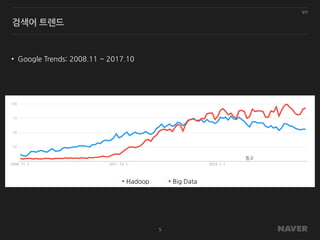
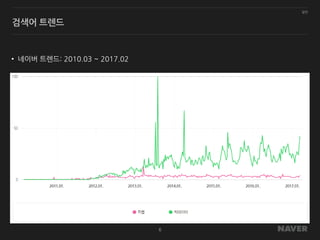
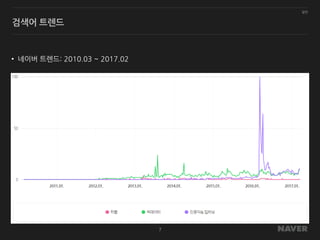
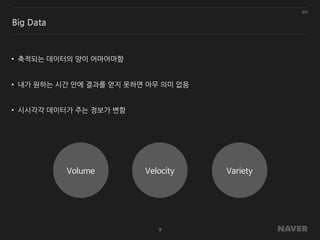
일반
11
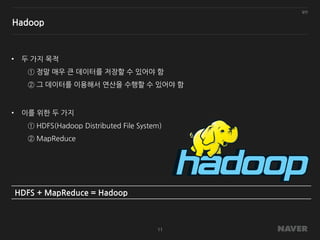
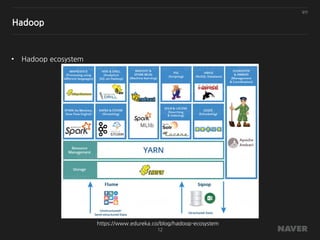
Hadoop
• 두 가지목적
① 정말 매우 큰 데이터를 저장할 수 있어야 함
② 그 데이터를 이용해서 연산을 수행할 수 있어야 함
• 이를 위한 두 가지
① HDFS(Hadoop Distributed File System)
② MapReduce
HDFS + MapReduce = Hadoop
일반
21
C3
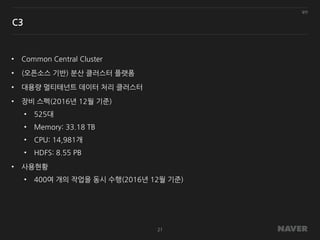
• Common CentralCluster
• (오픈소스 기반) 분산 클러스터 플랫폼
• 대용량 멀티테넌트 데이터 처리 클러스터
• 장비 스펙(2016년 12월 기준)
• 525대
• Memory: 33.18 TB
• CPU: 14,981개
• HDFS: 8.55 PB
• 사용현황
• 400여 개의 작업을 동시 수행(2016년 12월 기준)
22.
일반
22
C3
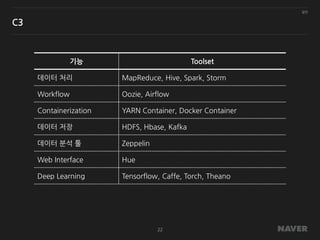
기능 Toolset
데이터 처리MapReduce, Hive, Spark, Storm
Workflow Oozie, Airflow
Containerization YARN Container, Docker Container
데이터 저장 HDFS, Hbase, Kafka
데이터 분석 툴 Zeppelin
Web Interface Hue
Deep Learning Tensorflow, Caffe, Torch, Theano
일반
24
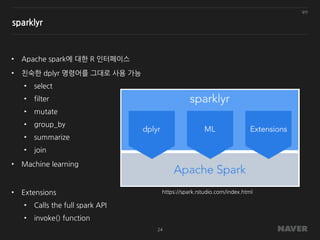
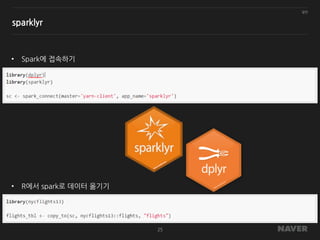
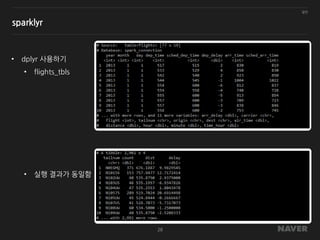
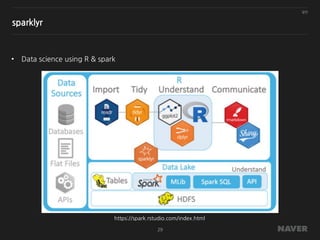
sparklyr
• Apache spark에대한 R 인터페이스
• 친숙한 dplyr 명령어를 그대로 사용 가능
• select
• filter
• mutate
• group_by
• summarize
• join
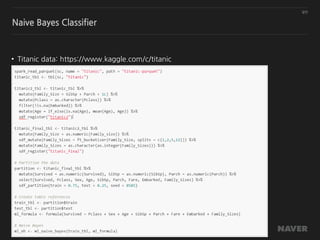
• Machine learning
• Extensions
• Calls the full spark API
• invoke() function
https://spark.rstudio.com/index.html
일반
37
맺음말
Hadoop를 배웠으면 spark도얼른 배우세요!
Hadoop을 모르셔도 spark는 얼른 배우세요!
Spark 모르셔도 R만 잘 하시면 big data 분석할 수 있어요!
Big data에 대한 machine learning으로 새로운 가치를 창출해 보세요!






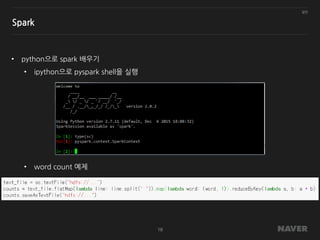




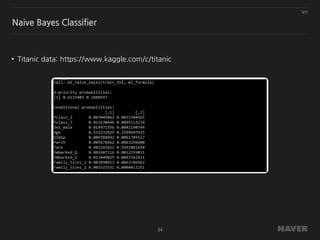












![[DL Hacks]CelebAをNumPyで保存してみた](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacklt20180910-180911055639-thumbnail.jpg?width=640&height=640&fit=bounds)




![[第2版] Python機械学習プログラミング 第2章](https://cdn.slidesharecdn.com/ss_thumbnails/python-machine-learning-2nd-edition-02-180905090109-thumbnail.jpg?width=640&height=640&fit=bounds)






























![[D2 COMMUNITY] Spark User Group - 스파크를 통한 딥러닝 이론과 실제](https://cdn.slidesharecdn.com/ss_thumbnails/520160211-160307085845-thumbnail.jpg?width=640&height=640&fit=bounds)








![[경북] I'mcloud information](https://cdn.slidesharecdn.com/ss_thumbnails/imcloudinformation-151105091525-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)




















