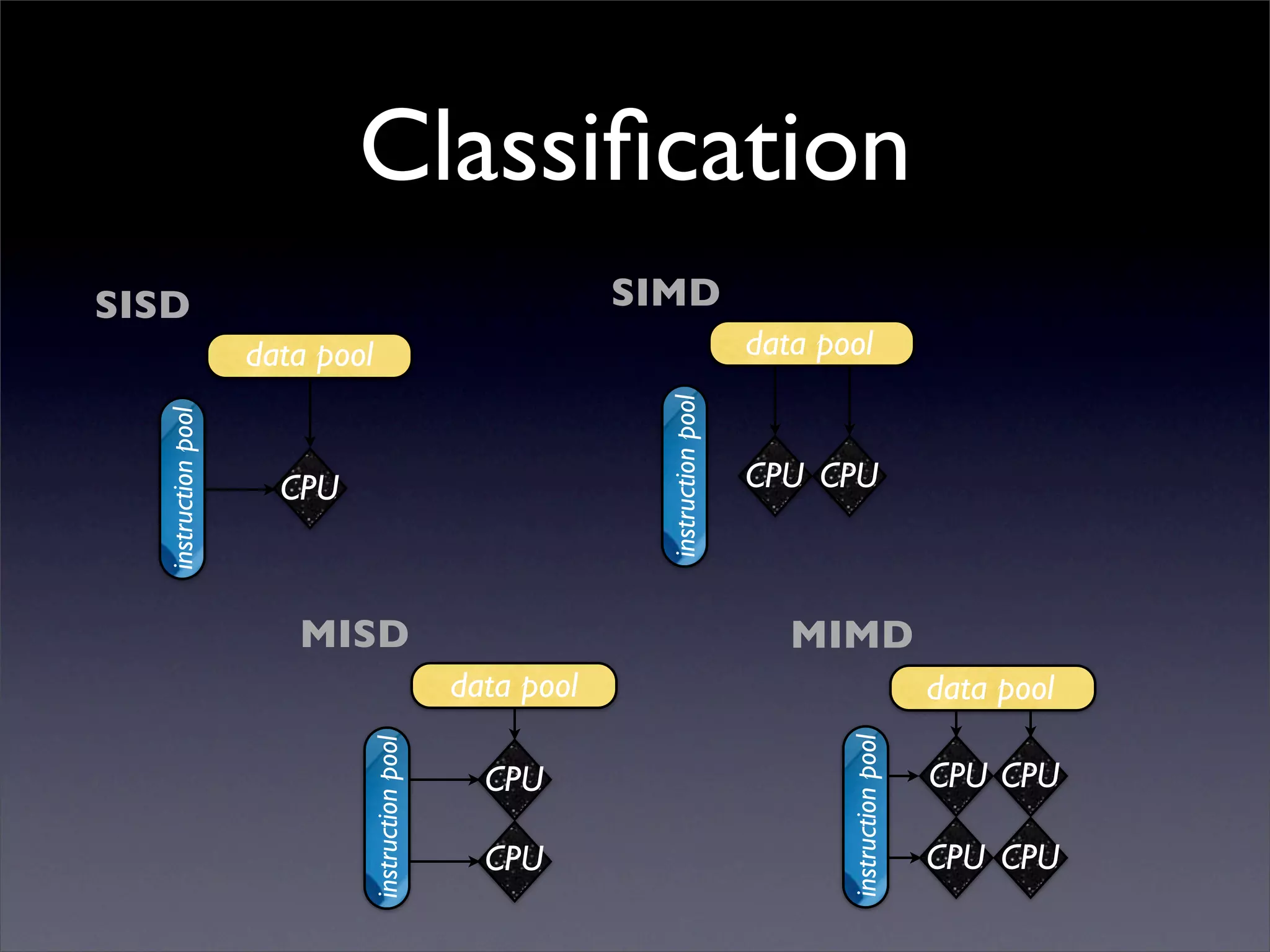
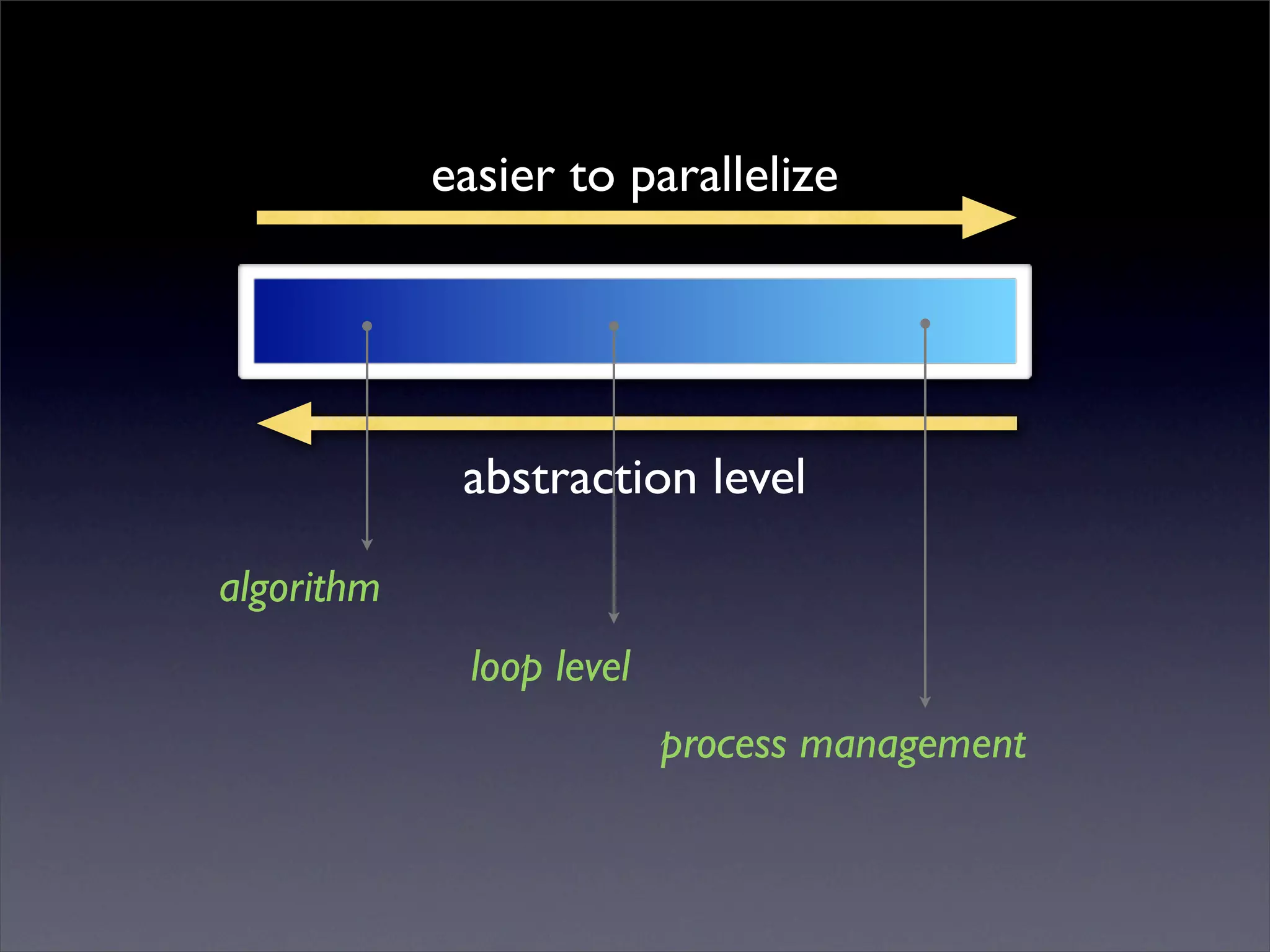
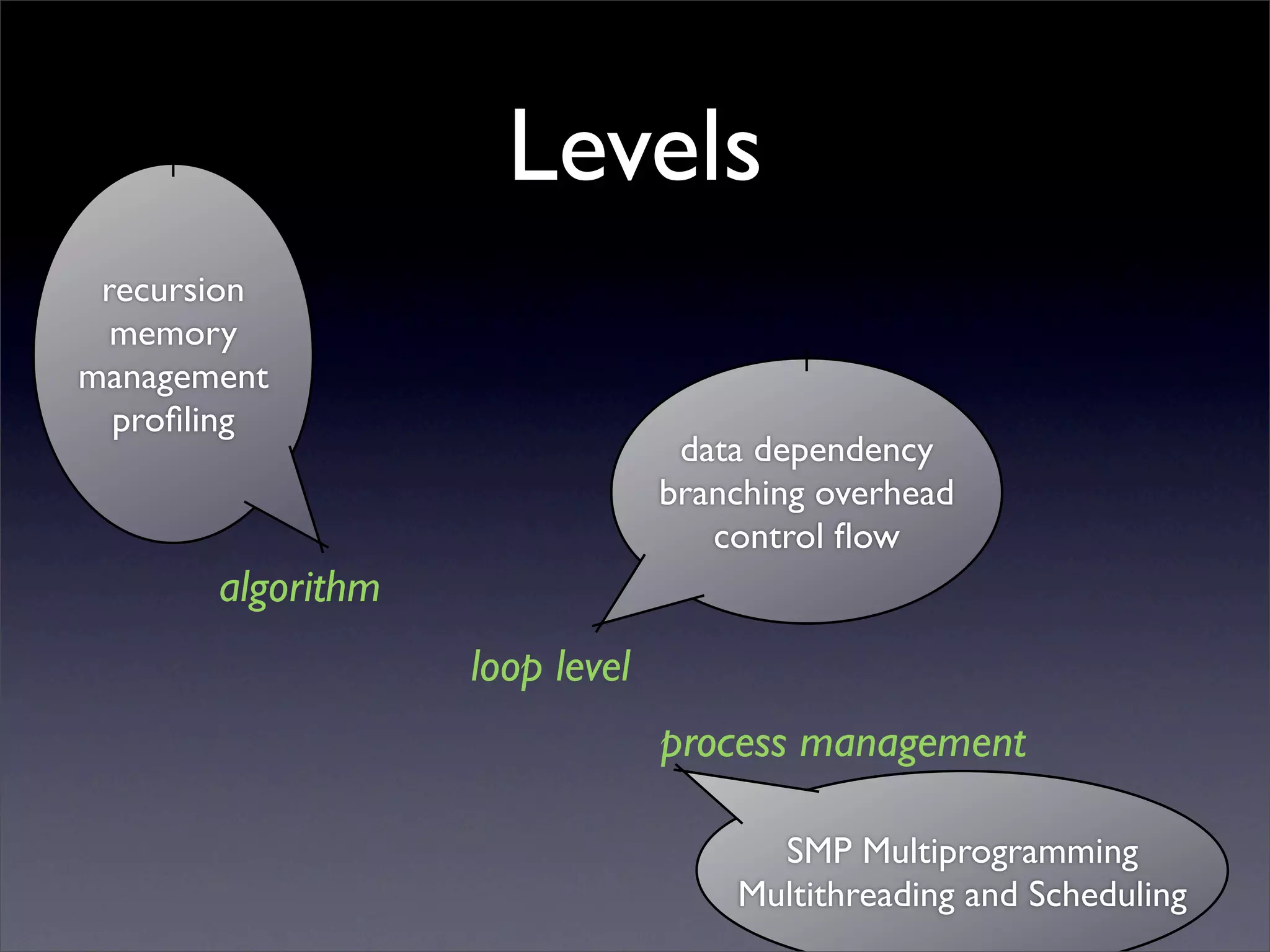
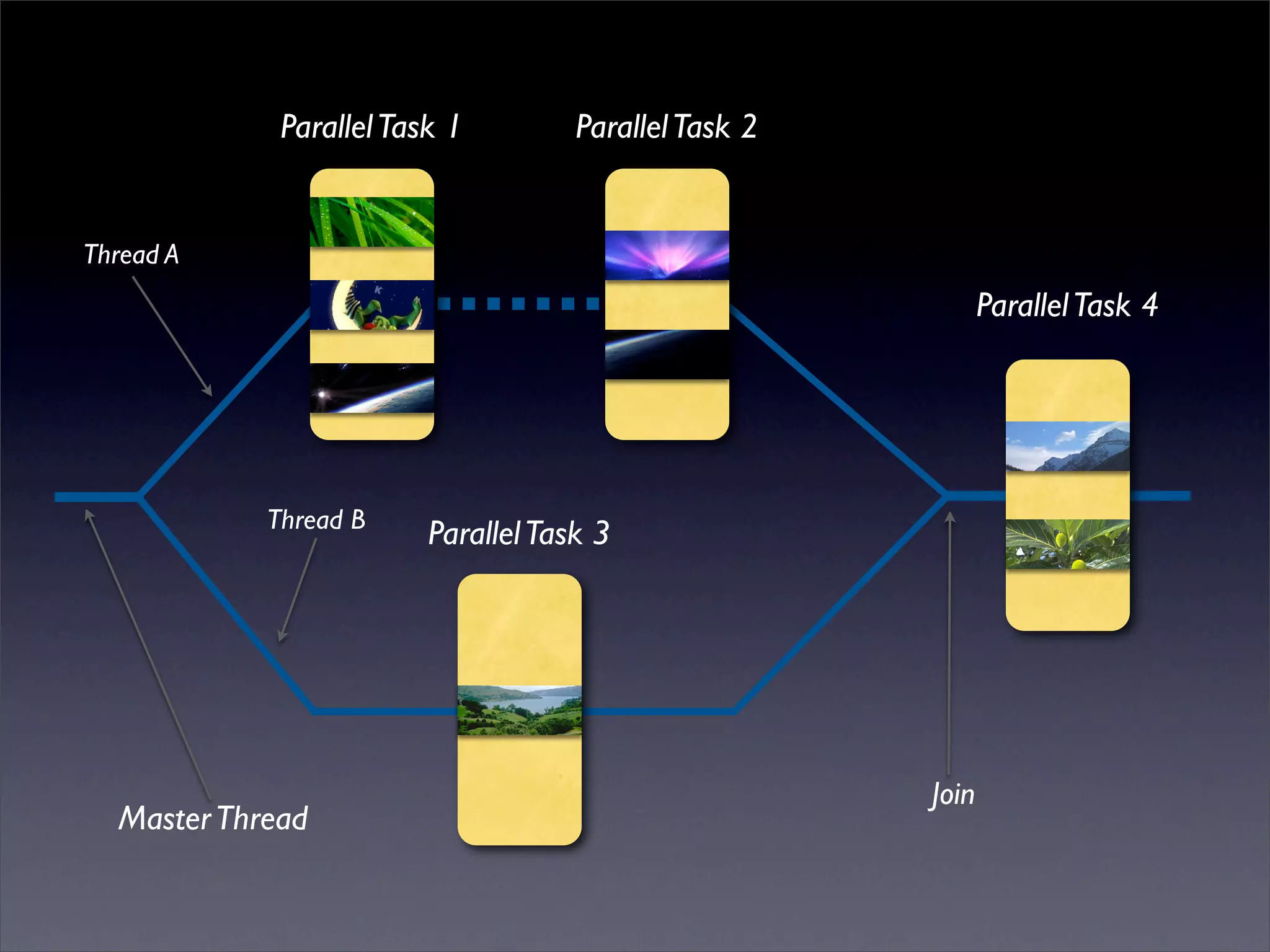
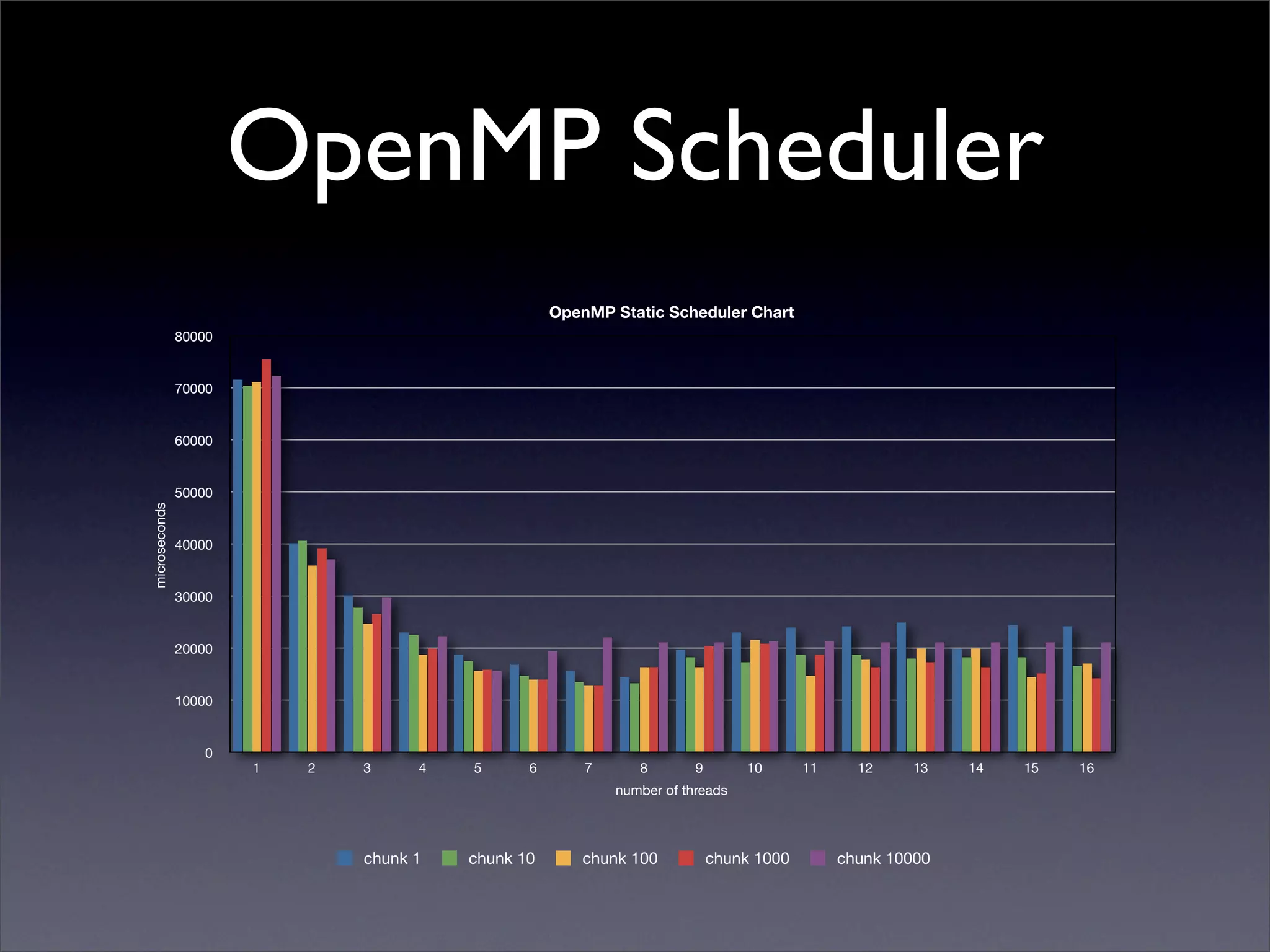
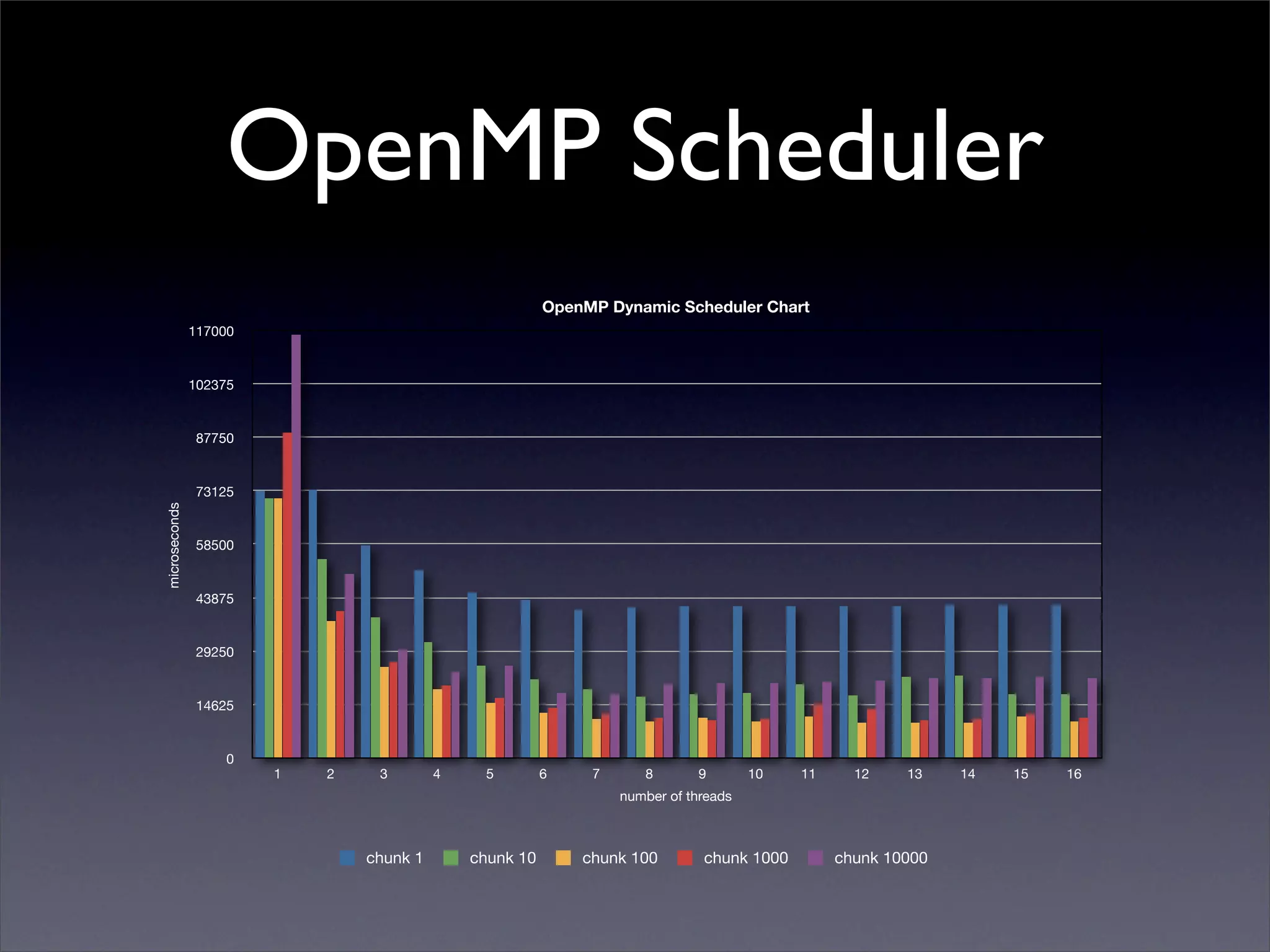
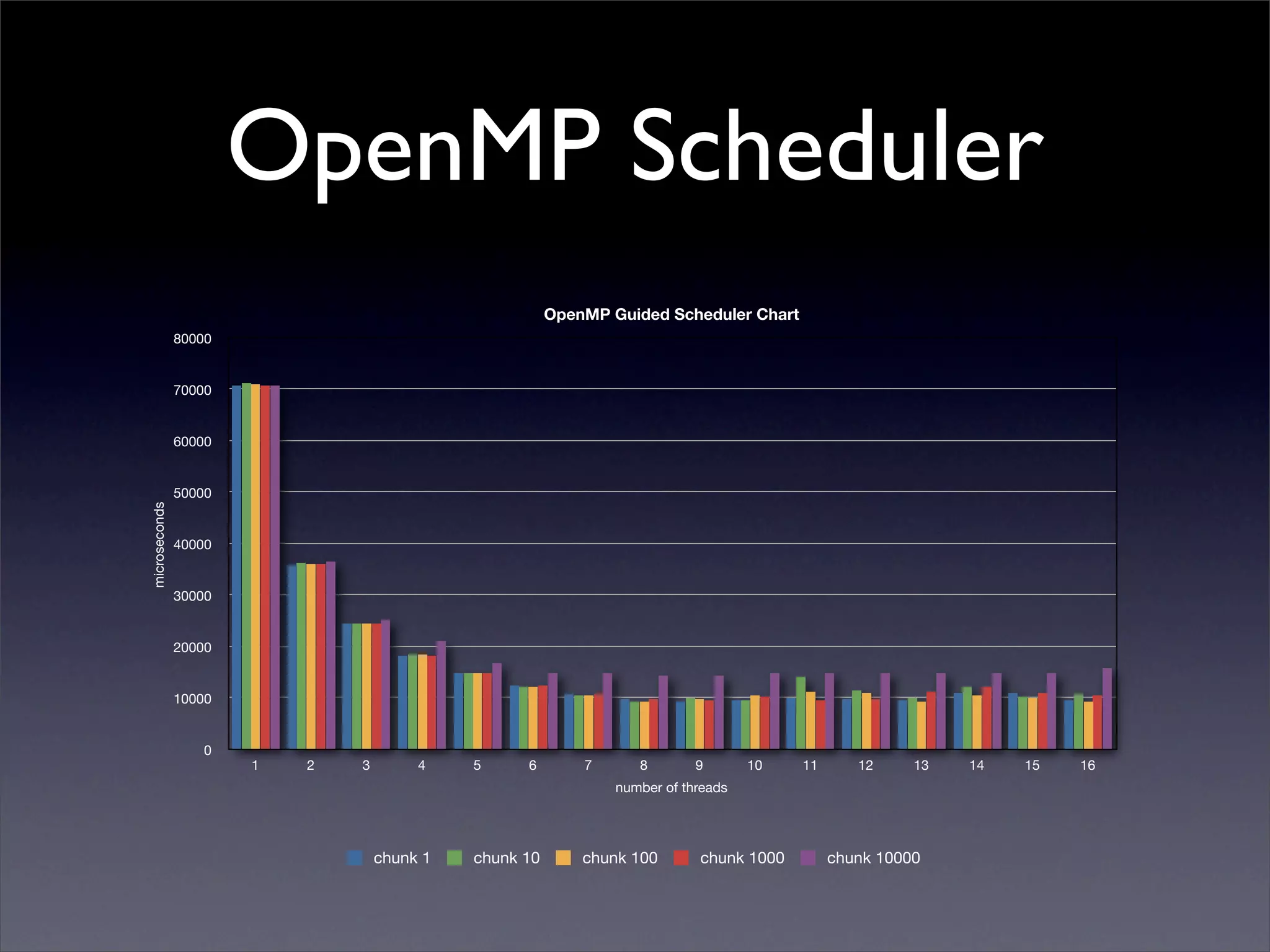
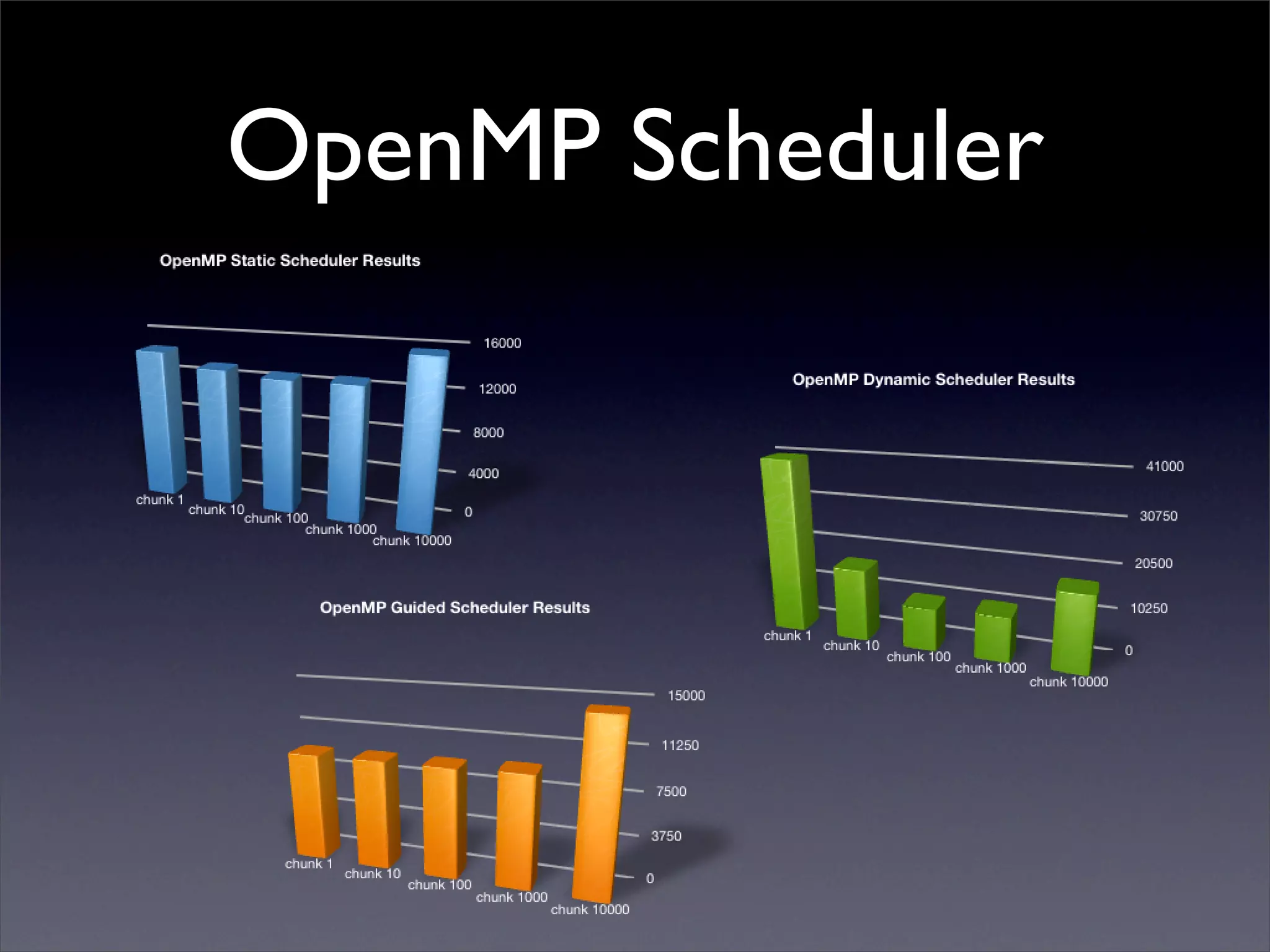
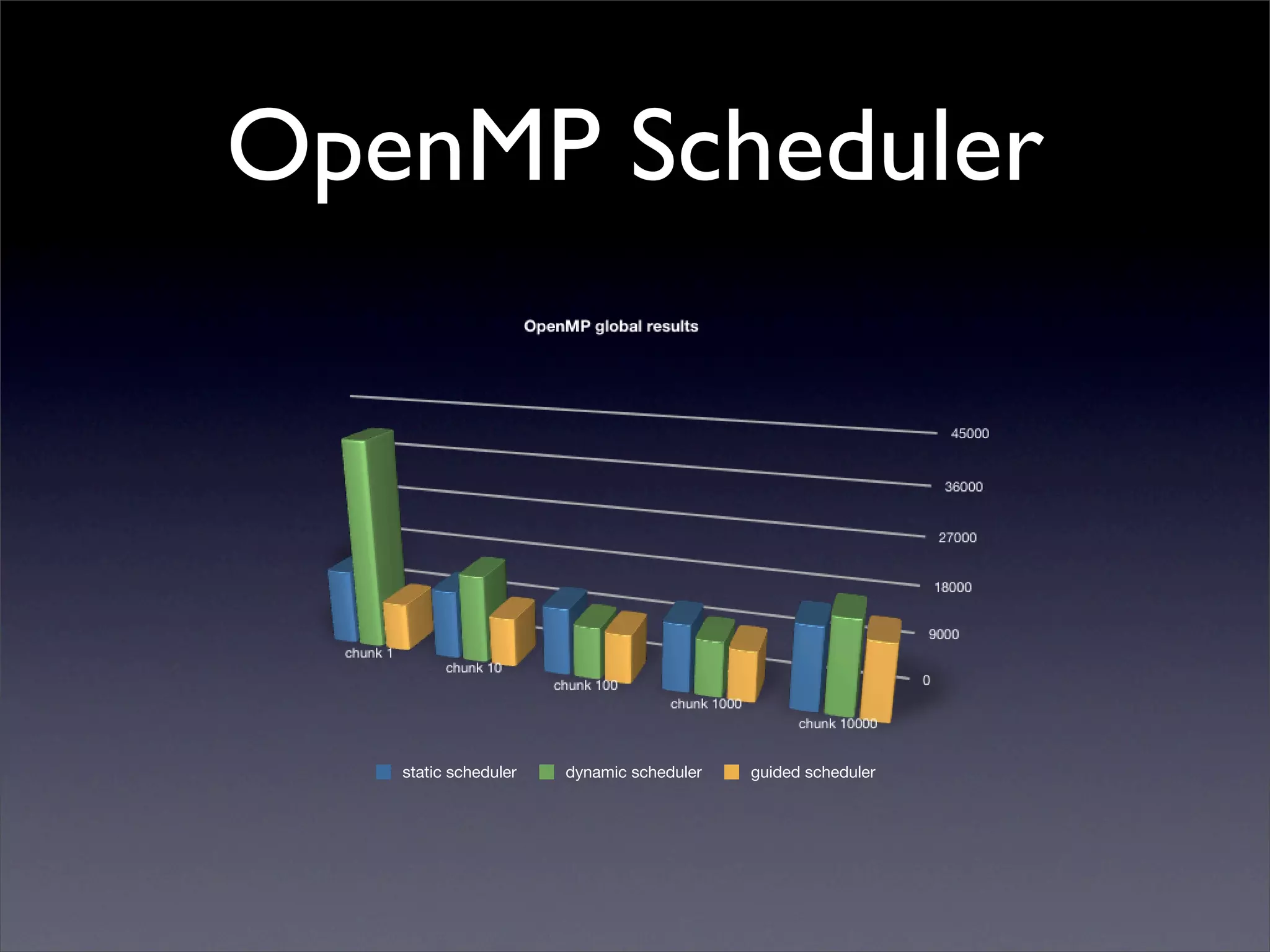
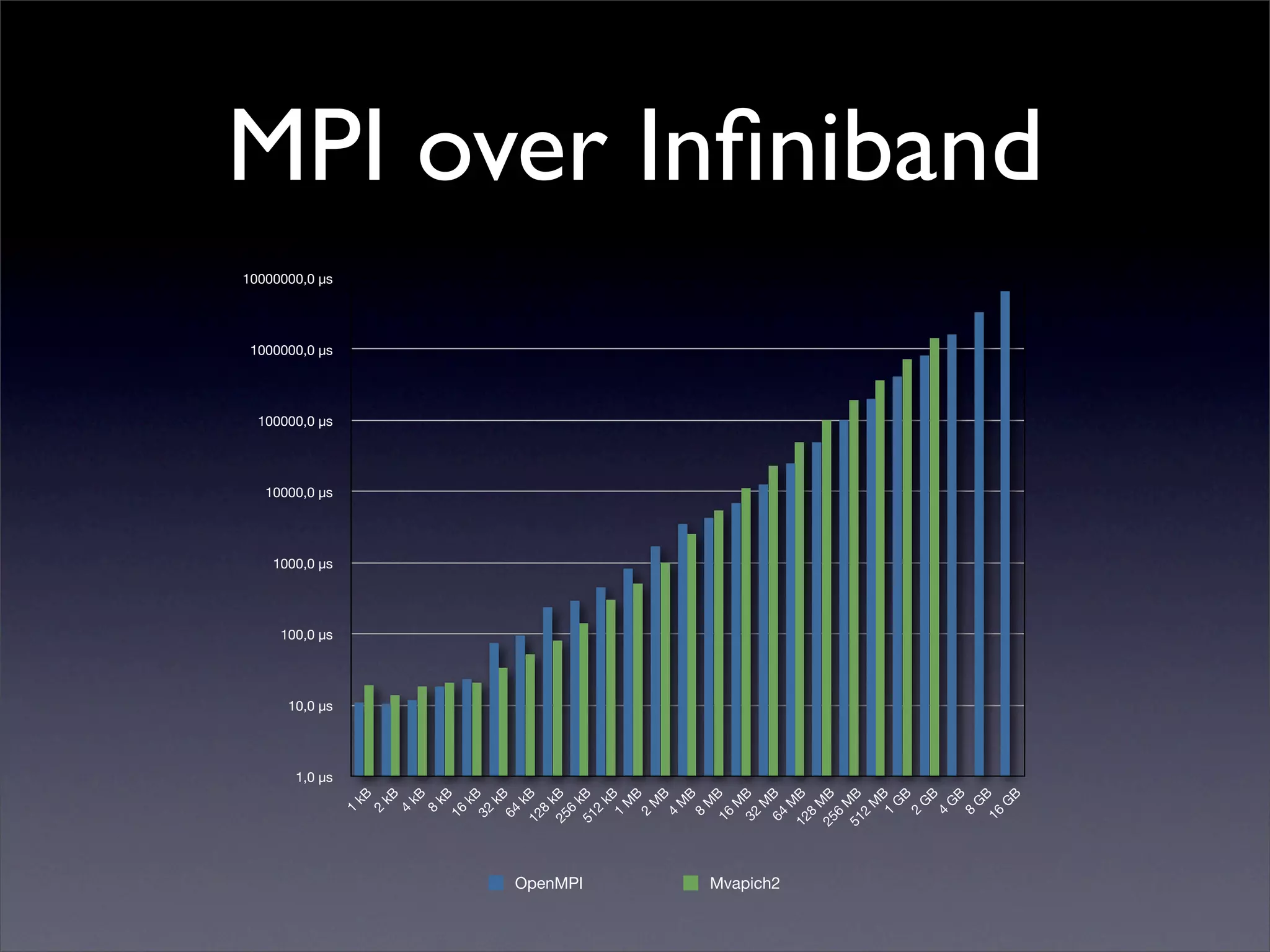
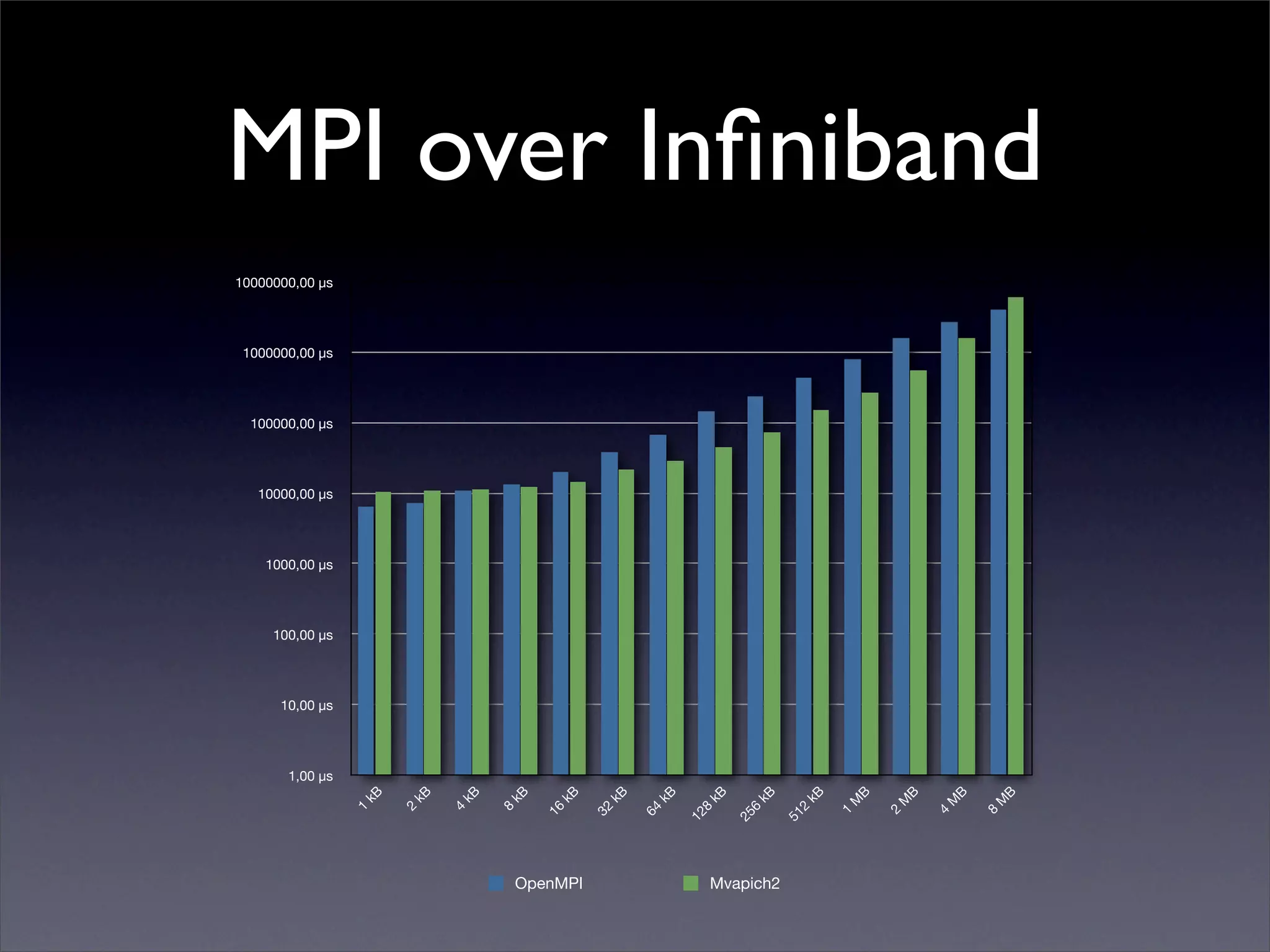
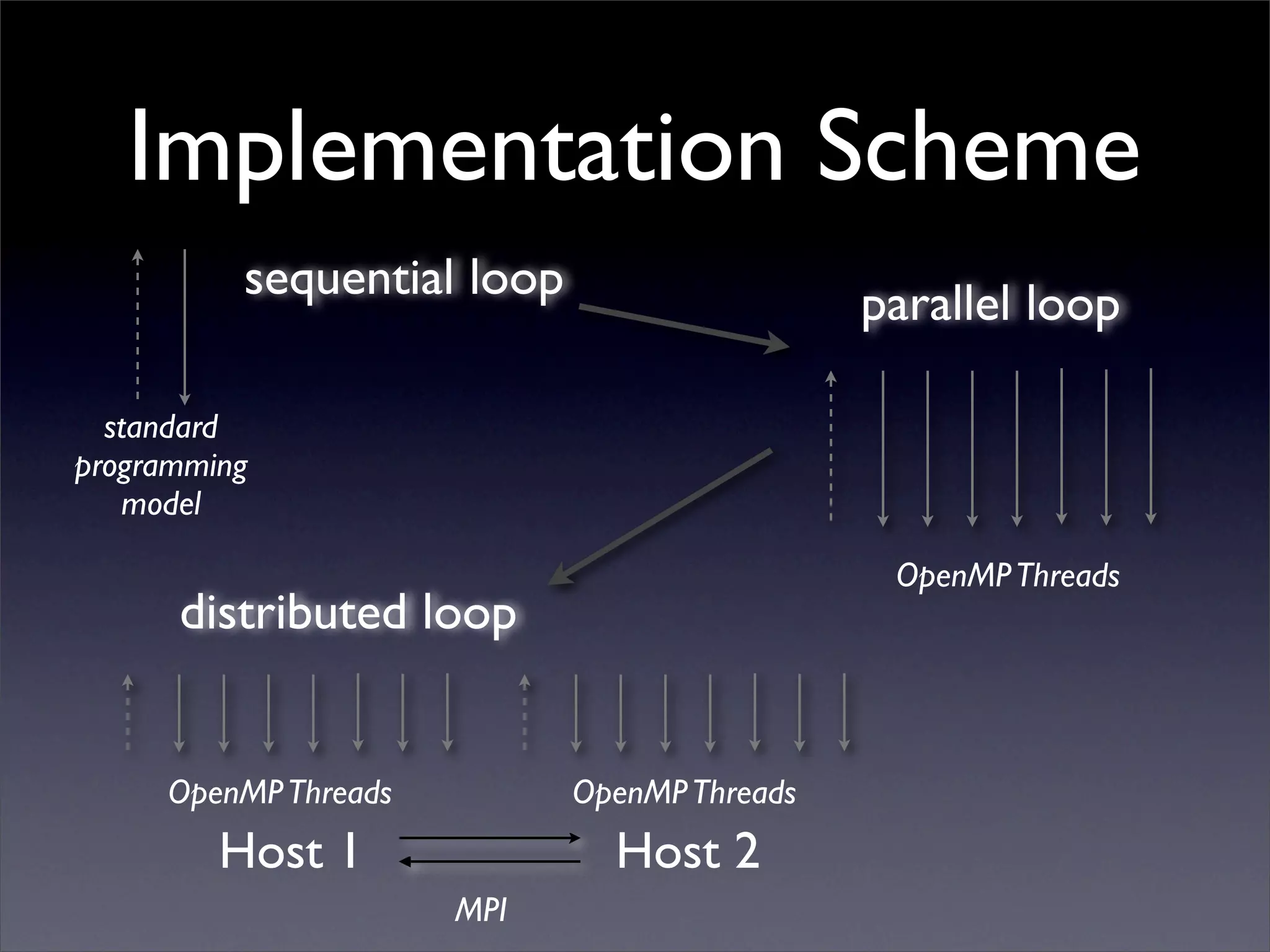
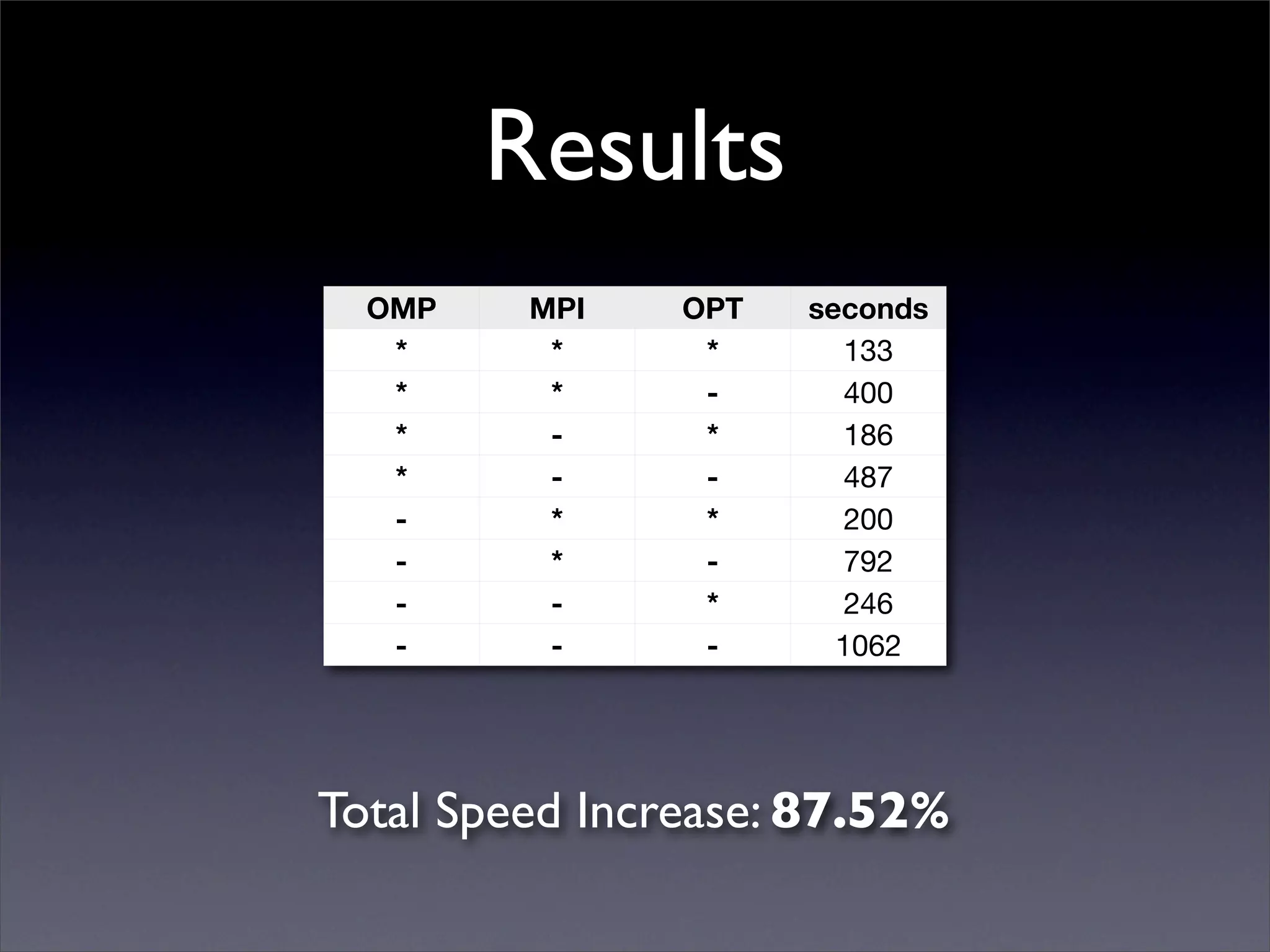
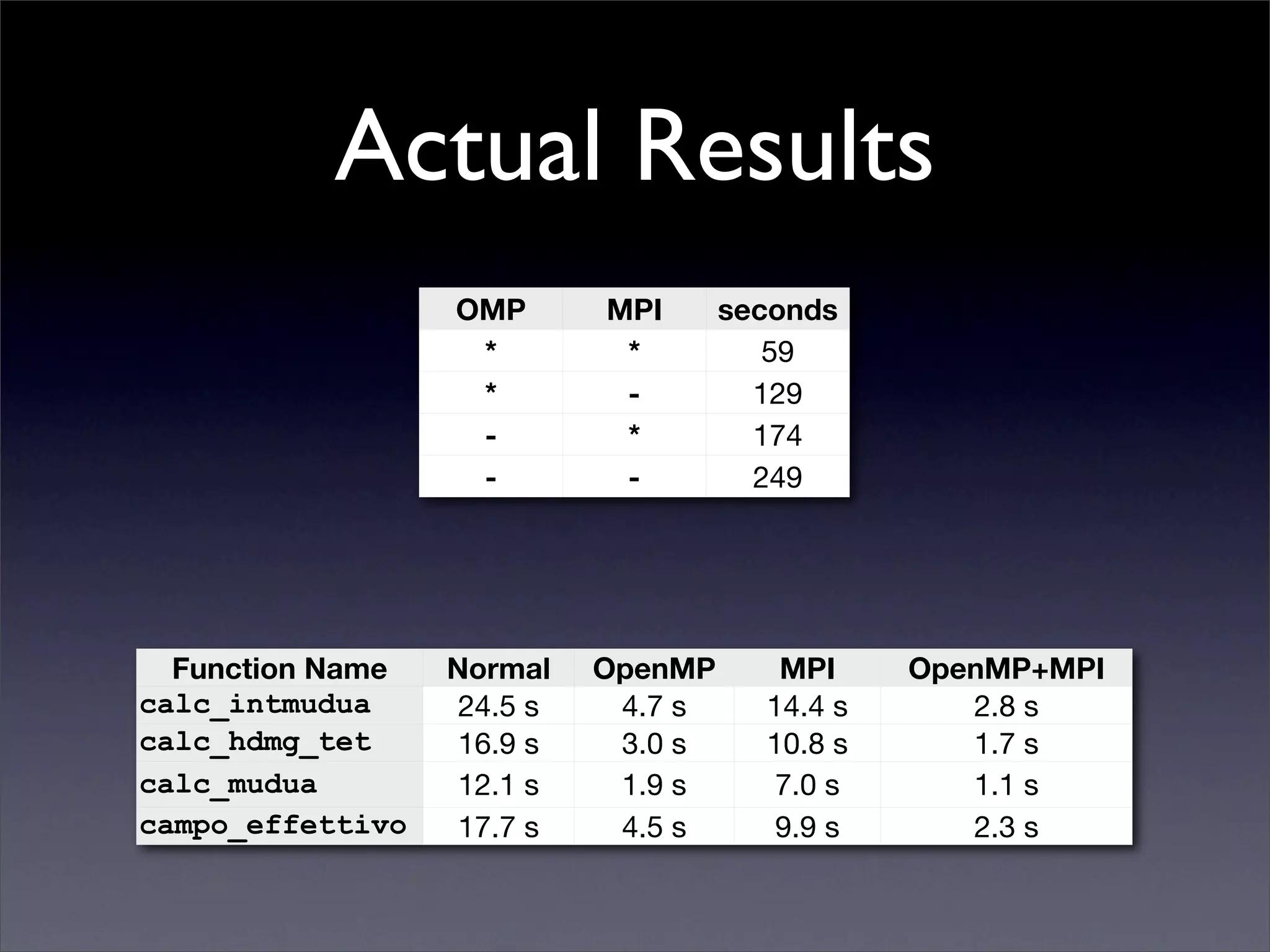
This document summarizes work on parallelizing and distributing computation on a low latency cluster using OpenMP and MPI over Infiniband. The key strategies involved installing optimized Linux, compilers, and Infiniband drivers, then adding OpenMP and MPI directives to parallelize a micromagnetics simulation software. Results showed OpenMP provided 6-8x speedup, MPI 2x, and combined OpenMP and MPI provided 14-16x speedup, reducing computation time by 76%. Future work involves further parallelization and algorithm optimization.