Recommended
PDF
실시간 빅 데이터 기술 현황 및 Daum 활용 사례 소개 (2013)
PDF
하둡 알아보기(Learn about Hadoop basic), NetApp FAS NFS Connector for Hadoop
PDF
GRUTER가 들려주는 Big Data Platform 구축 전략과 적용 사례: Tajo와 SQL-on-Hadoop
PDF
GRUTER가 들려주는 Big Data Platform 구축 전략과 적용 사례: 인터넷 쇼핑몰의 실시간 분석 플랫폼 구축 사례
PDF
Daum내부 Hadoop 활용 사례 | Devon 2012
PDF
Hadoop과 SQL-on-Hadoop (A short intro to Hadoop and SQL-on-Hadoop)
PDF
PDF
PPTX
Gruter TECHDAY 2014 MelOn BigData
PDF
PDF
[Open Technet Summit 2014] 쓰기 쉬운 Hadoop 기반 빅데이터 플랫폼 아키텍처 및 활용 방안
PDF
Expanding Your Data Warehouse with Tajo
PPTX
Introduction to Apache Tajo
PPTX
Tajo and SQL-on-Hadoop in Tech Planet 2013
PPTX
PDF
PDF
PDF
Big data analysis with R and Apache Tajo (in Korean)
PPTX
3회 서울 Hadoop 사용자 모임 / 아파치 피닉스
PPTX
An introduction to hadoop
PDF
Tajo TPC-H Benchmark Test on AWS
PDF
Spark Day 2017@Seoul(Spark Bootcamp)
PDF
스타트업사례로 본 로그 데이터분석 : Tajo on AWS
PDF
GRUTER가 들려주는 Big Data Platform 구축 전략과 적용 사례: SNS 서비스 아키텍쳐 구축 사례
PDF
PDF
PDF
하둡 좋은약이지만 만병통치약은 아니다
PDF
New ICT Trends in CES 2016
PPTX
PDF
Cloudera session seoul - Spark bootcamp
More Related Content
PDF
실시간 빅 데이터 기술 현황 및 Daum 활용 사례 소개 (2013)
PDF
하둡 알아보기(Learn about Hadoop basic), NetApp FAS NFS Connector for Hadoop
PDF
GRUTER가 들려주는 Big Data Platform 구축 전략과 적용 사례: Tajo와 SQL-on-Hadoop
PDF
GRUTER가 들려주는 Big Data Platform 구축 전략과 적용 사례: 인터넷 쇼핑몰의 실시간 분석 플랫폼 구축 사례
PDF
Daum내부 Hadoop 활용 사례 | Devon 2012
PDF
Hadoop과 SQL-on-Hadoop (A short intro to Hadoop and SQL-on-Hadoop)
PDF
PDF
What's hot
PPTX
Gruter TECHDAY 2014 MelOn BigData
PDF
PDF
[Open Technet Summit 2014] 쓰기 쉬운 Hadoop 기반 빅데이터 플랫폼 아키텍처 및 활용 방안
PDF
Expanding Your Data Warehouse with Tajo
PPTX
Introduction to Apache Tajo
PPTX
Tajo and SQL-on-Hadoop in Tech Planet 2013
PPTX
PDF
PDF
PDF
Big data analysis with R and Apache Tajo (in Korean)
PPTX
3회 서울 Hadoop 사용자 모임 / 아파치 피닉스
PPTX
An introduction to hadoop
PDF
Tajo TPC-H Benchmark Test on AWS
PDF
Spark Day 2017@Seoul(Spark Bootcamp)
PDF
스타트업사례로 본 로그 데이터분석 : Tajo on AWS
PDF
GRUTER가 들려주는 Big Data Platform 구축 전략과 적용 사례: SNS 서비스 아키텍쳐 구축 사례
PDF
PDF
PDF
하둡 좋은약이지만 만병통치약은 아니다
Viewers also liked
PDF
New ICT Trends in CES 2016
PPTX
PDF
Cloudera session seoul - Spark bootcamp
PDF
PDF
Hnavi-HDFS based log aggregater with HDFS Browser
PDF
2017 tensor flow dev summit
PDF
Enterprise conference 2013 Microsoft BigData 사례발표자료
PPTX
PPTX
It Trends 2015-2H-totoro4
PPTX
It trends 2015 3 q-totoro4
PDF
PPTX
빅데이터와 로봇 (Big Data in Robotics)
PDF
PDF
빅데이터 환경에서 지능형 로그 관리 플랫폼으로 진화하는 보안 정보&이벤트 관리 동향
PDF
AWS와 Open Source - 윤석찬 (OSS개발자 그룹)
PDF
대용량 로그분석 Bigquery로 간단히 사용하기 (20170215 T아카데미)
PDF
[SSA] 01.bigdata database technology (2014.02.05)
Similar to 빅데이터 구축 사례
PDF
Apache hbase overview (20160427)
PDF
log-monitoring-architecture.pdf
PDF
OpenSource Big Data Platform : Flamingo Project
PDF
OpenSource Big Data Platform - Flamingo 소개와 활용
PDF
OpenSource Big Data Platform - Flamingo v7
PDF
PDF
SK ICT Tech Summit 2019_BIG DATA-11번가_DP_v1.2.pdf
KEY
Distributed Programming Framework, hadoop
PDF
PPTX
2015년 제2회 동아리 해커 세미나 - 게임개발과 게임에서의 빅데이터 (9기 박경재)
PDF
[오픈소스컨설팅] OpenInfra Asia 2024_OpenStack & K8S로 혁신하는 기상청
PDF
Custom DevOps Monitoring System in MelOn (with InfluxDB + Telegraf + Grafana)
PDF
Monitoring System for DevOps - Case of MelOn
PPTX
PPTX
[경북] I'mcloud information
PPTX
PDF
Tdc2013 선배들에게 배우는 server scalability
PPT
PDF
[AWS Builders] 우리 워크로드에 맞는 데이터베이스 찾기
PPT
빅데이터 구축 사례 1. 빅데이터 구축 사례
오태현
paranmul@gmail.com
paranmul@inbrein.com
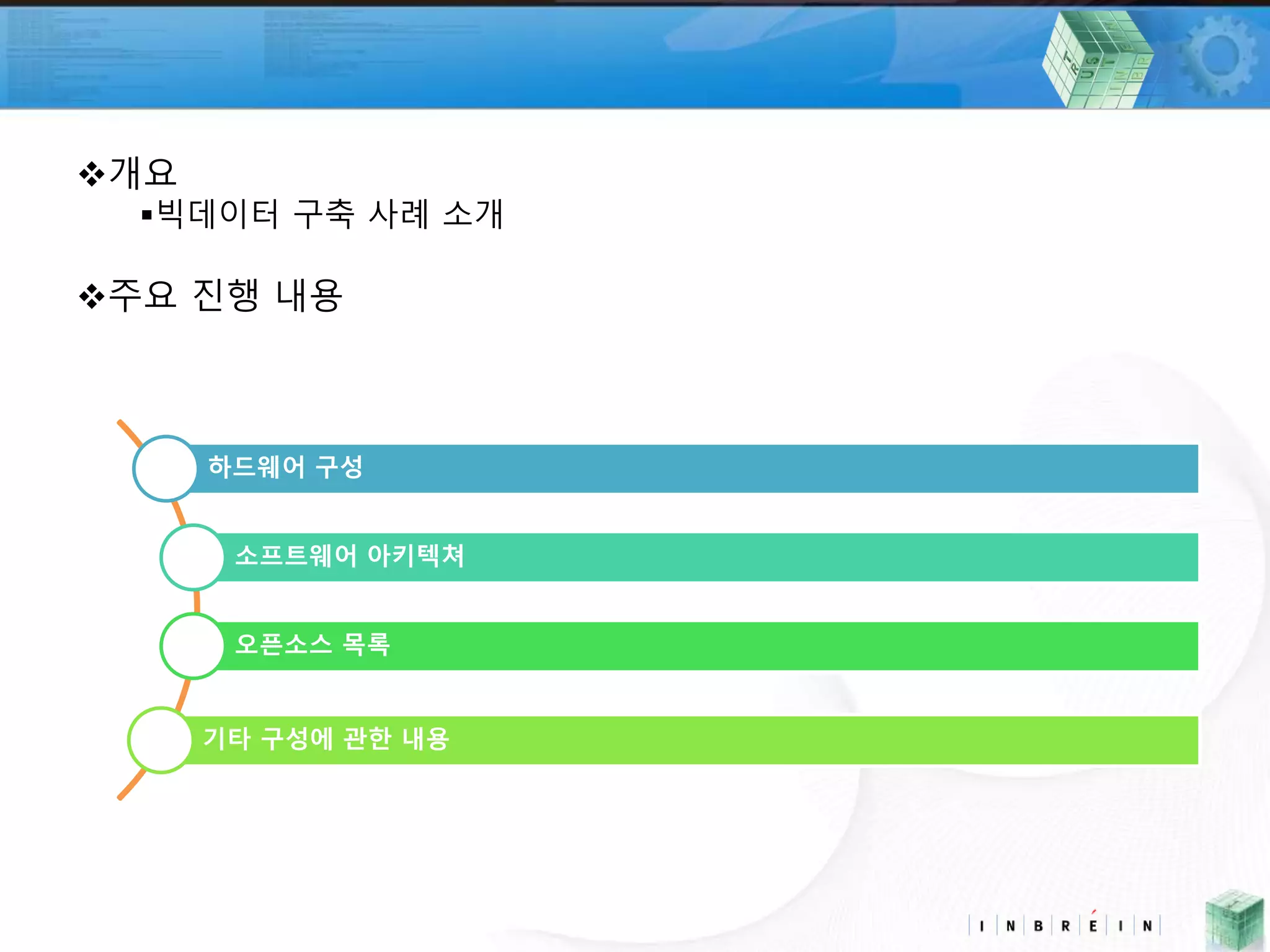
2. 개요
빅데이터 구축 사례 소개
주요 진행 내용
하드웨어 구성
소프트웨어 아키텍쳐
오픈소스 목록
기타 구성에 관한 내용
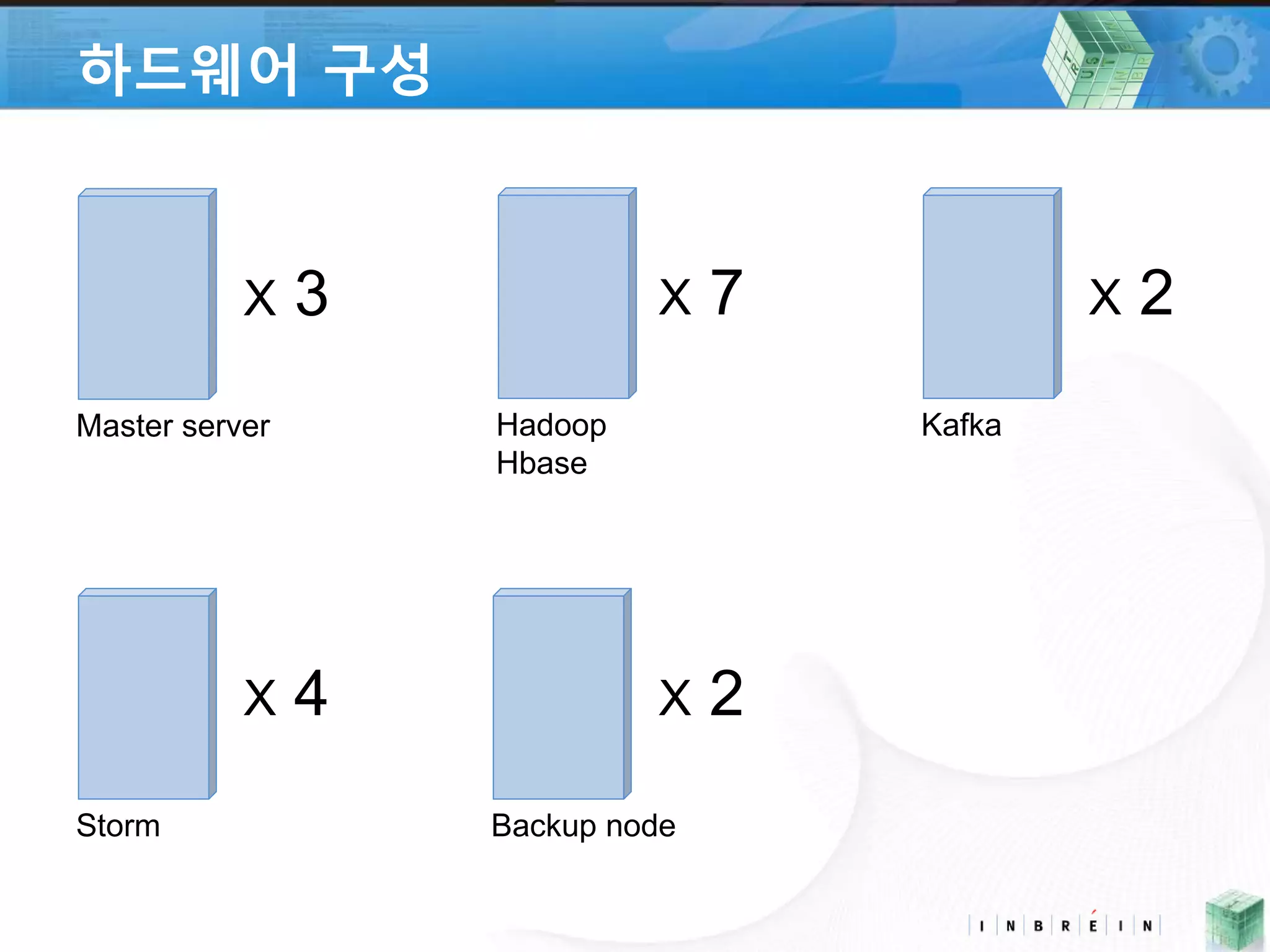
3. 하드웨어 구성
X 3
Master server
Hadoop
Hbase
X 7
Kafka
X 2
Storm
X 4
X 2
Backup node
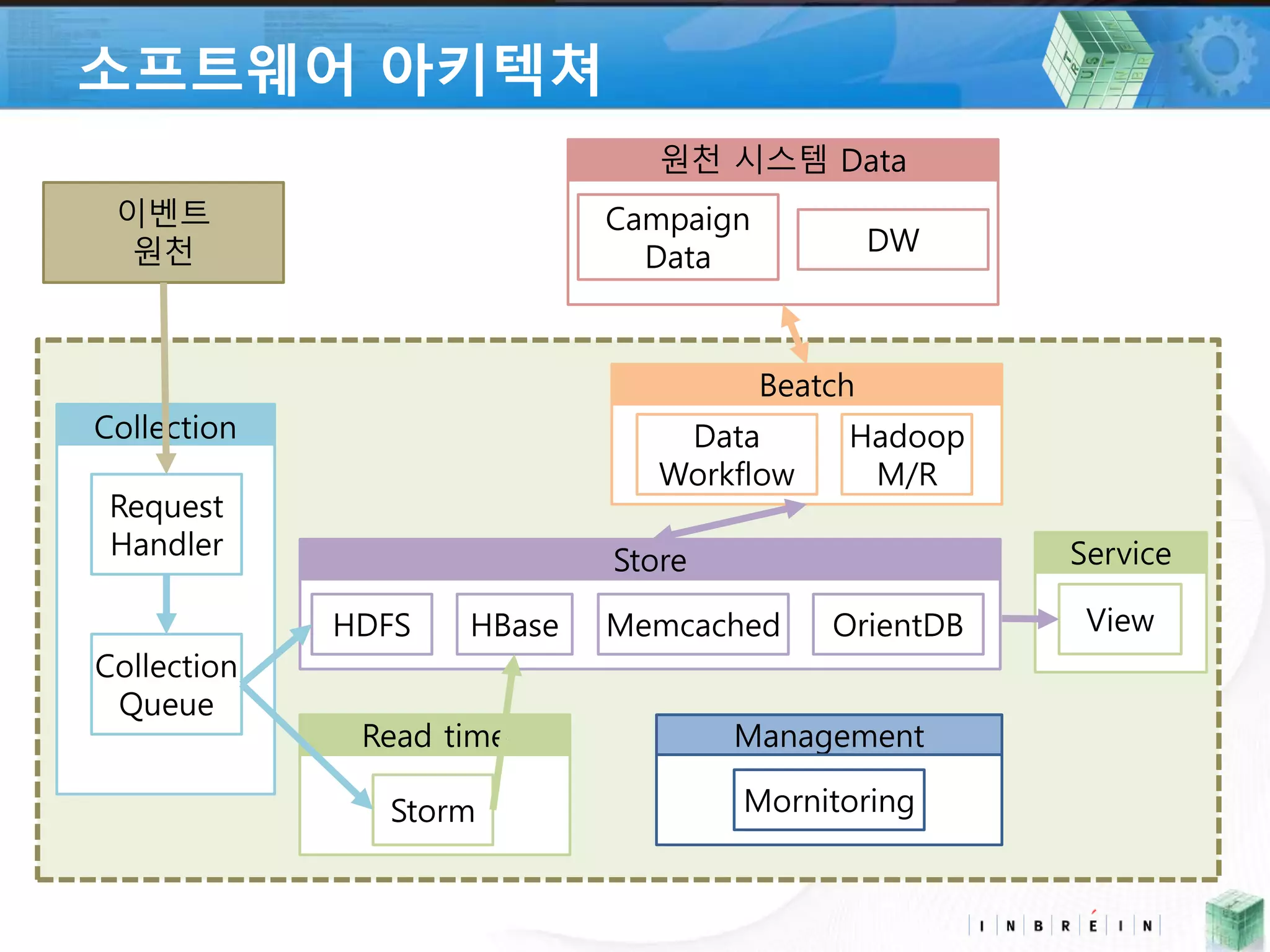
4. 소프트웨어 아키텍쳐
Collection
Request
Handler
Collection
Queue
원천 시스템 Data
Store
HDFS HBase Memcached OrientDB
Read time
Storm
Beatch
Data
Workflow
Hadoop
M/R
Campaign
Data
DW
Management
Mornitoring
이벤트
원천
Service
View
5. 사용된 오픈소스 목록
• Sqoop *
• Hbase
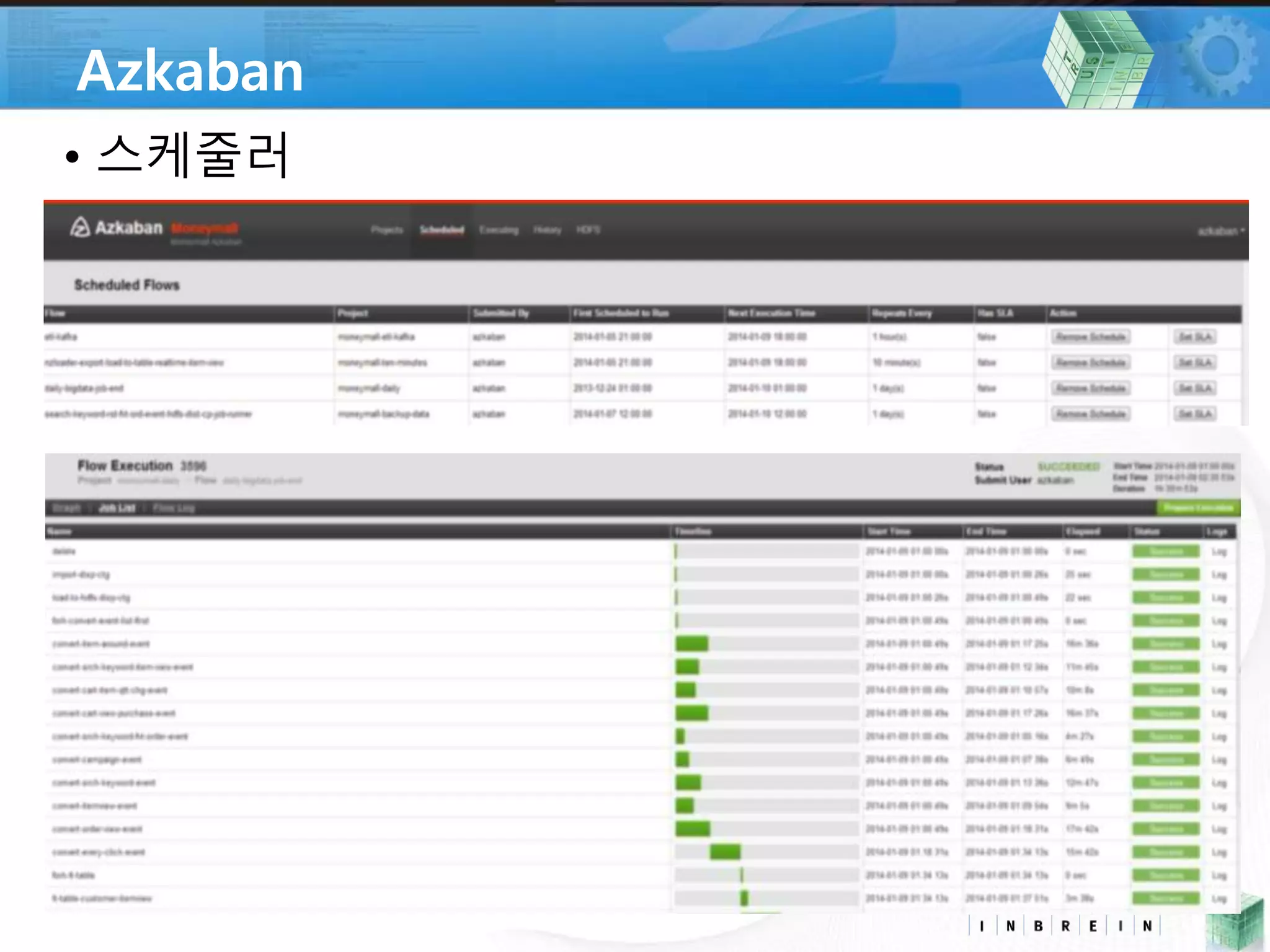
• Azkaban *
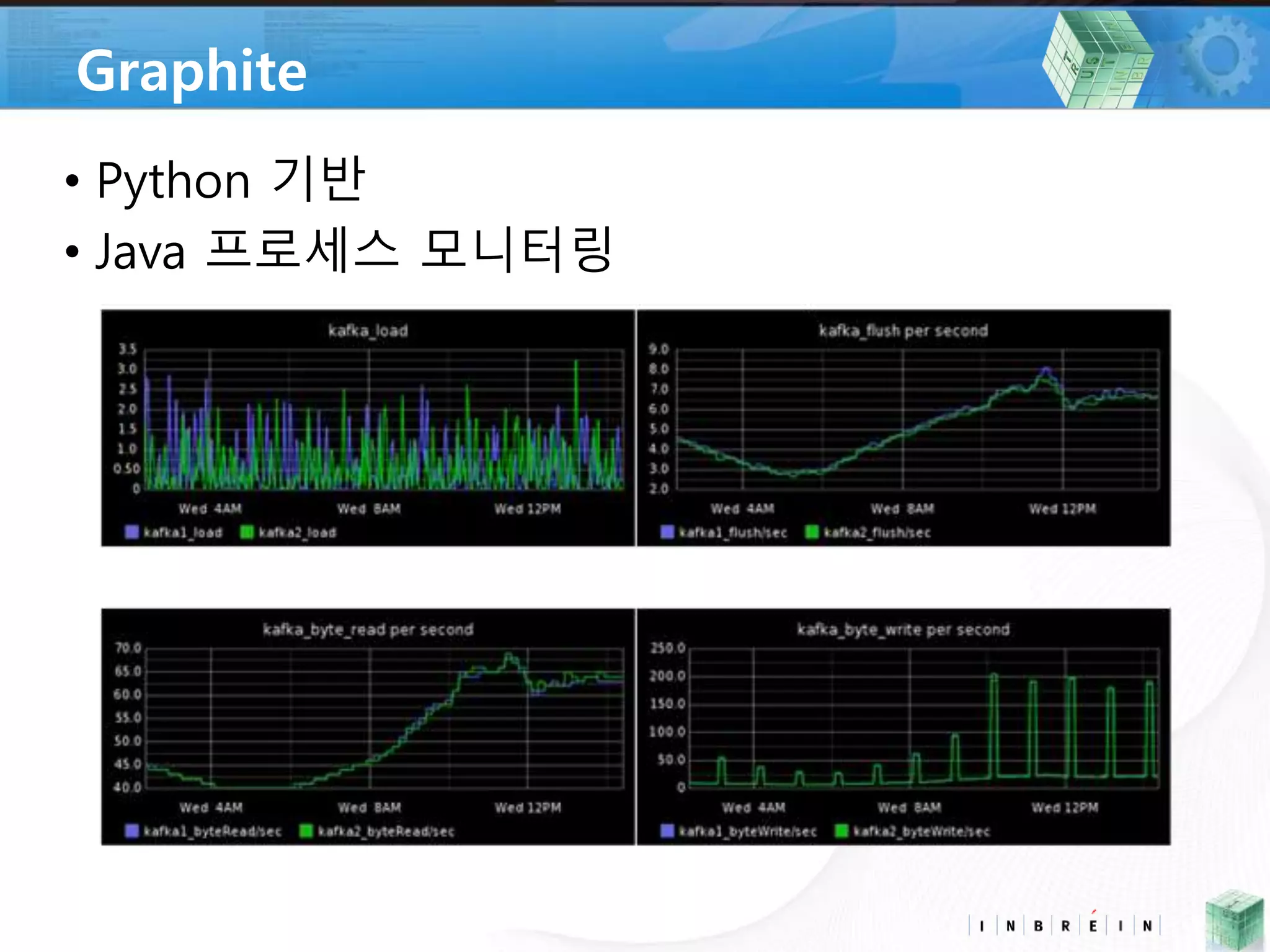
• Graphite *
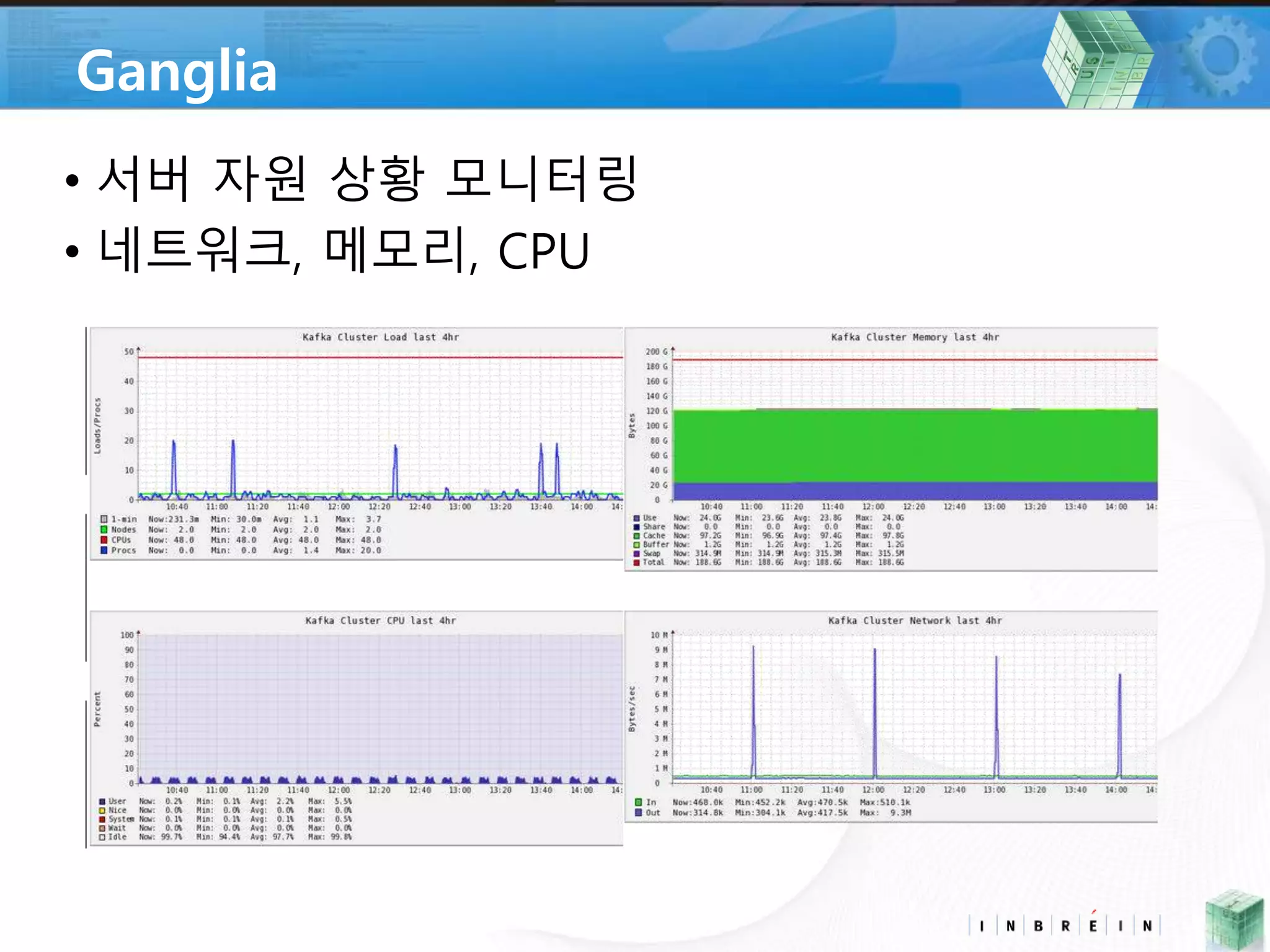
• Ganglia *
• Memcached
• MariaDB
• Verte.x
• Flume
• Kafka *
• Camus
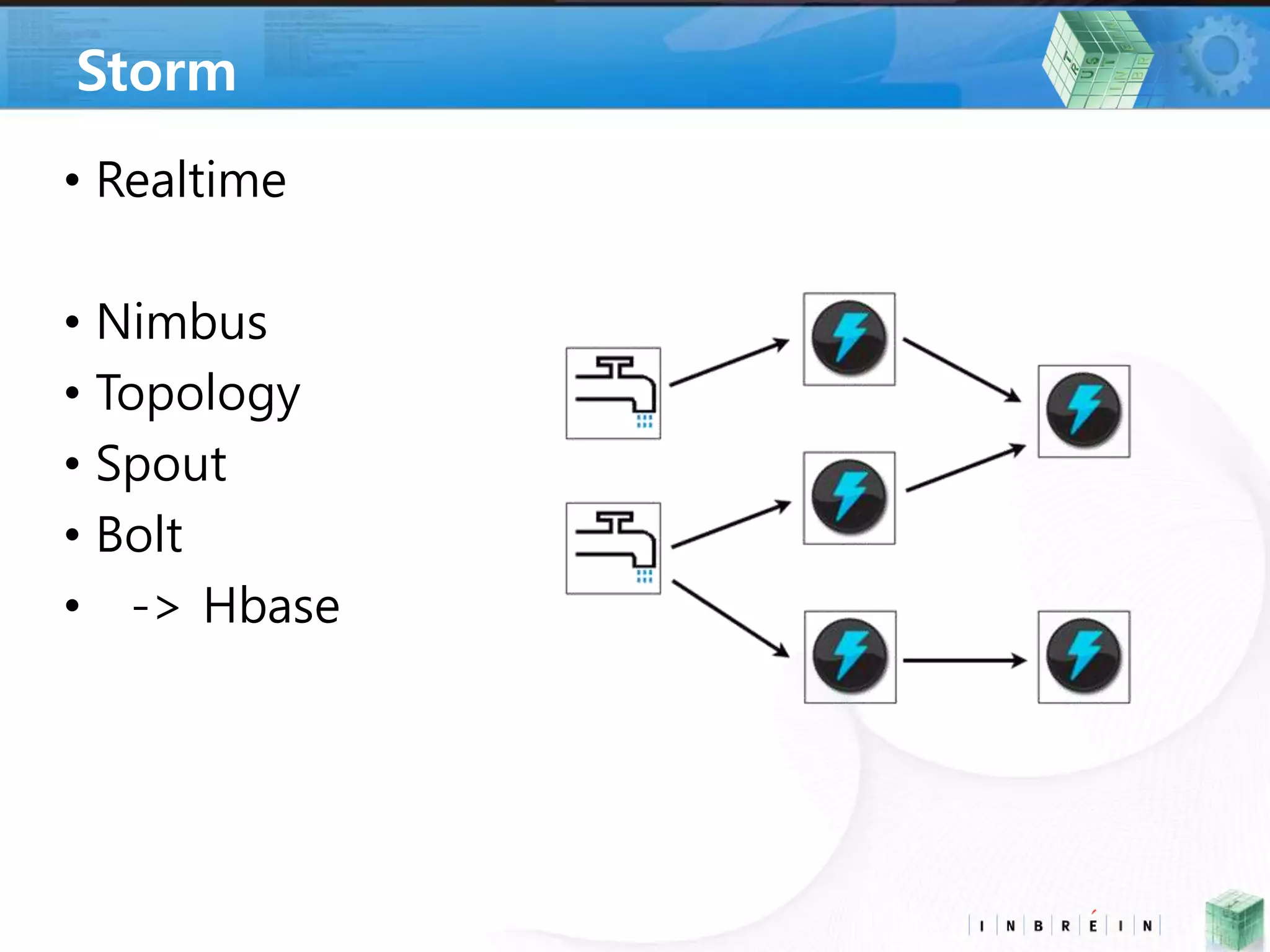
• Storm *
• Hive
• Hadoop
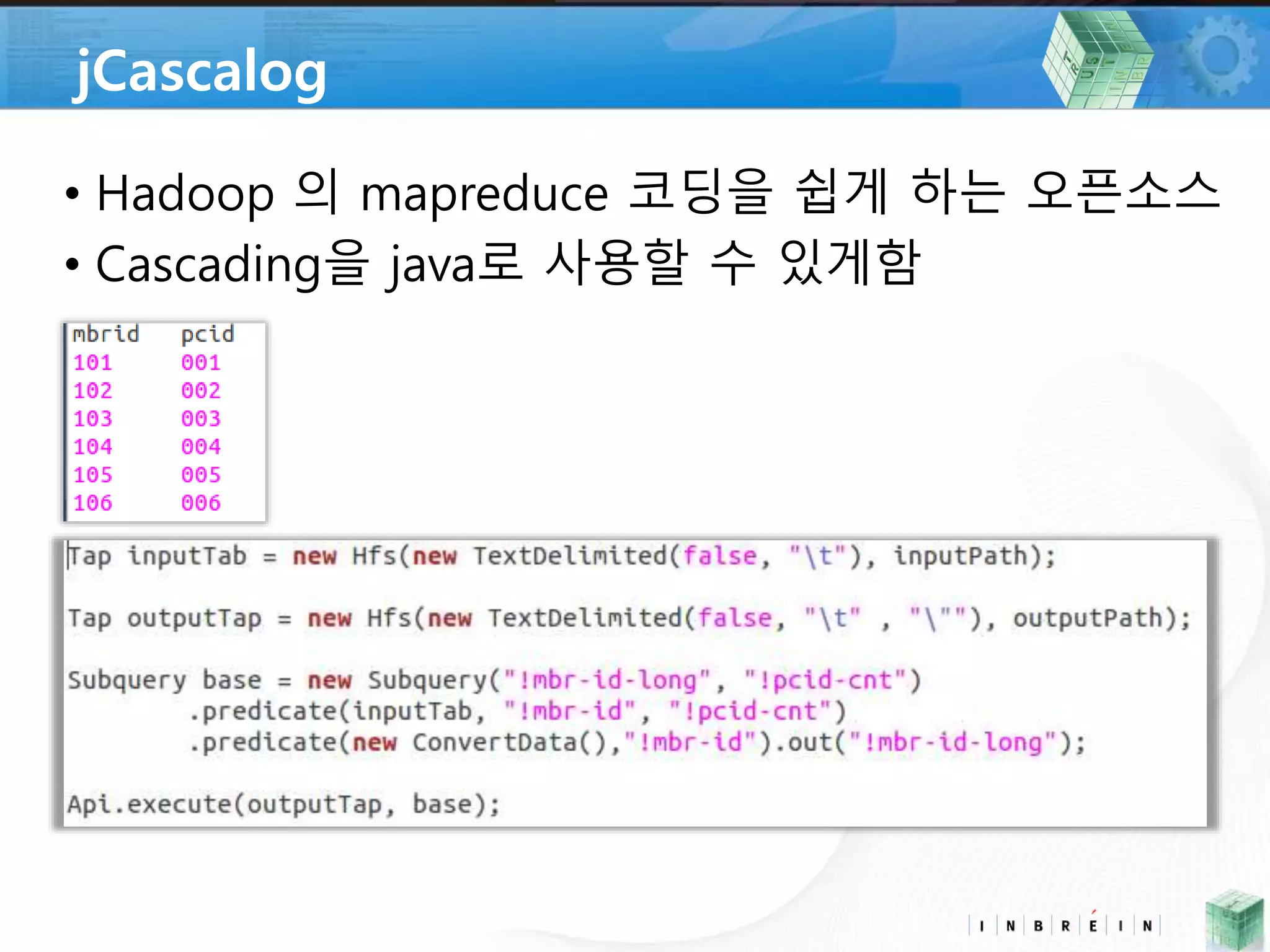
• jCascalog *
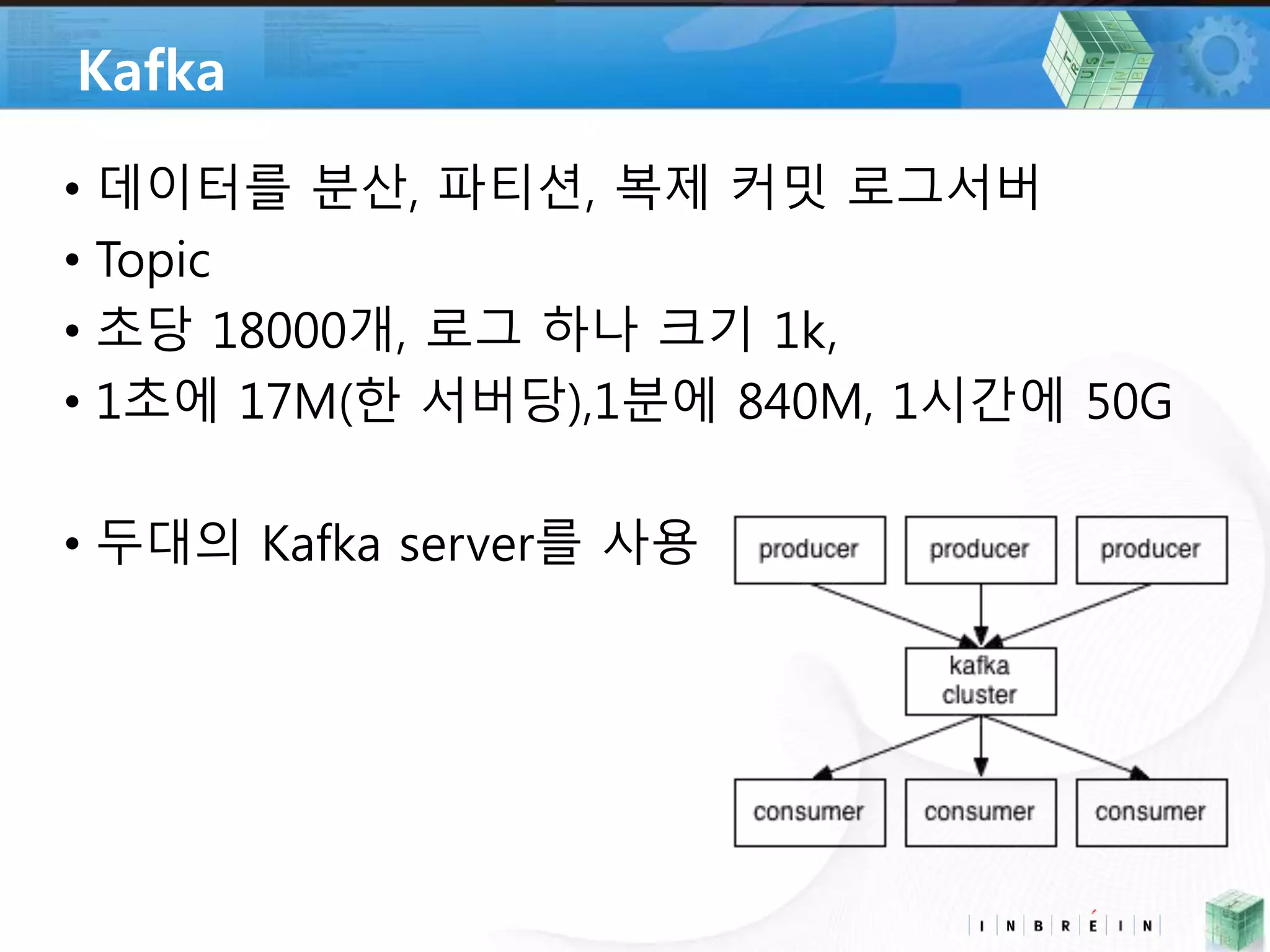
6. Kafka
• 데이터를 분산, 파티션, 복제 커밋 로그서버
• Topic
• 초당 18000개, 로그 하나 크기 1k,
• 1초에 17M(한 서버당),1분에 840M, 1시간에 50G
• 두대의 Kafka server를 사용
7. 8. 9. Sqoop
• RDB 와 HDFS사이에 데이터를 전달 하는 오픈소스
• pwd, mssql, mariaDB, Oracle, netezza, mysql,
hbase
10. 11. 12. 13. 14. 환경 구성에 관해서
• 기간, 인원
• 구성 중 문제점들
• Hortonworks
• Oozie 관리 페이지 로딩
• Zookeeper 사용하는 오픈소스 증가 – 분리
• 한 서버에 다양한 오픈소스 공생
• 많은 수의 포트 오픈
• MR job 증가
• 개발서버 부재
• 스톰 트라이던트 & 카프카
• Hbase 키 설계
15.















![[Open Technet Summit 2014] 쓰기 쉬운 Hadoop 기반 빅데이터 플랫폼 아키텍처 및 활용 방안](https://cdn.slidesharecdn.com/ss_thumbnails/open-technet-summit-2014-140313001107-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
































![[SSA] 01.bigdata database technology (2014.02.05)](https://cdn.slidesharecdn.com/ss_thumbnails/01-140225072202-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)










![[오픈소스컨설팅] OpenInfra Asia 2024_OpenStack & K8S로 혁신하는 기상청](https://cdn.slidesharecdn.com/ss_thumbnails/openinfraasia2024openstackk8s-241031061829-5114384e-thumbnail.jpg?width=640&height=640&fit=bounds)



![[경북] I'mcloud information](https://cdn.slidesharecdn.com/ss_thumbnails/imcloudinformation-151105091525-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)



![[AWS Builders] 우리 워크로드에 맞는 데이터베이스 찾기](https://cdn.slidesharecdn.com/ss_thumbnails/awsbuildersaws201webinardatabasejuyeonpark-190306072417-thumbnail.jpg?width=640&height=640&fit=bounds)
