-2-
¢ Apache Spark?
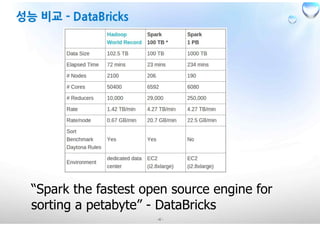
•Cluster computing platform designed to be fast and general-purpose
• Speed : RDD라는 방식을 통해 메모리를 사용을 극대화하여 interactive, streaming이
빠르게 처리
• Generality : 분산처리, 배치처리, interactive, streaming을 모두 같은 엔진위에서 처
리하도록 하며 각각의 작업의 연계가 쉽도록 되어 있음
• In addition : Python, Java, Scala + SQL + libraries
• 설계목표
• Low Latency Query -> Interactive
• Low Latency queries on live data -> Streaming
• Sophisticated data processing -> Machine Learning…
4.
-3-
¢ Scala로 개발시REPL이 제공되어 코딩을 하면서 실행 가능
¢ 코드가 간단함
Ex) (1 to 100 by 2).reduce((x, y) => x + y)
1부터 100까지 2단계 건너뛰면서 sum
Java RDD보다 code가 단순하여 유지보수하기 쉬움
val sqlContext = new SQLContext(ctx)
import sqlContext.implicits._
val lines = ctx.textFile(fileName, 256)
val data: RDD[GeoData] = lines2.map(_.toString().split(",")).map(
s => {
val env = GWUtil.decodeEnvelope(s(1))
GeoData(env.getMinX(), env.getMaxX(), env.getMinY(),env.getMaxY(), s(2))
}).cache()
data.count
-5-
0.0
50.0
100.0
150.0
200.0
250.0
1.1 km2 11km2 40.1
km2
222.4
km2
600.4
km2
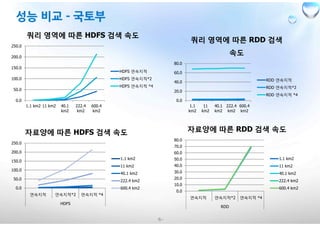
쿼리 영역에 따른 HDFS 검색 속도
HDFS 연속지적
HDFS 연속지적*2
HDFS 연속지적 *4
0.0
20.0
40.0
60.0
80.0
1.1
km2
11
km2
40.1
km2
222.4
km2
600.4
km2
쿼리 영역에 따른 RDD 검색
속도
RDD 연속지적
RDD 연속지적*2
RDD 연속지적 *4
0.0
50.0
100.0
150.0
200.0
250.0
연속지적 연속지적*2 연속지적 *4
HDFS
자료양에 따른 HDFS 검색 속도
1.1 km2
11 km2
40.1 km2
222.4 km2
600.4 km2
0.0
10.0
20.0
30.0
40.0
50.0
60.0
70.0
80.0
연속지적 연속지적*2 연속지적 *4
RDD
자료양에 따른 RDD 검색 속도
1.1 km2
11 km2
40.1 km2
222.4 km2
600.4 km2
7.
-6-
0.0
5.0
10.0
15.0
20.0
25.0
30.0
35.0
40.0
45.0
1.1 km2 11km2 40.1 km2 222.4 km2 600.4 km2
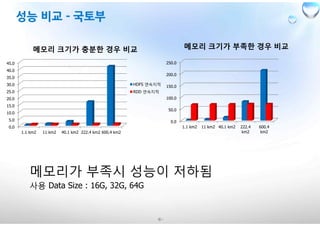
메모리 크기가 충분한 경우 비교
HDFS 연속지적
RDD 연속지적
0.0
50.0
100.0
150.0
200.0
250.0
1.1 km2 11 km2 40.1 km2 222.4
km2
600.4
km2
메모리 크기가 부족한 경우 비교
메모리가 부족시 성능이 저하됨
사용 Data Size : 16G, 32G, 64G
더블루션
분산파일 시스템
스케줄링 및리소스 관리 HDFS
분산처리 엔진
Pax Cache Manager
(remote + in-line)
Pax Data Access
(Pax Data Library)
Pax Compiler
Pax Requests
(view, histograms,
cluster, relationships)
Pax RDDs
(projection, filter,
co group hash joins )
Pax AnswerSet Manager
ODBC, JDBC, Web services 등
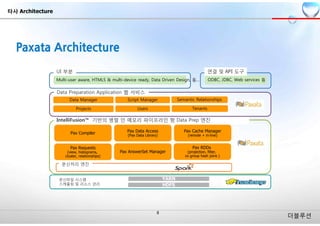
IntelliFusion™ 기반의 병렬 인 메모리 파이프라인 형 Data Prep 엔진
Data Manager Script Manager Semantic Relationships
Projects Users Tenants
Data Preparation Application 웹 서비스
연결 및 API 도구
Multi-user aware, HTML5 & multi-device ready, Data Driven Design, 등…
UI 부분
YARN
타사 Architecture
더블루션
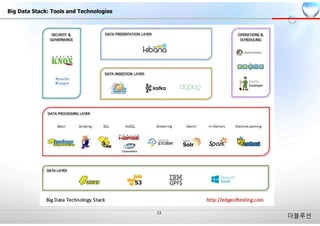
빅데이터 기술 동향
연도
시장규모
(억원)
주요시장 동향
2015 2,623
•Bigdata 시장 활성화를 위한 정부 투자 규모가 698억 원으로 증가
•기업 스스로의 의지에 기반한 Bigdata 투자는 여전히 소극적이나 이전 연도와 비교하여 활용 건
수가 확대되고 관심도 또한 증가세
•2014~2015년은 수요(고객)자들의 빅데이터 유용성 인식의 확대, 파일럿 프로젝트 확대, DW/BI
업무 고도화, 자사와 관련하여 유관 사례 스터디 및 참조 등이 나타나는 시기
2016 3,432
•Bigdata 활용에 대한 파일럿 프로젝트가 마무리되면서, Bigdata 분석 시스템 구축이 확대될 전
망
•IoT 및 Bigdata 활용, 성공 사례가 나타나고 데이터 매쉬업이 활발해지면서 Bigdata 관련 투자
또한 활기를 띨 것으로 전망
•업종별 리더십을 가진 기업의 활용 사례가 하위 경쟁 업체의 투자를 이끌어낼 것으로 전망
•Bigdata 플랫폼, 시스템 구축뿐만 아니라 Bigdata 서비스도 활성화 될 것으로 예상
2017 4,672
2018 6,497
•다양한 분석 알고리즘 및 업무 적용사례가 중소 기업의 도입을 견인할 것으로 예상
•데이터 거래, 데이터 매쉬업이 보다 활발해지면서 데이터 분석의 핵심은 빅데이터 기반의 분석
기술로 변화할 것으로 예측
[자료 : ‘15 빅데이터 시장조사, KRG]
12.
더블루션
¢ 국내
¤ RDBMS의 교체 수준에서 Hadoop적용
¤ 로그 및 데이터 수집
¤ 다양한 분야로의 데이터 수집
¢ 해외
¤ ML 적용으로 Business Modeling
¤ Etc
¢ 향후
¤ 수집된 데이터를 분석하는 쪽으로 진행 예상됨
¤ 이를 위해 ML 적용이 필수적이 됨
¤ 데이터 수집은 일정 시간이 지나면 일반화되어 기술적인 우위가 무의미해짐
빅데이터 기술 동향
13.
더블루션
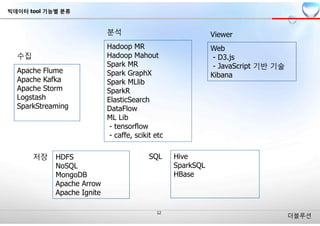
수집
분석 Viewer
Apache Flume
ApacheKafka
Apache Storm
Logstash
SparkStreaming
HDFS
NoSQL
MongoDB
Apache Arrow
Apache Ignite
Hadoop MR
Hadoop Mahout
Spark MR
Spark GraphX
Spark MLlib
SparkR
ElasticSearch
DataFlow
ML Lib
- tensorflow
- caffe, scikit etc
Web
- D3.js
- JavaScript 기반 기술
Kibana
저장 Hive
SparkSQL
HBase
SQL
빅데이터 tool 기능별 분류
더블루션
¢ Columnar Search
¤RDD내 빠른 검색을 위한 column 별 search
¤ 데이터 자료 구조
Row 단위로 저장되는 자료 구조에서 Column단위로 호출할 수 있는 자료 구조
¢ Machine Learning
¤ Data 분석을 위한 ML 적용
¤ ML Library를 개발하는 것이 아닌 ML Library 사용
¤ Column간 Join, Column data clustering
Spark 적용시 필히 고려해야 할 사항
-16-
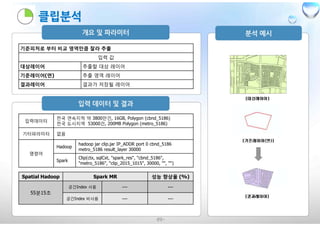
¢ 연속지적 :약 3800만건, 16GB, Polygon
¢ 서울 지역 건물 레이어 : 약 66만건, 170MB , Polygon
¢ 전국 도시지역 : 약 53000건, 200MB , Polygon
¢ 전국 직장인구 : 약 42만건, 120MB, Point
¢ 서울 지하철역 : 286건, Point
¢ 서울 지역 읍면동 행정 경계 : 467건 , 2MB , Polygon
¢ 임의 행정 경계 : 서울시 도심 읍면동 경계 - 98건 , Polygon
-18-
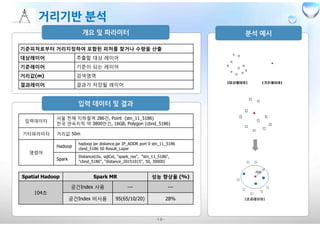
입력데이터
서울 전체 지하철역286건, Point (stn_11_5186)
전국 연속지적 약 3800만건, 16GB, Polygon (cbnd_5186)
기타파라미터 거리값 50m
명령어
Hadoop
hadoop jar distance.jar IP_ADDR port 0 stn_11_5186
cbnd_5186 50 Result_Layer
Spark
Distance(ctx, sqlCxt, "spark_res", "stn_11_5186",
"cbnd_5186", "distance_20151015", 50, 30000)
기준피처로부터 거리지정하여 포함된 피처를 찾거나 수량을 산출
대상레이어 추출할 대상 레이어
기준레이어 기준이 되는 레이어
거리값(m) 검색영역
결과레이어 결과가 저장될 레이어
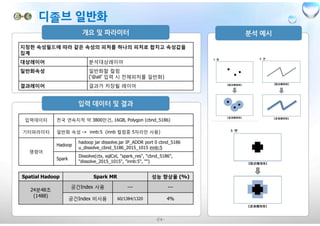
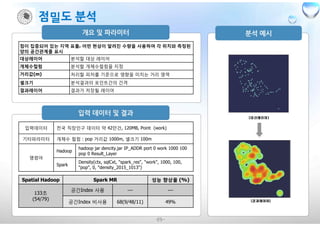
Spatial Hadoop Spark MR 성능 향상율 (%)
104초
공간Index 사용 --- ---
공간Index 비사용 95(65/10/20) 28%
20.
-19-
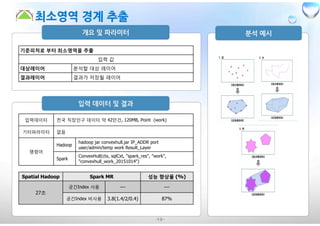
기준피처로 부터 최소영역을추출
입력 값
대상레이어 분석할 대상 레이어
결과레이어 결과가 저장될 레이어
입력데이터 전국 직장인구 데이터 약 42만건, 120MB, Point (work)
기타파라미터 없음
명령어
Hadoop
hadoop jar convexhull.jar IP_ADDR port
user/admin/temp work Result_Layer
Spark
ConvexHull(ctx, sqlCxt, "spark_res", "work",
"convexhull_work_20151014")
Spatial Hadoop Spark MR 성능 향상율 (%)
27초
공간Index 사용 --- ---
공간Index 비사용 3.8(1.4/2/0.4) 87%
21.
-20-
기준피처로 부터 비교영역만큼 잘라 추출
입력 값
대상레이어 추출할 대상 레이어
기준레이어(면) 추출 영역 레이어
결과레이어 결과가 저장될 레이어
입력데이터
전국 연속지적 약 3800만건, 16GB, Polygon (cbnd_5186)
전국 도시지역 53000건, 200MB Polygon (metro_5186)
기타파라미터 없음
명령어
Hadoop
hadoop jar clip.jar IP_ADDR port 0 cbnd_5186
metro_5186 result_layer 30000
Spark
Clip(ctx, sqlCxt, "spark_res", "cbnd_5186",
"metro_5186", "clip_2015_1015", 30000, "", "")
Spatial Hadoop Spark MR 성능 향상율 (%)
55분15초
공간Index 사용 --- ---
공간Index 비사용 --- ---
22.
-21-
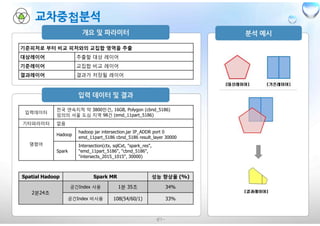
기준피처로 부터 비교피처와의 교집합 영역을 추출
대상레이어 추출할 대상 레이어
기준레이어 교집합 비교 레이어
결과레이어 결과가 저장될 레이어
입력데이터
전국 연속지적 약 3800만건, 16GB, Polygon (cbnd_5186)
임의의 서울 도심 지역 98건 (emd_11part_5186)
기타파라미터 없음
명령어
Hadoop
hadoop jar intersection.jar IP_ADDR port 0
emd_11part_5186 cbnd_5186 result_layer 30000
Spark
Intersection(ctx, sqlCxt, "spark_res",
"emd_11part_5186", "cbnd_5186",
"intersects_2015_1015", 30000)
Spatial Hadoop Spark MR 성능 향상율 (%)
2분24초
공간Index 사용 1분 35초 34%
공간Index 비사용 108(54/60/1) 33%
23.
-22-
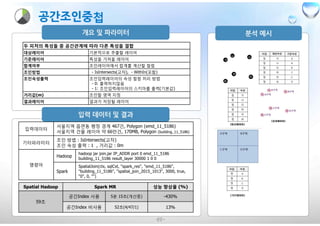
두 피처의 특성들중 공간관계에 따라 다른 특성을 결합
대상레이어 기본적으로 추출할 레이어
기준레이어 특성을 가져올 레이어
합계여부 조인레이어에서 합계를 계산할 컬럼
조인방법 - IsIntersects(교차), - WithIn(포함)
조인속성출력 조인입력레이어의 속성 컬럼 처리 방법
- 0: 출력하지않음
- 1: 조인입력레이어의 스키마를 출력(기본값)
거리값(m) 조인할 영역 지정
결과레이어 결과가 저장될 레이어
입력데이터
서울지역 읍면동 행정 경계 467건, Polygon (emd_11_5186)
서울지역 건물 레이어 약 66만건, 170MB, Polygon (building_11_5186)
기타파라미터
조인 방법 : IsIntersects(교차)
조인 속성 출력 : 1 , 거리값 : 0m
명령어
Hadoop
hadoop jar join.jar IP_ADDR port 0 emd_11_5186
building_11_5186 result_layer 30000 1 0 0
Spark
SpatialJoin(ctx, sqlCxt, "spark_res", "emd_11_5186",
"building_11_5186", "spatial_join_2015_1013", 3000, true,
“0", 0, "")
Spatial Hadoop Spark MR 성능 향상율 (%)
59초
공간Index 사용 5분 15초(개선중) -430%
공간Index 비사용 52초(4/47/1) 13%
24.
-23-
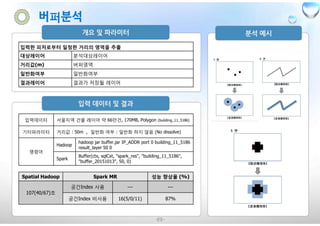
입력한 피처로부터 일정한거리의 영역을 추출
대상레이어 분석대상레이어
거리값(m) 버퍼영역
일반화여부 일반화여부
결과레이어 결과가 저장될 레이어
입력데이터 서울지역 건물 레이어 약 66만건, 170MB, Polygon (building_11_5186)
기타파라미터 거리값 : 50m , 일반화 여부 : 일반화 하지 않음 (No dissolve)
명령어
Hadoop
hadoop jar buffer.jar IP_ADDR port 0 building_11_5186
result_layer 50 0
Spark
Buffer(ctx, sqlCxt, "spark_res", "building_11_5186",
"buffer_20151013", 50, 0)
Spatial Hadoop Spark MR 성능 향상율 (%)
107(40/67)초
공간Index 사용 --- ---
공간Index 비사용 16(5/0/11) 87%
25.
-24-
지정한 속성필드에 따라같은 속성의 피처를 하나의 피처로 합치고 속성값을
집계
대상레이어 분석대상레이어
일반화속성 일반화할 컬럼
(‘@all’ 입력 시 전체피처를 일반화)
결과레이어 결과가 저장될 레이어
입력데이터 전국 연속지적 약 3800만건, 16GB, Polygon (cbnd_5186)
기타파라미터 일반화 속성 -> innb:5 (innb 컬럼중 5자리만 사용)
명령어
Hadoop
hadoop jar dissolve.jar IP_ADDR port 0 cbnd_5186
u_dissolve_cbnd_5186_2015_1015 innb:5
Spark
Dissolve(ctx, sqlCxt, "spark_res", "cbnd_5186",
"dissolve_2015_1015", "innb:5", "")
Spatial Hadoop Spark MR 성능 향상율 (%)
24분48초
(1488)
공간Index 사용 --- ---
공간Index 비사용 60/1384/1320 4%
26.
-25-
점이 집중되어 있는지역 표출, 어떤 현상이 알려진 수량을 사용하여 각 위치와 측정된
양의 공간관계를 표시
대상레이어 분석할 대상 레이어
개체수컬럼 분석할 개체수컬럼을 지정
거리값(m) 처리할 피처를 기준으로 영향을 미치는 거리 영역
셀크기 분석결과의 포인트간의 간격
결과레이어 결과가 저장될 레이어
입력데이터 전국 직장인구 데이터 약 42만건, 120MB, Point (work)
기타파라미터 개체수 컬럼 : pop 거리값 1000m, 셀크기 100m
명령어
Hadoop
hadoop jar dencity.jar IP_ADDR port 0 work 1000 100
pop 0 Result_Layer
Spark
Density(ctx, sqlCxt, "spark_res", "work", 1000, 100,
"pop", 0, "density_2015_1013")
Spatial Hadoop Spark MR 성능 향상율 (%)
133초
(54/79)
공간Index 사용 --- ---
공간Index 비사용 68(9/48/11) 49%
27.
-26-
같은 값이 있는피처를 분석하여 높은값(핫스팟)과 낮은값(콜드팟)의 통계적으로 특별
한지점을 분석
대상레이어(점) 분석할 대상 레이어
대상컬럼 분석할 값을 가진 컬럼명 (반드시 Integer, Double 속성의 컬럼)
가중치계산 거리 가중치 계산 방법
- FIXED_DISTANCE_BAND
- INVERSE_DISTANCE
거리계산 거리 계산 방법
- EUCLIDIAN_DISTANCE(기본값)
- MANHATTAN_DISTANCE
거리값(m) 거리값
결과레이어 결과가 저장될 레이어
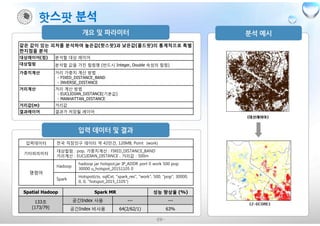
Spatial Hadoop Spark MR 성능 향상율 (%)
133초
(173/79)
공간Index 사용 --- ---
공간Index 비사용 64(2/62/1) 63%
입력데이터 전국 직장인구 데이터 약 42만건, 120MB, Point (work)
기타파라미터
대상컬럼 : pop, 가중치계산 : FIXED_DISTANCE_BAND
거리계산 : EUCLIDIAN_DISTANCE , 거리값 : 500m
명령어
Hadoop
hadoop jar hotspot.jar IP_ADDR port 0 work 500 pop
30000 u_hotspot_20151105 0
Spark
Hotspot(ctx, sqlCxt, "spark_res", "work", 500, "pop", 30000,
0, 0, "hotspot_2015_1105“)
28.
-27-
인접한 피처들의 유사성측정
대상레이어(점) 분석할 대상 레이어
대상컬럼 분석할 값을 가진 컬럼명 (반드시 Integer, Double 속성의 컬럼)
가중치계산 거리 가중치 계산 방법
- FIXED_DISTANCE_BAND
- INVERSE_DISTANCE
- INVERSE_DISTANCE_SQUARED
거리계산 거리 계산 방법
- EUCLIDIAN_DISTANCE(기본값)
- MANHATTAN_DISTANCE
거리값(m) 거리값
결과레이어 결과가 저장될 레이어
Spatial Hadoop Spark MR 성능 향상율 (%)
162초
공간Index 사용 --- ---
공간Index 비사용 56(3/53/0) 65%
입력데이터 전국 직장인구 데이터 약 42만건, 120MB, Point (work)
기타파라미터
대상컬럼 : pop, 가중치계산 : FIXED_DISTANCE_BAND
거리계산 : EUCLIDIAN_DISTANCE , 거리값 : 30m
명령어
Hadoop
hadoop jar autoc.jar IP_ADDR port 0 work
u_autocorrelation_20151105 30 pop 30000 0
Spark
Hotspot(ctx, sqlCxt, "spark_res", "work",
"autocorrelation_2015_1105", 30, "pop", 30000, 0, 0)
29.
더블루션
¢ 기존 Hadoop으로구현된 System의 속도 개선을 위해 Spark을 도입
메모리에 되어서 처리되어 빠름
100배 (메모리), 10배 (디스크) – Spark Homepage
질문 : 프로젝트에 spark 를 도입했던 이유
30.
더블루션
HDFS
Spark 1.5.2
Spatial Library
ExternalInterface
Third Part Library
Query
MR lib (distance, … etc)
Geo Library
Common
¢ Hadoop Base에서 연산만 Spark을 이용함
¢ S/W Architecture
프로젝트에 적용된 spark 의 아키텍처는 어떤 형태이며 수집/적재/처리에 있어서
기존 Hadoop Base 의 아키텍처와 어떤 차이점이 있는지?
31.
더블루션
¢ GIS 기반의솔루션이라서 배치성 수집.
¢ 실시간 수집을 할 수 없는 상황이었음
원천 데이터 수집 : 배치 성 수집 또는 실시간 수집 둘 중 어떤 것을 사용했는지?
더블루션
¢ 근본적인 해결책없음
¢ Hadoop은 제일 작은 파일 size의 Default가 128M
¢ 값을 조정하면 남는 공간 확보되나 MR시 부하 증가함
¢ 작은 파일을 만들지 않아야 합니다.
¢ 큰 파일은 HDFS, 작은 파일은 Memory
- Spark에서는 Broadcast로 각 Job별로 공유해서 사용함
Spark에서는 외부 배포를 위해서만 파일로 저장하고 항상 메모리에 data가
있음
작은 HDFS 파일 처리
34.
더블루션
¢ Spark에서 oozie를사용하지 않고 모듈별로 작업을 함
¢ 관련 Scala Class를 만들고 이를 한 곳에서 호출하면 사용함
¢ Scala Coding으로 처리함
Job Batch 처리




![-3-
¢ Scala로 개발시 REPL이 제공되어 코딩을 하면서 실행 가능
¢ 코드가 간단함
Ex) (1 to 100 by 2).reduce((x, y) => x + y)
1부터 100까지 2단계 건너뛰면서 sum
Java RDD보다 code가 단순하여 유지보수하기 쉬움
val sqlContext = new SQLContext(ctx)
import sqlContext.implicits._
val lines = ctx.textFile(fileName, 256)
val data: RDD[GeoData] = lines2.map(_.toString().split(",")).map(
s => {
val env = GWUtil.decodeEnvelope(s(1))
GeoData(env.getMinX(), env.getMaxX(), env.getMinY(),env.getMaxY(), s(2))
}).cache()
data.count](https://image.slidesharecdn.com/403112f3-e14c-4187-8aa8-89a6e55eff57-161109012048/85/Spark_Overview_qna-4-320.jpg)


![더블루션
빅데이터 기술 동향
연도
시장규모
(억원)
주요 시장 동향
2015 2,623
•Bigdata 시장 활성화를 위한 정부 투자 규모가 698억 원으로 증가
•기업 스스로의 의지에 기반한 Bigdata 투자는 여전히 소극적이나 이전 연도와 비교하여 활용 건
수가 확대되고 관심도 또한 증가세
•2014~2015년은 수요(고객)자들의 빅데이터 유용성 인식의 확대, 파일럿 프로젝트 확대, DW/BI
업무 고도화, 자사와 관련하여 유관 사례 스터디 및 참조 등이 나타나는 시기
2016 3,432
•Bigdata 활용에 대한 파일럿 프로젝트가 마무리되면서, Bigdata 분석 시스템 구축이 확대될 전
망
•IoT 및 Bigdata 활용, 성공 사례가 나타나고 데이터 매쉬업이 활발해지면서 Bigdata 관련 투자
또한 활기를 띨 것으로 전망
•업종별 리더십을 가진 기업의 활용 사례가 하위 경쟁 업체의 투자를 이끌어낼 것으로 전망
•Bigdata 플랫폼, 시스템 구축뿐만 아니라 Bigdata 서비스도 활성화 될 것으로 예상
2017 4,672
2018 6,497
•다양한 분석 알고리즘 및 업무 적용사례가 중소 기업의 도입을 견인할 것으로 예상
•데이터 거래, 데이터 매쉬업이 보다 활발해지면서 데이터 분석의 핵심은 빅데이터 기반의 분석
기술로 변화할 것으로 예측
[자료 : ‘15 빅데이터 시장조사, KRG]](https://image.slidesharecdn.com/403112f3-e14c-4187-8aa8-89a6e55eff57-161109012048/85/Spark_Overview_qna-11-320.jpg)
























![[D2 COMMUNITY] Spark User Group - 스파크를 통한 딥러닝 이론과 실제](https://cdn.slidesharecdn.com/ss_thumbnails/520160211-160307085845-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[경북] I'mcloud information](https://cdn.slidesharecdn.com/ss_thumbnails/imcloudinformation-151105091525-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)



![[경북] I'mcloud opensight](https://cdn.slidesharecdn.com/ss_thumbnails/imcloudopensight-151105092004-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)







