Hadoop Framework
▪ 하둡(Hadoop)이란
▪대용량 데이터를 분산 처리할 수 있는 자바 기반의 오픈소스 프레임워크
▪ 하둡(Hadoop)의 특징
▪ 오픈 소스 (Open Source)
▪ 선형적 확장 (Scale out)
▪ 장애 허용 시스템 (Fault-toleran)
▪ 분산 저장 (HDFS)
▪ 분산 처리 (MapReduce)
4.
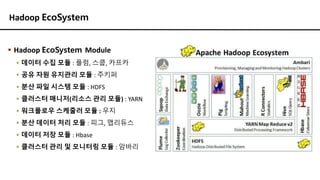
Hadoop EcoSystem
▪ HadoopEcoSystem Module
▪ 데이터 수집 모듈 : 플럼, 스쿱, 카프카
▪ 공유 자원 유지관리 모듈 : 주키퍼
▪ 분산 파일 시스템 모듈 : HDFS
▪ 클러스터 매니저(리소스 관리 모듈) : YARN
▪ 워크플로우 스케줄러 모듈 : 우지
▪ 분산 데이터 처리 모듈 : 피그, 맵리듀스
▪ 데이터 저장 모듈 : Hbase
▪ 클러스터 관리 및 모니터링 모듈 : 암바리
5.
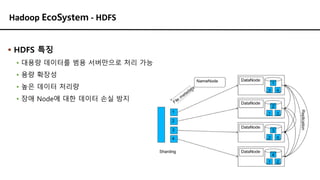
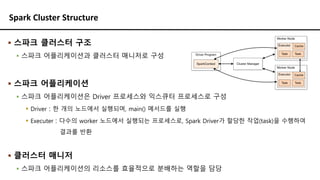
Hadoop EcoSystem -HDFS
▪ HDFS 특징
▪ 대용량 데이터를 범용 서버만으로 처리 가능
▪ 용량 확장성
▪ 높은 데이터 처리량
▪ 장애 Node에 대한 데이터 손실 방지
6.
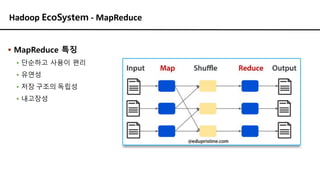
Hadoop EcoSystem -MapReduce
▪ MapReduce 특징
▪ 단순하고 사용이 편리
▪ 유연성
▪ 저장 구조의 독립성
▪ 내고장성
7.
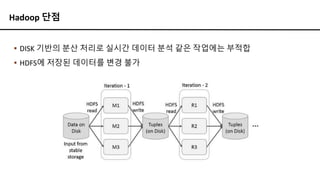
Hadoop 단점
▪ DISK기반의 분산 처리로 실시간 데이터 분석 같은 작업에는 부적합
▪ HDFS에 저장된 데이터를 변경 불가
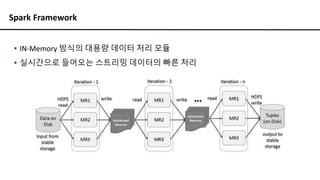
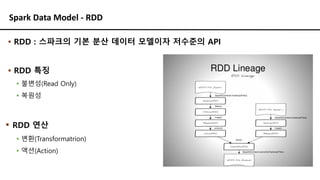
Spark Data Model- RDD
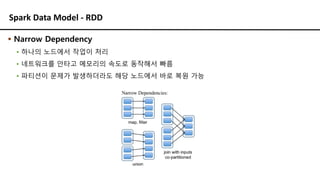
▪ Narrow Dependency
▪ 하나의 노드에서 작업이 처리
▪ 네트워크를 안타고 메모리의 속도로 동작해서 빠름
▪ 파티션이 문제가 발생하더라도 해당 노드에서 바로 복원 가능
14.
Spark Data Model- RDD
▪ Wide Dependency
▪ 여러 노드에서 작업이 처리
▪ 네트워크를 타고 셔플 단계를 거치기 때문에 느림
▪ 파티션이 문제가 발생하면 복원 비용이 비쌈
15.
Spark Data Model- RDD
▪ RDD 생성 방법
▪ 메모리에 생성된 데이터를 이용
▪ rdd = sc.parallelize([ ... ])
▪ 로컬 파일시스템이나 HDFS 등을 읽어서 생성
▪ rdd = sc.textFile(“PATH”)
▪ 기존 RDD로부터 또 다른 RDD 생성
▪ rdd1 = rdd.map(lambda s: s.upper())
16.
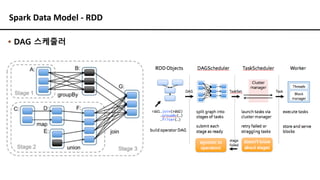
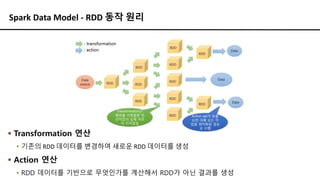
Spark Data Model- RDD 동작 원리
▪ Transformation 연산
▪ 기존의 RDD 데이터를 변경하여 새로운 RDD 데이터를 생성
▪ Action 연산
▪ RDD 데이터를 기반으로 무엇인가를 계산해서 RDD가 아닌 결과를 생성
17.
Spark Data Model- RDD Transformation 연산자의 종류, Action 연산자의 종류
▪ 대표적인 Transformation 연산자의 종류
▪ 대표적인 Action 연산자의 종류
18.
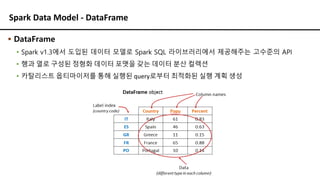
Spark Data Model- DataFrame
▪ DataFrame
▪ Spark v1.3에서 도입된 데이터 모델로 Spark SQL 라이브러리에서 제공해주는 고수준의 API
▪ 행과 열로 구성된 정형화 데이터 포맷을 갖는 데이터 분산 컬렉션
▪ 카탈리스트 옵티마이저를 통해 실행된 query로부터 최적화된 실행 계획 생성
19.
Spark Data Model- DataFrame
▪ DataFrame 생성 방법
▪ 외부 데이터소스로부터 데이터프레임 생성
▪ Dataset<Row> df = spark.read().json("examples/src/main/resources/people.json");
▪ 기존 RDD 및 로컬 컬렉션으로부터 데이터프레임 생성
▪ Dataset<ROW> ds = spark.createDataFrame(객체 List, 객체의 타입);
20.
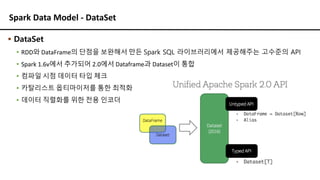
Spark Data Model- DataSet
▪ DataSet
▪ RDD와 DataFrame의 단점을 보완해서 만든 Spark SQL 라이브러리에서 제공해주는 고수준의 API
▪ Spark 1.6v에서 추가되어 2.0에서 Dataframe과 Dataset이 통합
▪ 컴파일 시점 데이터 타입 체크
▪ 카탈리스트 옵티마이저를 통한 최적화
▪ 데이터 직렬화를 위한 전용 인코더
21.
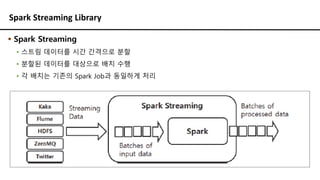
Spark Streaming Library
▪Spark Streaming
▪ 스트림 데이터를 시간 간격으로 분할
▪ 분할된 데이터를 대상으로 배치 수행
▪ 각 배치는 기존의 Spark Job과 동일하게 처리
22.
Spark Streaming Library
▪Streaming Context 생성
▪ Streaming Context을 사용하기 위해서 가장 먼저 생성하는 인스턴스
▪ 어떤 주기로 배치 처리를 수행할지에 대한 정보를 함께 제공
▪ SparkConf나 SparkContext를 이용해서 생성
// 스트리밍 컨텍스트 생성
SparkConf conf = new SparkConf().setAppName("ex4").setMaster("local[2]");
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(10));
// + 소켓을 통한 Dstream 생성
JavaReceiverInputDStream<String> lines = jssc.socketTextStream("localhost", 9999);
23.
Spark Streaming Library
▪DStream
▪ 스파크 스트리밍에서 사용하는 고정되지 않고 끊임없이 생성되는 연속된 데이터를 나타내기
위한 새로운 데이터 모델
▪ 일정 시간마다 데이터를 모아서 RDD로 만들어줌
24.
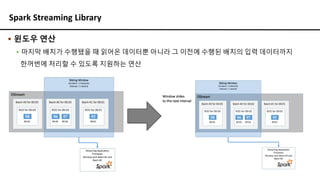
Spark Streaming Library
▪윈도우 연산
▪ 마지막 배치가 수행됐을 때 읽어온 데이터뿐 아니라 그 이전에 수행된 배치의 입력 데이터까지
한꺼번에 처리할 수 있도록 지원하는 연산
25.
Spark Streaming Library
//저장
ssc.checkpoint("저장 할 디렉터리 경로")
// 읽기
StreamingContext.getOrCreate("체크포인팅 경로", 스트리밍 컨텍스트 생성 함수)
▪ CheckPoint
▪ 장애가 발생할 경우 복구를 위해 사용하는 용어
▪ 메타데이터 체크포인팅
▪ 드라이버 프로그램을 복구하는 용도로 사용
▪ 데이터 체크포인팅
▪ 최종 상태의 데이터를 빠르게 복구하기 위한 용도로 사용
26.
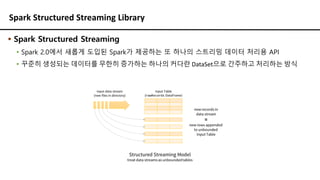
Spark Structured StreamingLibrary
▪ Spark Structured Streaming
▪ Spark 2.0에서 새롭게 도입된 Spark가 제공하는 또 하나의 스트리밍 데이터 처리용 API
▪ 꾸준히 생성되는 데이터를 무한히 증가하는 하나의 커다란 DataSet으로 간주하고 처리하는 방식





![Spark Data Model - RDD
▪ RDD 생성 방법
▪ 메모리에 생성된 데이터를 이용
▪ rdd = sc.parallelize([ ... ])
▪ 로컬 파일시스템이나 HDFS 등을 읽어서 생성
▪ rdd = sc.textFile(“PATH”)
▪ 기존 RDD로부터 또 다른 RDD 생성
▪ rdd1 = rdd.map(lambda s: s.upper())](https://image.slidesharecdn.com/apachespark-220425122949/85/Apache-Spark-15-320.jpg)


![Spark Streaming Library
▪ Streaming Context 생성
▪ Streaming Context을 사용하기 위해서 가장 먼저 생성하는 인스턴스
▪ 어떤 주기로 배치 처리를 수행할지에 대한 정보를 함께 제공
▪ SparkConf나 SparkContext를 이용해서 생성
// 스트리밍 컨텍스트 생성
SparkConf conf = new SparkConf().setAppName("ex4").setMaster("local[2]");
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(10));
// + 소켓을 통한 Dstream 생성
JavaReceiverInputDStream<String> lines = jssc.socketTextStream("localhost", 9999);](https://image.slidesharecdn.com/apachespark-220425122949/85/Apache-Spark-22-320.jpg)

































![[D2 COMMUNITY] Spark User Group - 스파크를 통한 딥러닝 이론과 실제](https://cdn.slidesharecdn.com/ss_thumbnails/520160211-160307085845-thumbnail.jpg?width=640&height=640&fit=bounds)











![[236] 카카오의데이터파이프라인 윤도영](https://cdn.slidesharecdn.com/ss_thumbnails/236-161025031702-thumbnail.jpg?width=640&height=640&fit=bounds)




