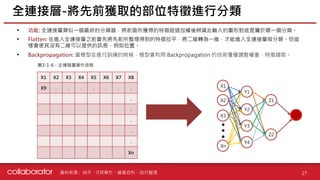
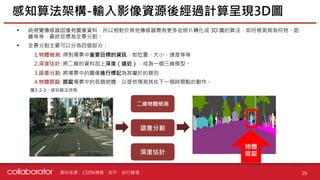
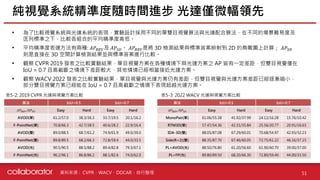
資料來源 :
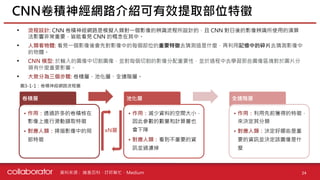
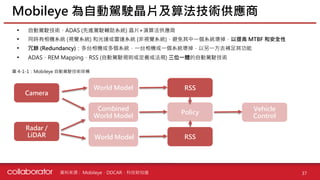
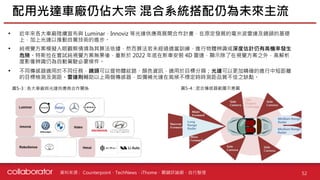
• 傳統的感測系統同時使用相機、雷達和光達會造成資料衝突的問題
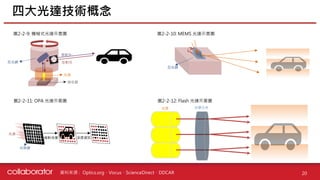
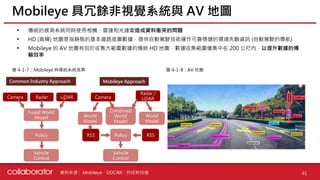
•HD (高精) 地圖是指靜態的基本道路底圖數據,提供自動駕駛技術運作可靠穩健的環境先驗資訊 (自動駕駛的導航)
• Mobileye 的 AV 地圖有別於收集大範圍數據的傳統 HD 地圖,數據收集範圍僅集中在 200 公尺內,以提升數據的傳
輸效率
Mobileye 具冗餘非視覺系統與 AV 地圖
41
圖 4-1-7:Mobileye 與傳統系統差異 圖 4-1-8:AV 地圖
Mobileye、DDCAR、科技財知道
Camera Radar LiDAR
Fused World
Model
Policy
Vehicle
Control
Camera
Radar /
LiDAR
World
Model
RSS
Combined
World
Model
World
Model
RSS
Policy
Vehicle
Control
Mobileye Approach
Common Industry Approach







































































![[IEK] 2023-04 物聯網產業趨勢分享.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/iek2023-04-230828073738-e8944e9b-thumbnail.jpg?width=640&height=640&fit=bounds)

























