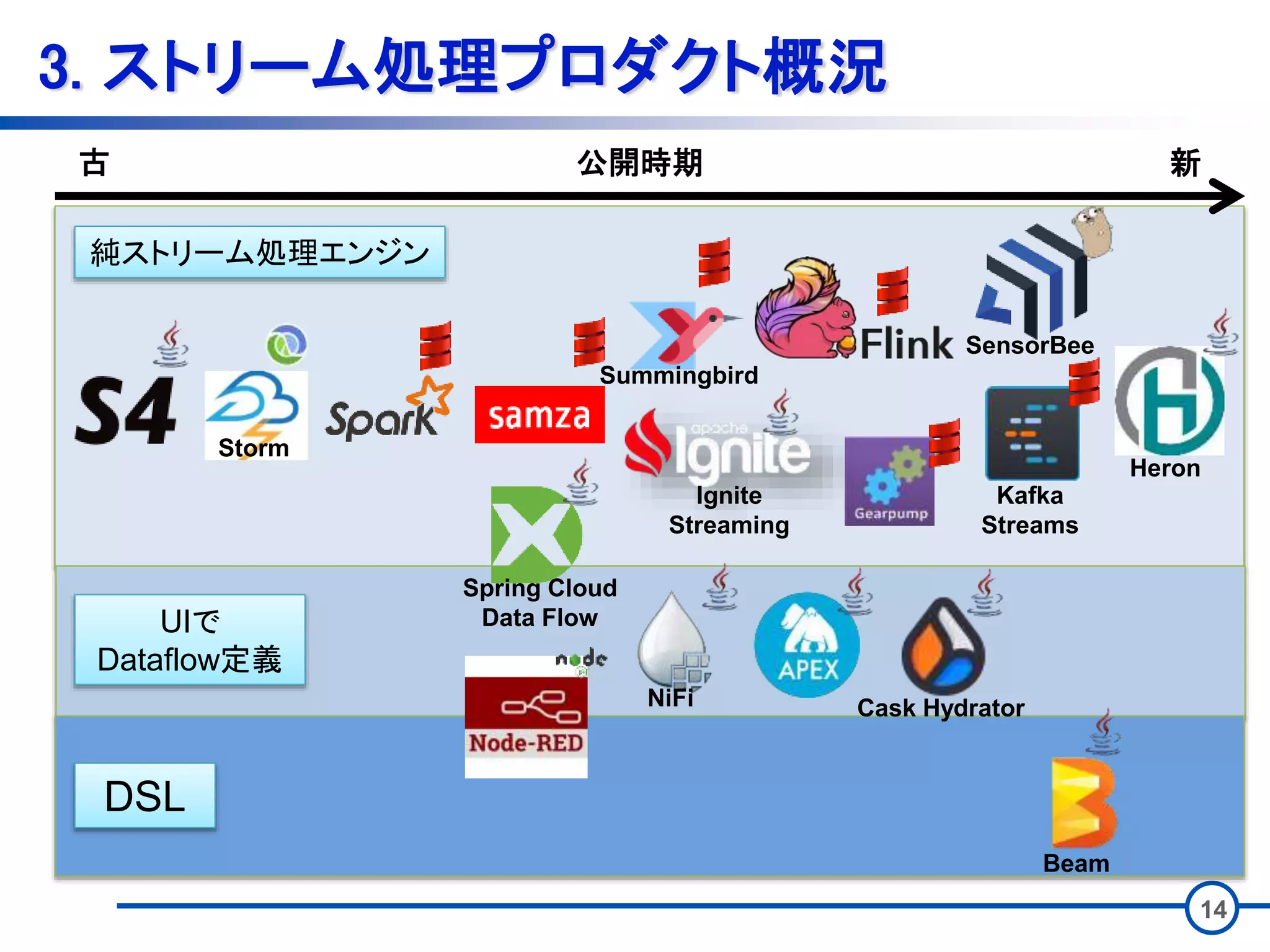
13 3. ストリーム処理プロダクト概況 • ストリーム処理を実現するプロダクトは多彩 •
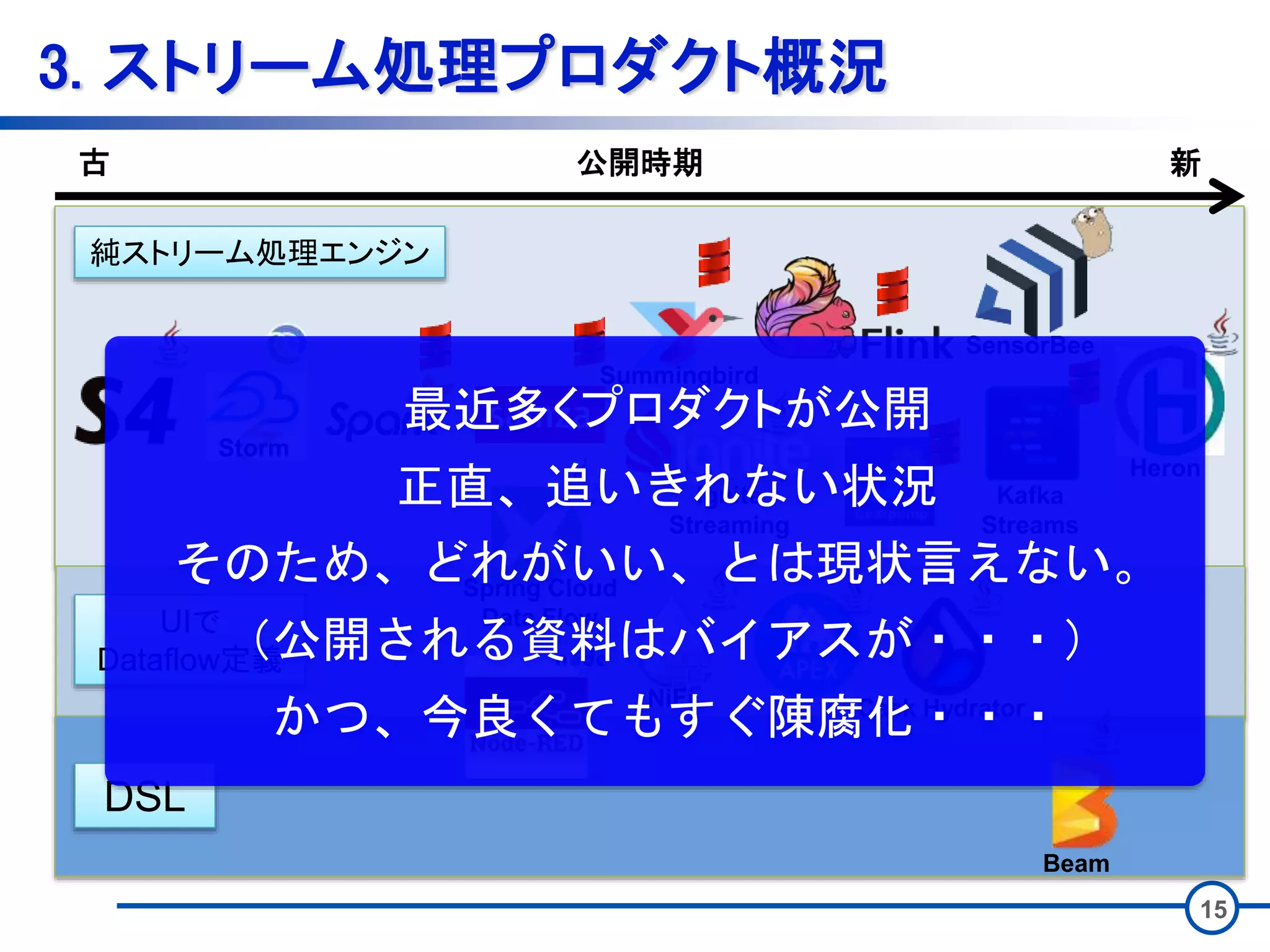
元は2011年のStorm公開を機に広く(?)発展 • 以降のプロダクトにいい意味でも悪い意味でも影響 • 最近多数のプロダクトが公開 • 下記のような派生パターン有 • UIでDataflow定義 • 処理を定義可能なUIを保持するパターン • DSL • 同一の記述で複数のストリーム処理エンジン上で アプリケーションが実行可能
15.
14 3. ストリーム処理プロダクト概況 古 新公開時期 DSL UIで Dataflow定義 純ストリーム処理エンジン Storm Summingbird NiFi Spring
Cloud Data Flow Cask Hydrator Beam Heron SensorBee Kafka Streams Ignite Streaming
16.
15 3. ストリーム処理プロダクト概況 古 新公開時期 DSL UIで Dataflow定義 純ストリーム処理エンジン Storm Summingbird NiFi Spring
Cloud Data Flow Cask Hydrator Beam Heron SensorBee Kafka Streams Ignite Streaming 最近多くプロダクトが公開 正直、追いきれない状況 そのため、どれがいい、とは現状言えない。 (公開される資料はバイアスが・・・) かつ、今良くてもすぐ陳腐化・・・
17.
4. ストリーム処理で考えるべきこと • ストリーム処理を構築する上で 考えるべきことについて説明します。 •
プロダクト選定時 • サービス開発時 • この項目自体も Storm、Spark Streamingから挙げたものです。 • もしFlink、Apex、Gearpump等他プロダクトの 経験者がいれば、是非とも補足を。 16
18.
4. ストリーム処理で考えるべきこと • プロダクト選定時に考えるべき主要観点 1.
実装言語は何か? → 未成熟なまま開発するため、解析必須 2. インストールの際に何が必要? → 各ホストにインストールするのは困難 3. サービス動作中にどこまで更新可能か? → 常時動作する関係上、止められないため。 4. 接続用コンポーネントが揃っているか? → Kafkaはほぼすべてのプロダクトと接続可能 そのため他コンポーネントの充実度が重要 17
19.
4. ストリーム処理で考えるべきこと • サービス開発時に考えるべき主要観点 1.
【必要な場合】Exactly Onceの実現方法 → データストアを用いて冪等性を実現 ストリーム処理単体では実現できない。 2. データがプロセスをまたがないように配置 → シリアライズの遅延も大きな影響になる。 3. 極力メモリ上に収めるか、並列度を調整 → 基本、ディスクに同期的に書かない。 4. ログを集約する機構を準備 → 分散処理ではないとまともに解析できない。 18
20.
まとめ • Kafkaの活用方法には大きく2モデルある 1. 一気にまとめて取得するモデル→バッチ処理 2.
常時取得し続けるモデル→ ストリーム処理 • ストリーム処理ベストプロダクトは選べない • プロダクトは異なっても共通点は多い 1. 性能特性/ボトルネックとなるポイント 2. データ設計 3. 解析を行うための準備 etc • 上記とプロダクト成熟度を踏まえ構築 19
21.
検討ポイント詳細はこちらの資料参照 20 http://www.slideshare.net/SotaroKimura/jvm-62243371
22.
Enjoy stream processing! and
share knowledge! https://www.flickr.com/photos/elf-8/15276069760
Download














































![[DI06] 並列分散処理の考え方とオープンソース分散処理系の動向](https://cdn.slidesharecdn.com/ss_thumbnails/di06-170605024555-thumbnail.jpg?width=640&height=640&fit=bounds)









![[de:code 2017] 並列分散処理の考え方とオープンソース分散処理系の動向](https://cdn.slidesharecdn.com/ss_thumbnails/20170524decode17di06hdinsight-170702125017-thumbnail.jpg?width=640&height=640&fit=bounds)



















