1
1
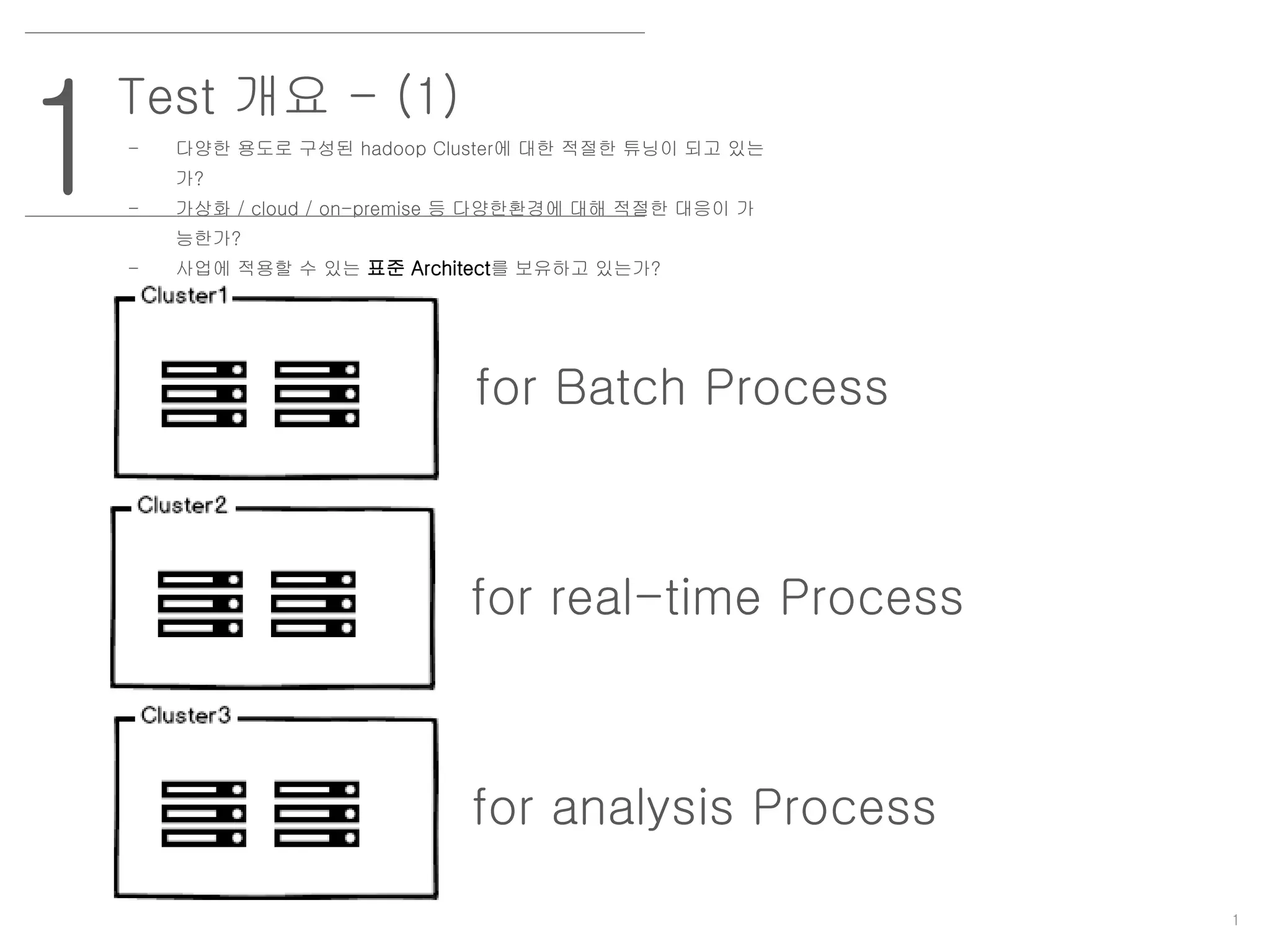
Test 개요 -(1)
- 다양한 용도로 구성된 hadoop Cluster에 대한 적절한 튜닝이 되고 있는
가?
- 가상화 / cloud / on-premise 등 다양한환경에 대해 적절한 대응이 가
능한가?
- 사업에 적용할 수 있는 표준 Architect를 보유하고 있는가?
for Batch Process
for real-time Process
for analysis Process
3.
2
1
Test 개요 -(2)
- 적절한 설정값은 무엇일까?
- Hadoop cluster 구성을 위해서는 너무 많은 고려사항
- On-site에 맞는 설정을 하는 것이 현실 Project Locality
: 다양한 환경에 공통적인 기준으로 활용할 수 있는
hadoop Eco / JVM / OS Tuning value을 찾아내는 것이 중요한
요소
4.
3
2
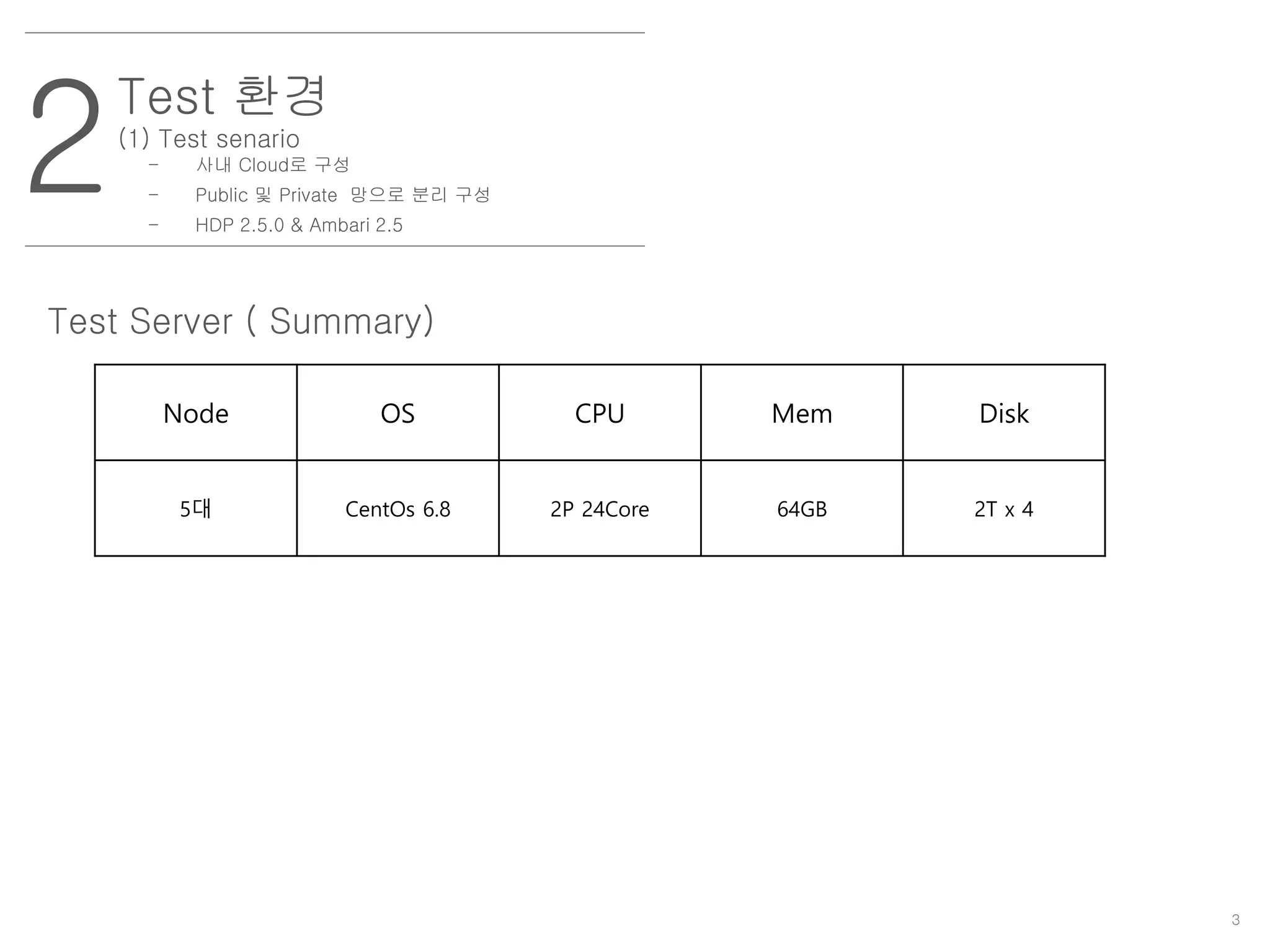
Test 환경
(1) Testsenario
- 사내 Cloud로 구성
- Public 및 Private 망으로 분리 구성
- HDP 2.5.0 & Ambari 2.5
Node OS CPU Mem Disk
5대 CentOs 6.8 2P 24Core 64GB 2T x 4
Test Server ( Summary)
5.
4
2
Test 환경
(2) Testsenario
- TPC Query 활용 ( www.tpc.org )
TPC
트랜잭션 처리 성능평가 위원회(Transaction Processing performance Council)에서 발표한 벤치마크 모델
6.
5
3
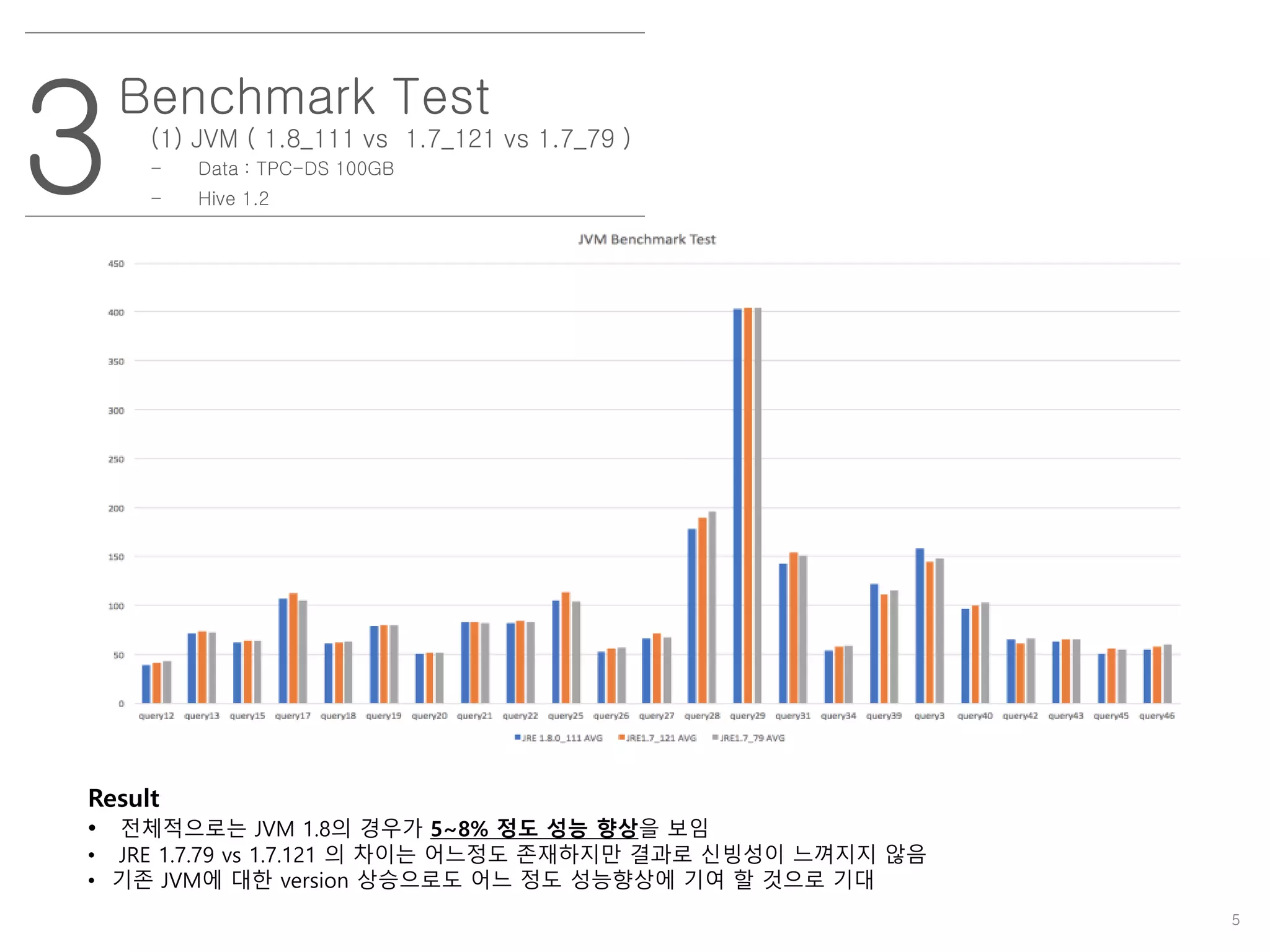
Benchmark Test
(1) JVM( 1.8_111 vs 1.7_121 vs 1.7_79 )
- Data : TPC-DS 100GB
- Hive 1.2
Result
• 전체적으로는 JVM 1.8의 경우가 5~8% 정도 성능 향상을 보임
• JRE 1.7.79 vs 1.7.121 의 차이는 어느정도 존재하지만 결과로 신빙성이 느껴지지 않음
• 기존 JVM에 대한 version 상승으로도 어느 정도 성능향상에 기여 할 것으로 기대
7
3
Benchmark Test
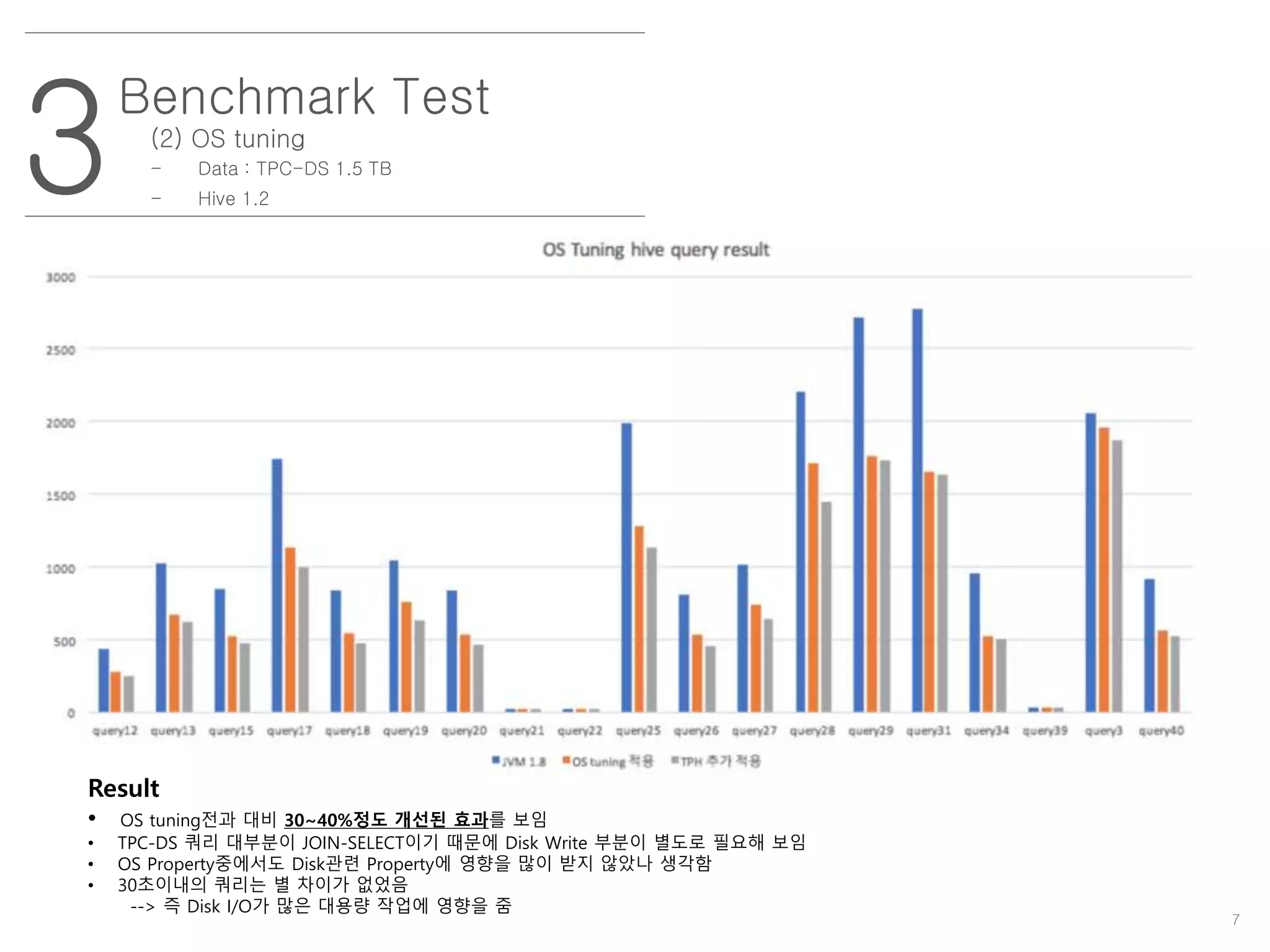
(2) OStuning
- Data : TPC-DS 1.5 TB
- Hive 1.2
Result
• OS tuning전과 대비 30~40%정도 개선된 효과를 보임
• TPC-DS 쿼리 대부분이 JOIN-SELECT이기 때문에 Disk Write 부분이 별도로 필요해 보임
• OS Property중에서도 Disk관련 Property에 영향을 많이 받지 않았나 생각함
• 30초이내의 쿼리는 별 차이가 없었음
--> 즉 Disk I/O가 많은 대용량 작업에 영향을 줌
9.
8
3
Benchmark Test
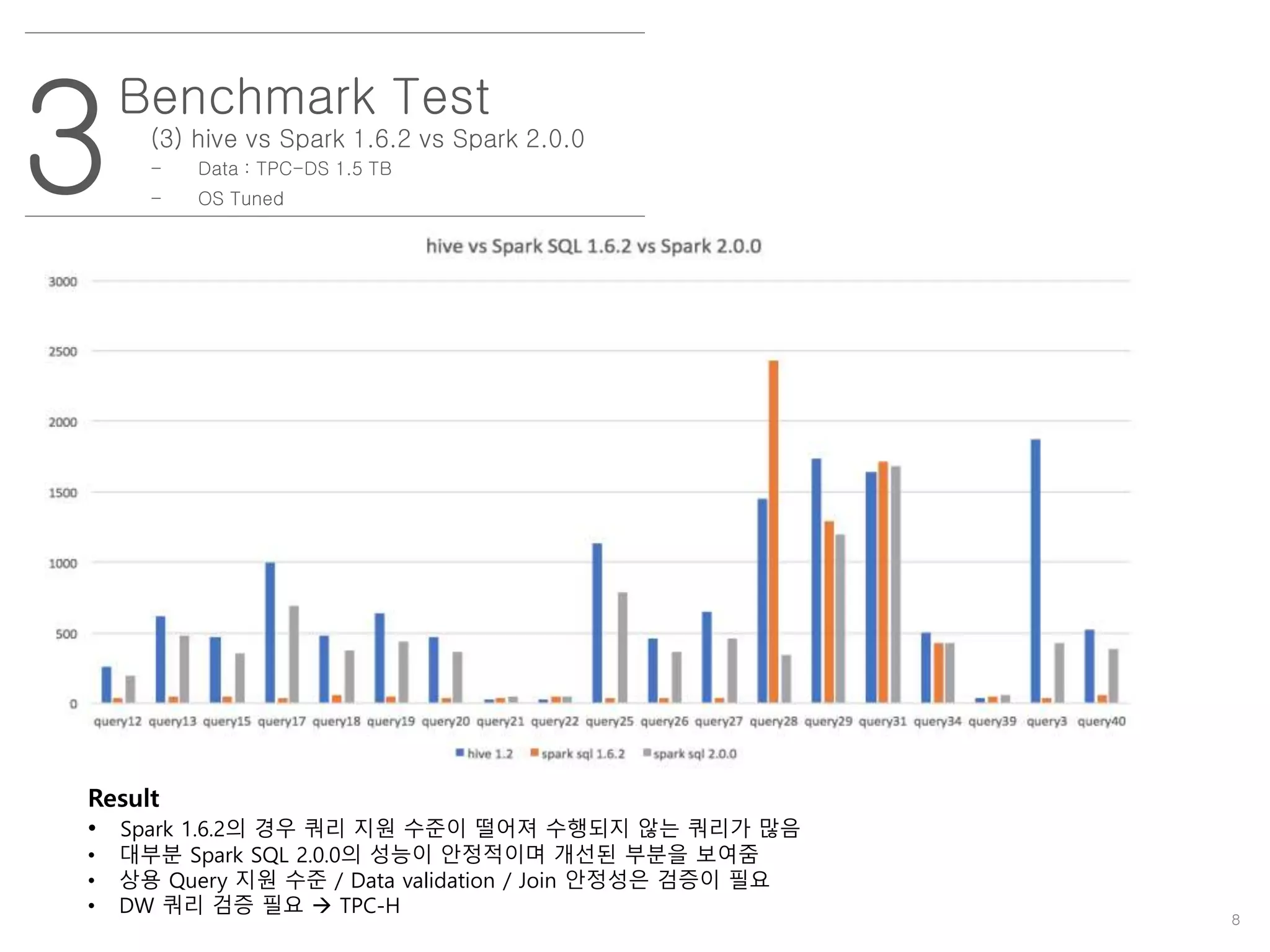
(3) hivevs Spark 1.6.2 vs Spark 2.0.0
- Data : TPC-DS 1.5 TB
- OS Tuned
Result
• Spark 1.6.2의 경우 쿼리 지원 수준이 떨어져 수행되지 않는 쿼리가 많음
• 대부분 Spark SQL 2.0.0의 성능이 안정적이며 개선된 부분을 보여줌
• 상용 Query 지원 수준 / Data validation / Join 안정성은 검증이 필요
• DW 쿼리 검증 필요 TPC-H
10.
9
3
Benchmark Test
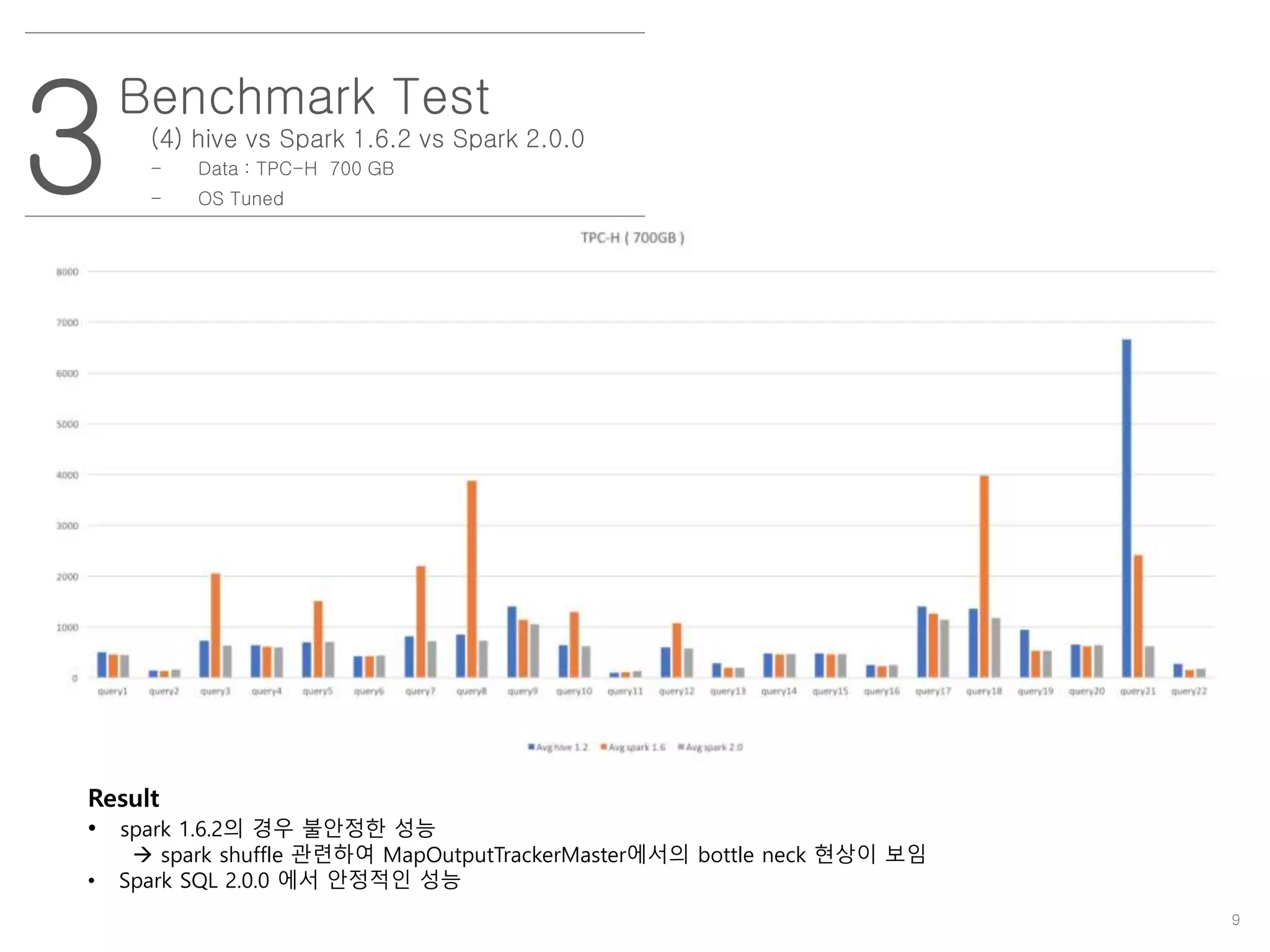
(4) hivevs Spark 1.6.2 vs Spark 2.0.0
- Data : TPC-H 700 GB
- OS Tuned
Result
• spark 1.6.2의 경우 불안정한 성능
spark shuffle 관련하여 MapOutputTrackerMaster에서의 bottle neck 현상이 보임
• Spark SQL 2.0.0 에서 안정적인 성능
11.
10
4
Summary
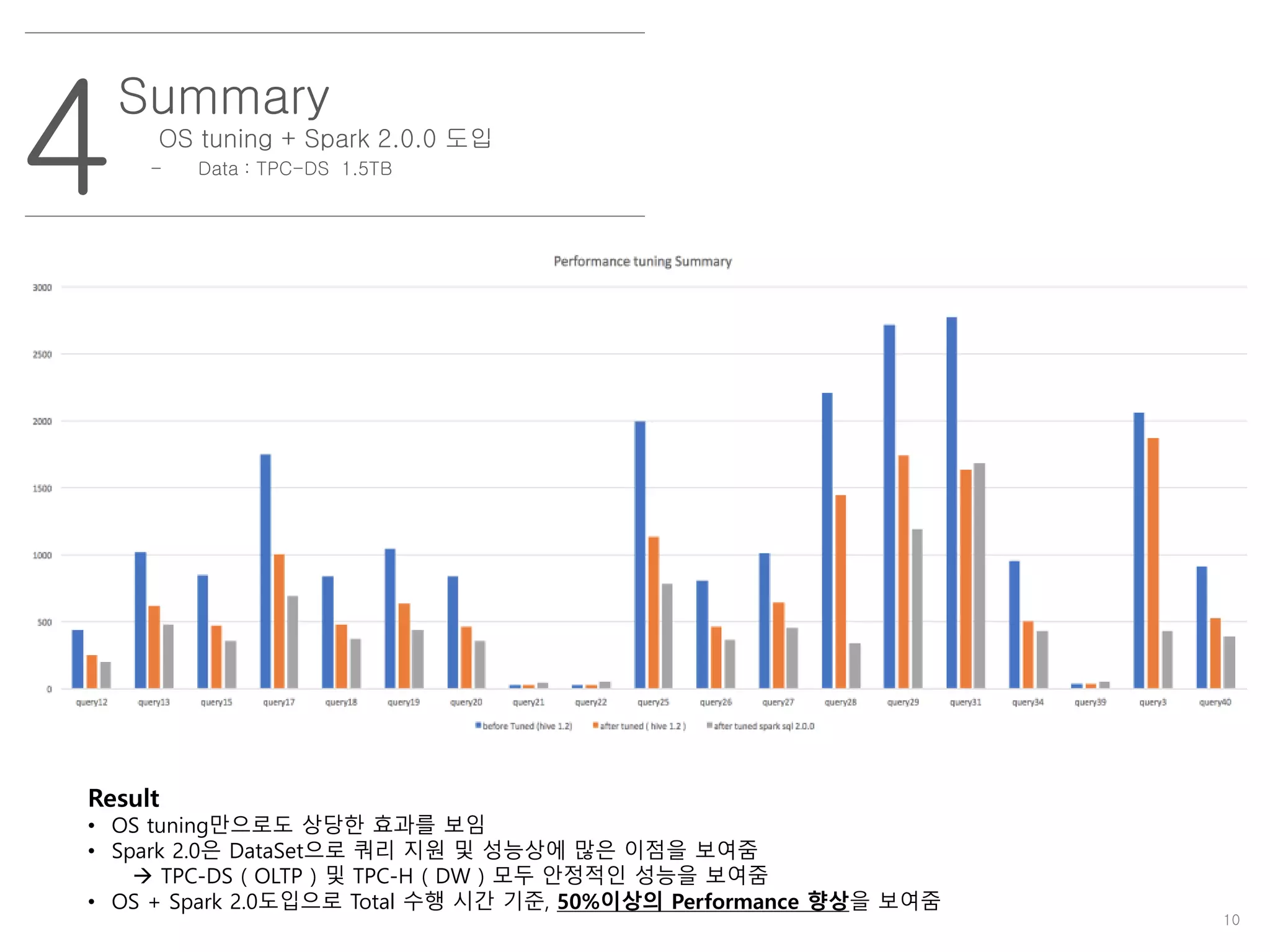
OS tuning +Spark 2.0.0 도입
- Data : TPC-DS 1.5TB
Result
• OS tuning만으로도 상당한 효과를 보임
• Spark 2.0은 DataSet으로 쿼리 지원 및 성능상에 많은 이점을 보여줌
TPC-DS ( OLTP ) 및 TPC-H ( DW ) 모두 안정적인 성능을 보여줌
• OS + Spark 2.0도입으로 Total 수행 시간 기준, 50%이상의 Performance 향상을 보여줌
12.
11
4
Summary
추가 고려요소
(1) StreamingPerformance
: DW성 데이터 처리로 이루어진 테스트와 더불어 Streaming Test도 병행되어야 할 듯
(2) HDFS Trouble Shooting
: Hbase나 Spark Streaming과 같은 서비스를 활용할 시, HDFS 구성에 따라 성능 및 에러를 보이는 경우가 많음
: Disk 성능을 높이기 위한 Tuning요소와 맞물려 Side effect를 발생시킬 수 도 있다.
(3) Network Topology
: Bonding / Rack Awareness등 추가 물리적인 구성을 고려할 필요가 있음
: 테스트는 Cloud환경에서 진행된 것이라 on-premises환경과 비교가 좀 더 필요함
(4) yarn 활용
: hive 및 Spark SQL은 Architecture활용성을 고려하여 Yarn-client로 수행함
: spark활용에 있어 yarn 구성 및 기타 다른 구성을 고려하여 운영성 표준을 재고할 필요가 있음
13.
12
Backup (1)
Spark SQL2.0
Query 지원 강화
TPC-DS 전 쿼리 지원
http://spark.apache.org/releases/spark-release-2-0-0.html
14.
13
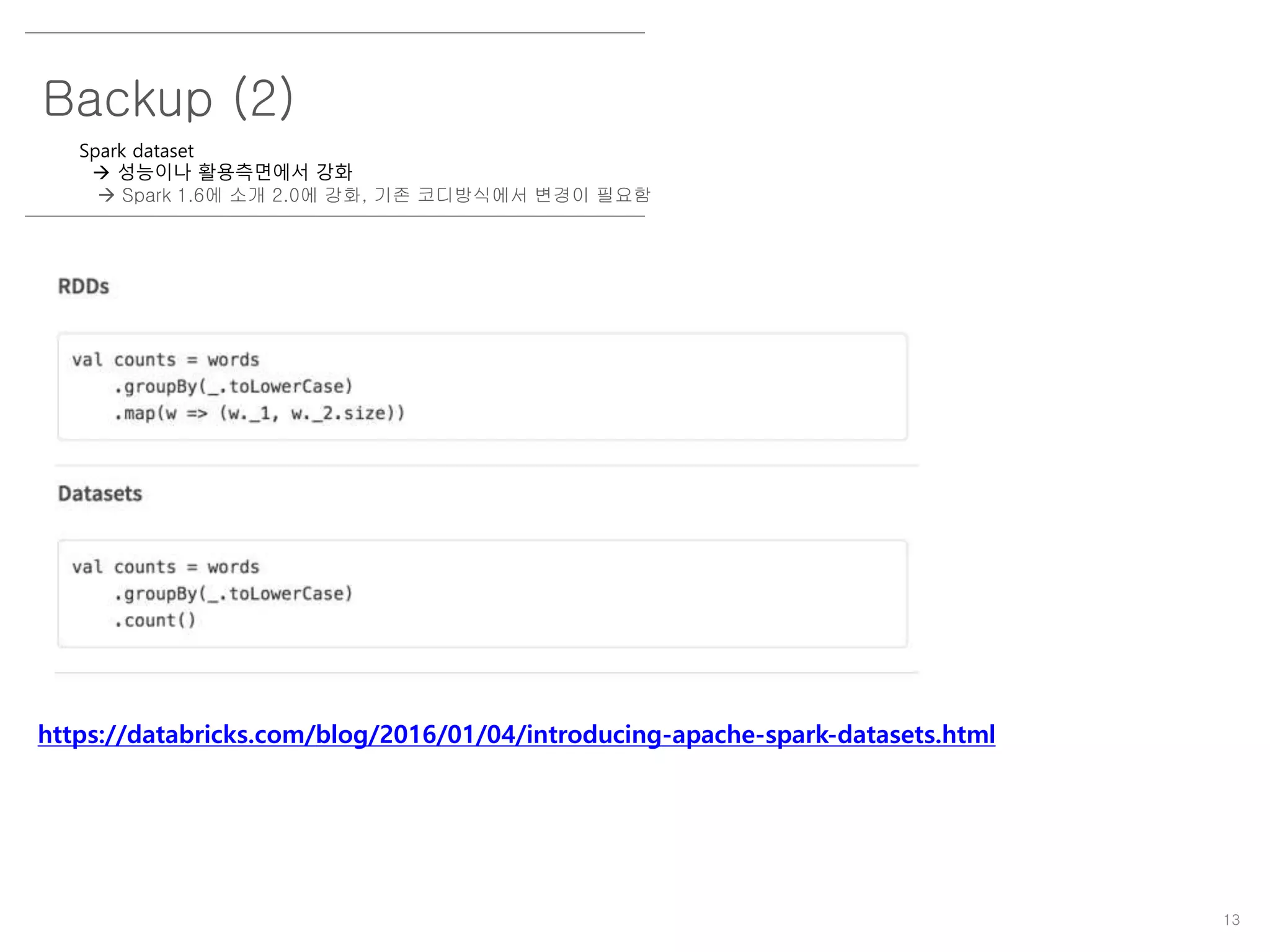
Backup (2)
Spark dataset
성능이나 활용측면에서 강화
Spark 1.6에 소개 2.0에 강화, 기존 코디방식에서 변경이 필요함
https://databricks.com/blog/2016/01/04/introducing-apache-spark-datasets.html



























![[D2 COMMUNITY] Spark User Group - 스파크를 통한 딥러닝 이론과 실제](https://cdn.slidesharecdn.com/ss_thumbnails/520160211-160307085845-thumbnail.jpg?width=640&height=640&fit=bounds)



























![[2015 07-06-윤석준] Oracle 성능 최적화 및 품질 고도화 4](https://cdn.slidesharecdn.com/ss_thumbnails/2015-07-06-oracle4-150702090606-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

















