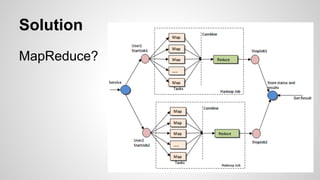
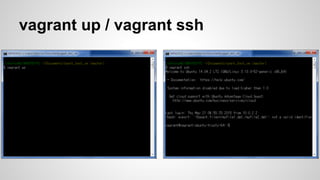
모든 일을 MapReduce화하라!
근데 이런 SQL을 어떻
게 MapReduce로 만들
지?
SELECT LAT_N, CITY,
TEMP_F
FROM STATS, STATION
WHERE MONTH = 7
AND STATS.ID =
STATION.ID
ORDER BY TEMP_F;
6.
모든 일을 MapReduce화하라!
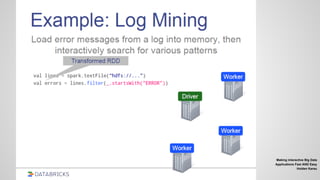
이런 Machine
learning/Data 분석 업
무는?
“지난 2007년부터 매월 나오
는 전국 부동산 실거래가 정
보에서 영향을 미칠 수 있는
변수 140개중에 의미있는 변
수 5개만 뽑아.”
“아, 마감은 내일이다.”
7.
코드도 이정도면 뭐?(단순히 단어세는 코드가…)
package org.myorg;
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class WordCount {
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException,
InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
}
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "wordcount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
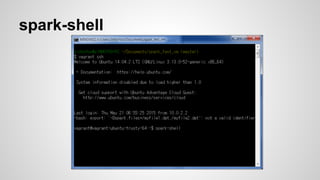
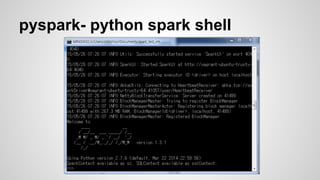
Wordcount : Scala
valf = sc.textFile("README.md")
===================
def textFile(path: String, minPartitions:
Int = defaultMinPartitions):RDD[String]
===================
Read a directory of text files from HDFS, a local file system
(available on all nodes), or any Hadoop-supported file
system URI.
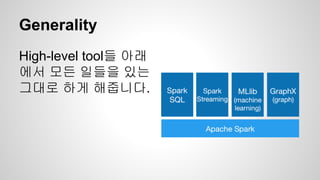
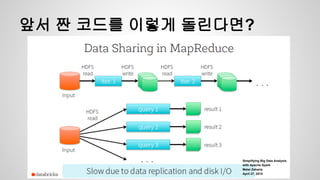
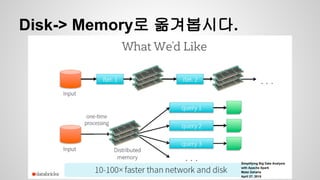
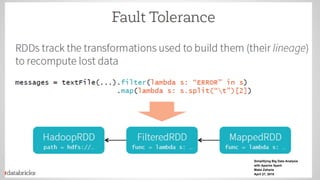
Spark Model
● 데이타를변환해가는 프로그램을 작성하는
것
● Resilient Distributed Dataset(RDDs)
○ Cluster로 전달할 memory나 disk에 저장될 object들
의 집합
○ 병렬 변환 ( map, filter…)등등으로 구성
○ 오류가 생기면 자동으로 재구성







![코드도 이정도면 뭐? (단순히 단어세는 코드가…)
package org.myorg;
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class WordCount {
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException,
InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
}
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "wordcount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}](https://image.slidesharecdn.com/spark-2-150825015944-lva1-app6892/85/Spark-2-7-320.jpg)






![Wordcount : Scala
val f = sc.textFile("README.md")
===================
def textFile(path: String, minPartitions:
Int = defaultMinPartitions):RDD[String]
===================
Read a directory of text files from HDFS, a local file system
(available on all nodes), or any Hadoop-supported file
system URI.](https://image.slidesharecdn.com/spark-2-150825015944-lva1-app6892/85/Spark-2-20-320.jpg)




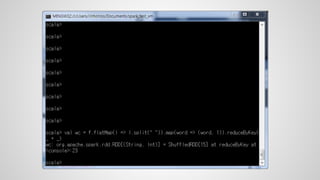
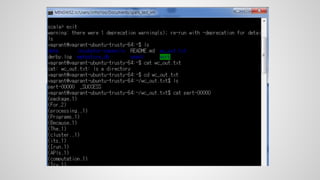
![Wordcount : Scala
scala>wc.take(20)
…….
finished: take at <console>:26, took 0.081425 s
res6: Array[(String, Int)] = Array((package,1), (For,2),
(processing.,1), (Programs,1), (Because,1), (The,1),
(cluster.,1), (its,1), ([run,1), (APIs,1), (computation,
1), (Try,1), (have,1), (through,1), (several,1), (This,2),
("yarn-cluster",1), (graph,1), (Hive,2), (storage,1))](https://image.slidesharecdn.com/spark-2-150825015944-lva1-app6892/85/Spark-2-26-320.jpg)











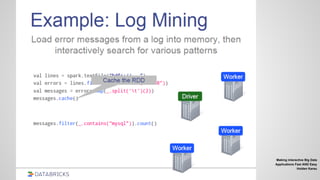
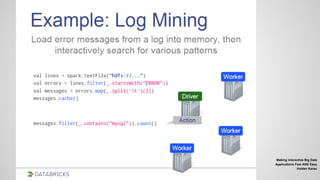






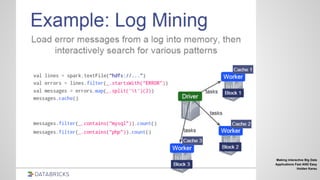
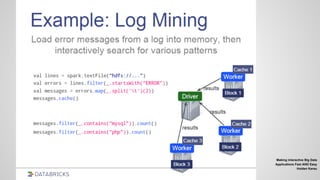








![MLib
Vectors, Matrices = RDD[Vector]
Iterative computation
points = sc.textFile(“data.txt”).map
(parsePoint)
model = KMeans.train(points, 10)
model.predict(newPoint)](https://image.slidesharecdn.com/spark-2-150825015944-lva1-app6892/85/Spark-2-61-320.jpg)




























![[D2 COMMUNITY] Spark User Group - 스파크를 통한 딥러닝 이론과 실제](https://cdn.slidesharecdn.com/ss_thumbnails/520160211-160307085845-thumbnail.jpg?width=640&height=640&fit=bounds)



![[246] foursquare데이터라이프사이클 설현준](https://cdn.slidesharecdn.com/ss_thumbnails/246foursquare-161025031706-thumbnail.jpg?width=640&height=640&fit=bounds)
















