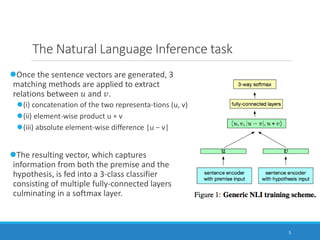
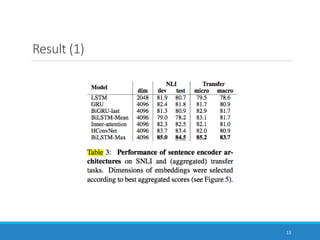
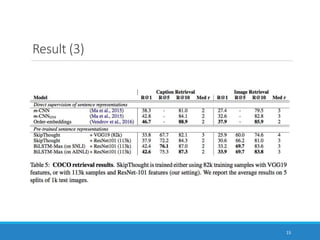
This document summarizes the paper "Supervised Learning of Universal Sentence Representations from Natural Language Inference Data". It discusses how the researchers trained sentence embeddings using supervised data from the Stanford Natural Language Inference dataset. They tested several sentence encoder architectures and found that a BiLSTM network with max pooling produced the best performing universal sentence representations, outperforming prior unsupervised methods on 12 transfer tasks. The sentence representations learned from the natural language inference data consistently achieved state-of-the-art performance across multiple downstream tasks.








![9
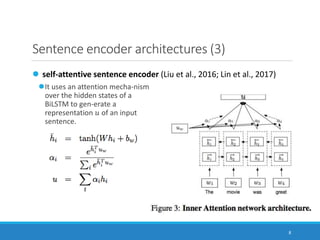
Sentence encoder architectures (4)
Hierarchical ConvNet
It is like AdaSent (Zhao et al., 2015).
The final representation 𝑢 =
[𝑢1, 𝑢2, 𝑢3, 𝑢4] concatenates
representations at different levels of
the input sentence.](https://image.slidesharecdn.com/paperreadingmt-supervisedlearningofuniversalsentencerepresentationsfromnaturallanguageinferencedata-171216153412/85/Paper-Reading-Supervised-Learning-of-Universal-Sentence-Representations-from-Natural-Language-Inference-Data-10-320.jpg)






























![[Paper Reading] Unsupervised Learning of Sentence Embeddings using Compositi...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreadingnaacl-unsupervisedlearningofsentenceembeddingsusingcompositionaln-gramfeatures-181121025013-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[Tutorial] Sentence Representation](https://cdn.slidesharecdn.com/ss_thumbnails/tutorialsentencerepresentation-181121030653-thumbnail.jpg?width=640&height=640&fit=bounds)
![[論文紹介] Reference Bias in Monolingual Machine Translation Evaluation](https://cdn.slidesharecdn.com/ss_thumbnails/paperreadingacl2016-referencebiasinmonolingualmachinetranslationevaluation-181121025921-thumbnail.jpg?width=640&height=640&fit=bounds)
![[論文紹介] ReVal: A Simple and Effective Machine Translation Evaluation Metric Ba...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreadingemnlp-reval-asimpleandeffectivemachinetranslationevaluationmetricbasedonrecurrentneuraln-181121025804-thumbnail.jpg?width=640&height=640&fit=bounds)
![[論文紹介] PARANMT-50M- Pushing the Limits of Paraphrastic Sentence Embeddings wi...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreadingother-paranmt-50m-pushingthelimitsofparaphrasticsentenceembeddingswithmillionsofmachinet-181121011322-thumbnail.jpg?width=640&height=640&fit=bounds)
![[論文紹介] AN EFFICIENT FRAMEWORK FOR LEARNING SENTENCE REPRESENTATIONS.](https://cdn.slidesharecdn.com/ss_thumbnails/paperreadingcurrent-anefficientframeworkforlearningsentencerepresentations-181121005425-thumbnail.jpg?width=640&height=640&fit=bounds)
![[論文紹介] Are BLEU and Meaning Representation in Opposition?](https://cdn.slidesharecdn.com/ss_thumbnails/paperreadingacl2018-arebleuandmeaningrepresentationinopposition-181121001139-thumbnail.jpg?width=640&height=640&fit=bounds)
![[論文紹介] Skip-Thought Vectors](https://cdn.slidesharecdn.com/ss_thumbnails/paperreading-180710080615-thumbnail.jpg?width=640&height=640&fit=bounds)





![ANIMAL_CELL_,_TISSUE_AND_ORGAN_CULTURE[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/animalcelltissueandorganculture1-260204172026-4462b440-thumbnail.jpg?width=640&height=640&fit=bounds)













