Download as PDF, PPTX






![II.3 Cass (Abney 1990,1995)
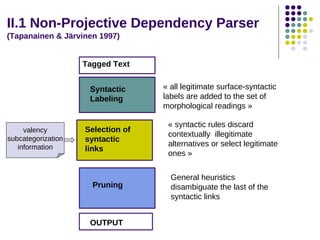
Tagged Text
CHUNK FILTER
NP filter
Chunk filter
CLAUSE FILTER
Raw Clause filter
Non recursive chunks
Internal structure remains ambiguous
[NP the happy tree friends]
[VP will leave]
[SP from [NP the happy tree friends]
Subject-predicate relation
Beginning and end of simplex clauses
[SUBJThis] [PREDis] [NPthe man][SPfrom Paris]
Clause Repair filter
subcategorization
information
PARSE FILTER
OUTPUT
Repair if no Subject-predicate relation
Assembles recursive structures
[[This] [is] [NPthe man][SPfrom Paris] ]](https://image.slidesharecdn.com/robust-rule-based-parsing-131201185814-phpapp01/85/Robust-rule-based-parsing-8-320.jpg)

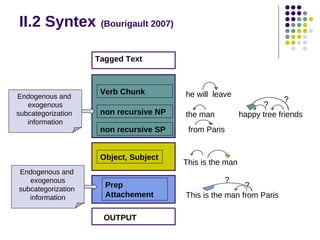
![II.3 Cass (Abney 1990,1995)
Example of repair
In South Australia beds of boulders were deposited …
Erroneous structure output from the Chunk filter
[SPIn [NPSouth Australia beds]][SPof [NPboulders]][VPwere
deposited]
Raw Clause filter : no subject is found
Repair filter tries to find a subject by modifying the structure
[SPIn [NPSouth Australia beds]][SPof [SPof boulders][VPwere
Australia]][NP-SUBJbeds][ NPboulders]][VPwere
deposited]](https://image.slidesharecdn.com/robust-rule-based-parsing-131201185814-phpapp01/85/Robust-rule-based-parsing-10-320.jpg)




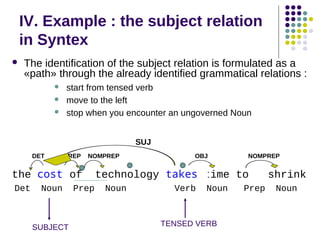



![IV. Path Example : following up
SUBJ
Korea who we believe to have WMD is safe from us.
Clause
PP
PP module
Clause module
_ RelPron [[SUJPron] Verb ]](https://image.slidesharecdn.com/robust-rule-based-parsing-131201185814-phpapp01/85/Robust-rule-based-parsing-19-320.jpg)
![IV. Path example : repair
OBJ
SUBJ
Many adults believe education equates intelligence.
Clause
Clause module
## [[SUBJNP] Verb [[OBJ [SUBJNP] Verb ]
Verb
OBJNP]]](https://image.slidesharecdn.com/robust-rule-based-parsing-131201185814-phpapp01/85/Robust-rule-based-parsing-20-320.jpg)
![IV. Path example : sub-module call
SUBJ
On the walls were scarlett banners
PP
PP module
Wall module
## [PP] Verb
NP
InvertedSubject
module
_](https://image.slidesharecdn.com/robust-rule-based-parsing-131201185814-phpapp01/85/Robust-rule-based-parsing-21-320.jpg)
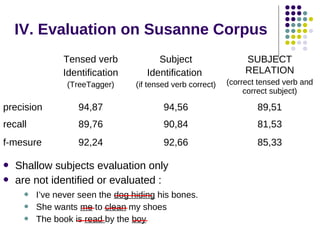


The document provides an overview of robust rule-based parsers for English, highlighting their common features such as incrementality, determinism, and repair mechanisms. It discusses different types of parsers, including non-projective dependency parsers, Syntex, and Cass, illustrating how they process input and handle ambiguity through established syntactic links and repair strategies. The document also underscores the challenges in automatic syntactic analysis and the need for a blend of linguistic and programming expertise in developing scalable and robust parsing systems.




















































































