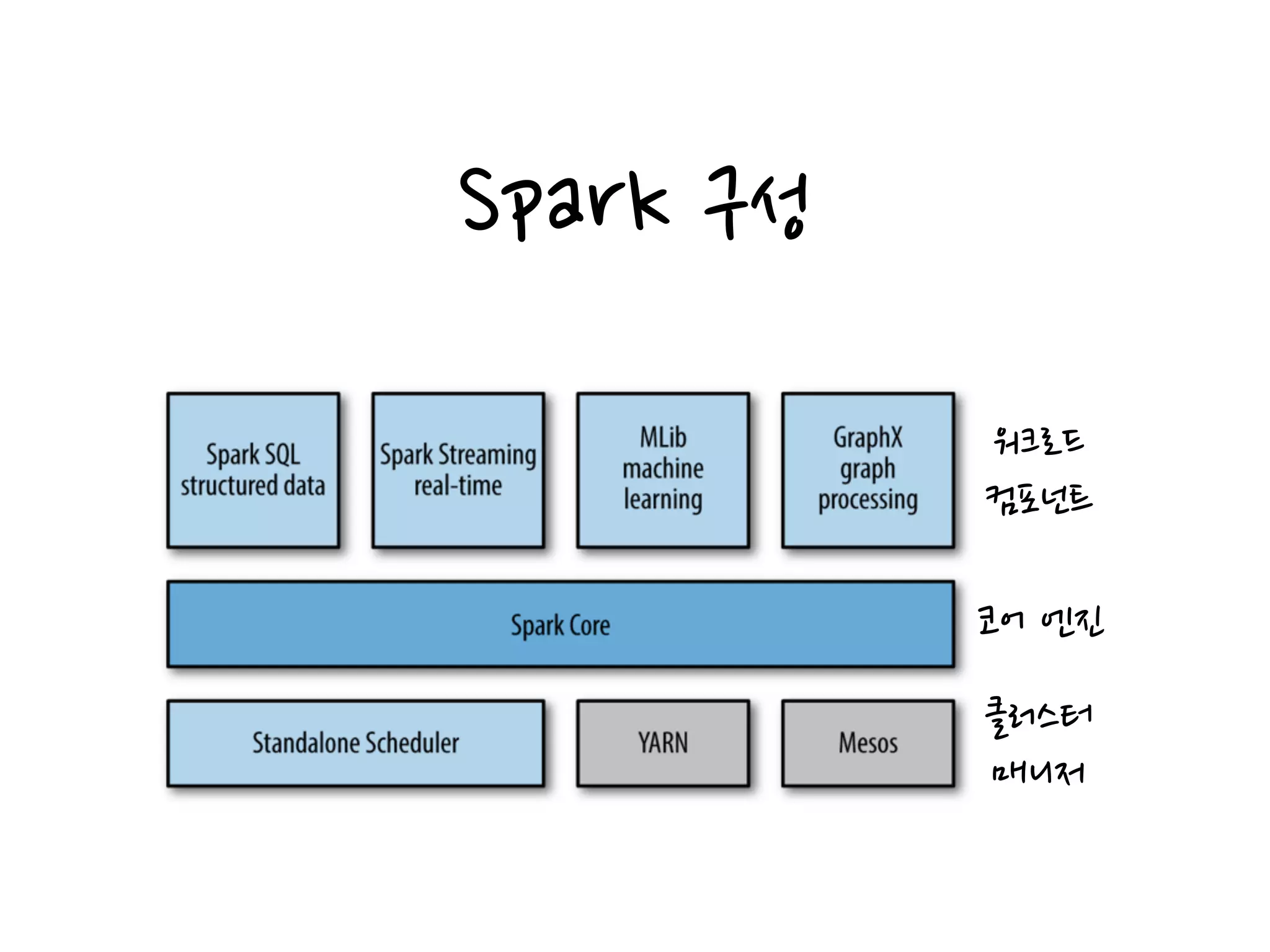
스파크 코어
•작업 스케쥴링,메모리 관리, 장애 복구, 스토리지 연동등 기본 기능으로 구성
•분산 데이터 세트(RDD)를 생성하고 조작하는 API 제공
클러스터 매니저
•효과적으로 성능을 확장 할 수 있도록 분산 노드를 관리
•지원: Yarn(하둡), Apache Mesos, Standalone Scheduler
5.
워크로드 컴포넌트
•스파크 SQL:정형 데이터
- 하이브 테이블, 파케이, JSON등 다양한 데이터 소스 지원
•스파크 스트리밍: 실시간 데이터 스트림
- 스파크 코어의 RDD API와 거의 일치하는 조작 API를 지원
- 저장된 데이터나 실시간 데이터를 동일하게 다룰수 있도록 함
•MLib: 머신러닝
- 분류, 회귀, 클러스터링, 협업 필터링 등 일반적인 머신러닝 지원
- 최적화 알고리즘과 같은 저수준의 핵심 러닝 기능 지원
•그래프 X: 그래프 라이브러리
- RDD API를 확장, 일반적인 그래프 알고리즘의 라이브러리 지원
line count -scala
scala> var lines = sc.textFile("README.md")
lines: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[1] at
textFile at <console>:21
scala> lines.count()
res0: Long = 98
scala> lines.first()
res1: String = # Apache Spark
<- RDD 생성
<- Action
<- Action
9.
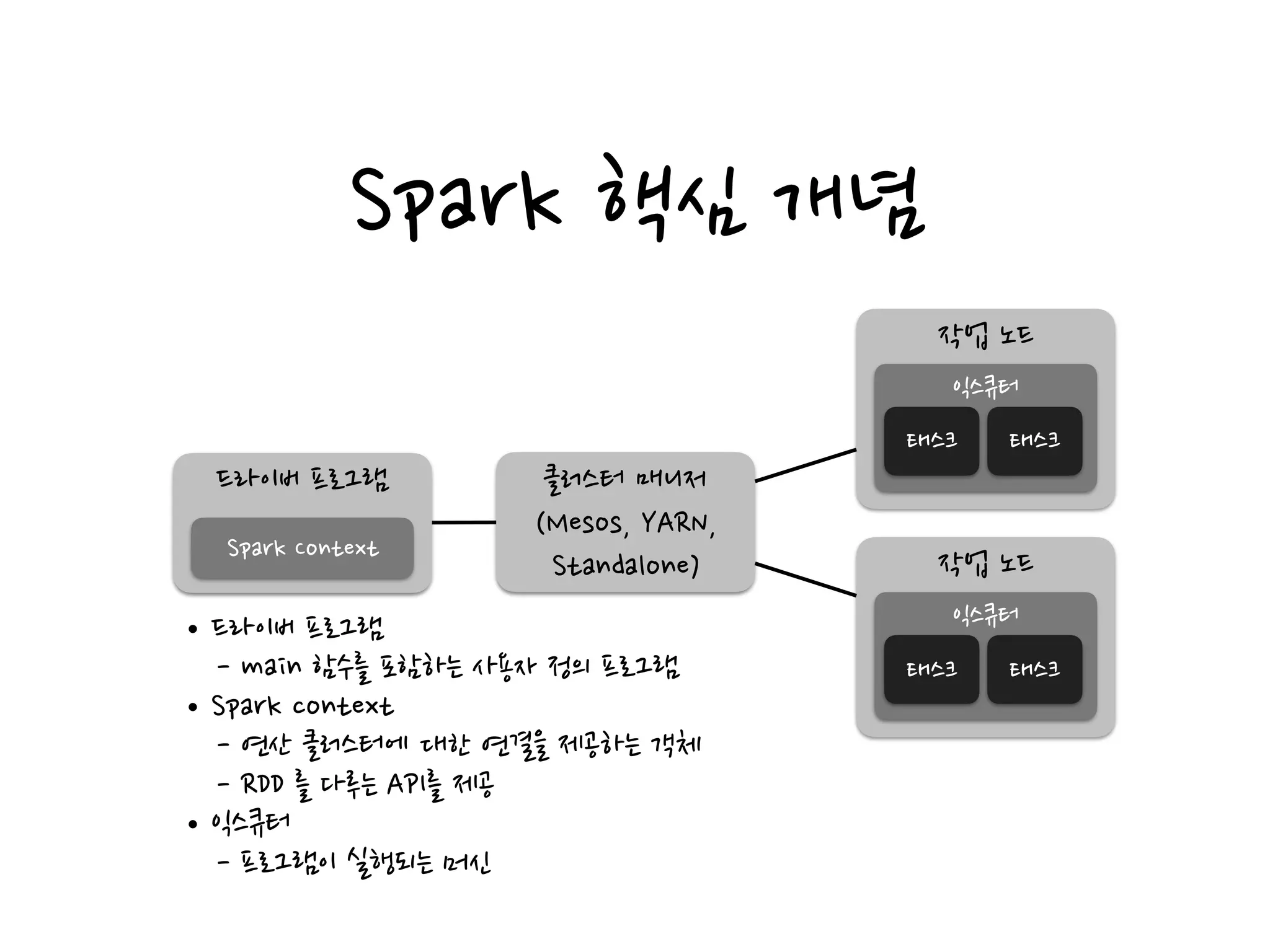
Spark 핵심 개념
드라이버프로그램
Spark Context
클러스터 매니저
(Mesos, YARN,
Standalone)
작업 노드
익스큐터
태스크 태스크
작업 노드
익스큐터
태스크 태스크
•드라이버 프로그램
- main 함수를 포함하는 사용자 정의 프로그램
•Spark context
- 연산 클러스터에 대한 연결을 제공하는 객체
- RDD 를 다루는 API를 제공
•익스큐터
- 프로그램이 실행되는 머신
10.
Filtering - scala
scala>var lines = sc.textFile("README.md")
lines: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[3] at textFile …
scala> var pythonLines = lines.filter(line => line.contains("Python"))
pythonLines: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[4] at filter …
scala> pythonLines.first()
res2: String = high-level APIs in Scala, Java, Python, and R, and an …
scala> pythonLines.count()
res3: Long = 3
<- RDD 생성
<- Action
<- Action
<- Transform
WordCount - 제출
<-실행 결과
•spark-submit 주요 옵션
- class: 사용자 정의 작업의 엔트리 클래스
- deploy-mode: cluster or client
- master: cluster일 경우 master의 주소
- conf: key-value







![line count - scala
scala> var lines = sc.textFile("README.md")
lines: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[1] at
textFile at <console>:21
scala> lines.count()
res0: Long = 98
scala> lines.first()
res1: String = # Apache Spark
<- RDD 생성
<- Action
<- Action](https://image.slidesharecdn.com/bat0daips2uxzsocksui-signature-d1b11e9fe22aca949389cf2046478ebe752cb6064e90f5c475ade132b274a5ba-poli-151026021448-lva1-app6892/75/Learning-spark-ch1-2-8-2048.jpg)
![Filtering - scala
scala> var lines = sc.textFile("README.md")
lines: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[3] at textFile …
scala> var pythonLines = lines.filter(line => line.contains("Python"))
pythonLines: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[4] at filter …
scala> pythonLines.first()
res2: String = high-level APIs in Scala, Java, Python, and R, and an …
scala> pythonLines.count()
res3: Long = 3
<- RDD 생성
<- Action
<- Action
<- Transform](https://image.slidesharecdn.com/bat0daips2uxzsocksui-signature-d1b11e9fe22aca949389cf2046478ebe752cb6064e90f5c475ade132b274a5ba-poli-151026021448-lva1-app6892/75/Learning-spark-ch1-2-10-2048.jpg)













![[D2 COMMUNITY] Spark User Group - 스파크를 통한 딥러닝 이론과 실제](https://cdn.slidesharecdn.com/ss_thumbnails/520160211-160307085845-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[D2 COMMUNITY] Spark User Group - 머신러닝 인공지능 기법](https://cdn.slidesharecdn.com/ss_thumbnails/1-160307085445-thumbnail.jpg?width=640&height=640&fit=bounds)












![[D2CAMPUS] Dotuator - 능동형 촉감 전달 점자 디스플레이 (BARAM)](https://cdn.slidesharecdn.com/ss_thumbnails/baram-161005063008-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D2 CAMPUS] 안드로이드 오픈소스 스터디자료 - java OOM, Reference API](https://cdn.slidesharecdn.com/ss_thumbnails/nexters6-reference-160927092413-thumbnail.jpg?width=640&height=640&fit=bounds)

![[D2 CAMPUS] 안드로이드 오픈소스 스터디자료 - OkHttp](https://cdn.slidesharecdn.com/ss_thumbnails/nexters6-okhttp-160927092147-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D2 CAMPUS] 안드로이드 오픈소스 스터디자료 - Http Request](https://cdn.slidesharecdn.com/ss_thumbnails/nexters3httprequest-160927090840-thumbnail.jpg?width=640&height=640&fit=bounds)









































