빅데이터 분석의 시초
GFS(GoogleFile System) 논문(2003)
여러 컴퓨터를 연결하여 저장용량과 I/O성능을 Scale
이를 구현한 오픈소스 프로젝트 : Hadooop HDFS
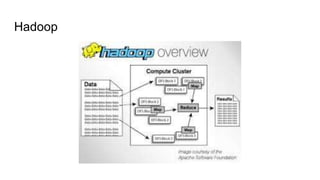
MapReduce 논문(2003)
Map과 Reduce연산을 조합하여 클러스터에서 실행, 큰 데이터를 처리
이를 구현한 오픈소스 프로젝트 : Hadoop MapReduce
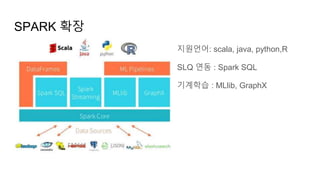
Spark
Apache Spark isa powerful open source processing engine buit around speed,
ease of use, and sophisticated analytics.
keywords
open source
processing engine
speed
ease of use
sophisticated analytics
9.
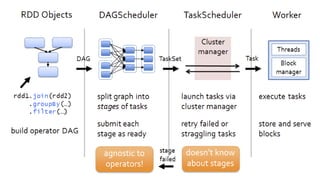
Spark
SPARK = RDD+ Interface
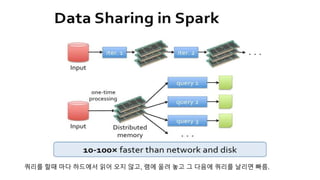
why RDD need?
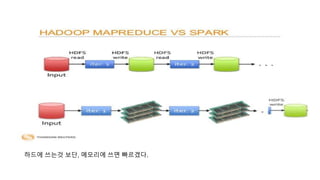
MapReduce의 약점
더 복잡하고, multi-stage한 처리
interactive하고 ad-hoc한 쿼리
위와 같은 부분을 해결하고자 함
Spark 설치
다운로드 :http://spark.apache.org/
설치
윈도우 :http://hopers.tistory.com/entry/%EC%8A%A4%ED%8C%8C%ED%81%AC-
%EC%84%A4%EC%B9%98-on-windows
azure : https://azure.microsoft.com/ko-kr/documentation/articles/hdinsight-apache-spark-zeppelin-notebook-
jupyter-spark-sql/
linux : http://gorakgarak.tistory.com/374
mac : not support. ( oracle java 1.8 jni issue )
17.
Spark 설치 2
단순하게…
java설치(없다면, 설치후 java_home 셋팅 필요)
stand alone mode
spark 배포판 다운로드(hadoop라이브러리가 있다면 하두 없는 버젼)
압축 풀고, 해당 경로의 conf로 이동.
spark-env.sh.template 복사 spark-env.sh
spark-env.sh 수정
“SPARK_MASTER_IP=localhost” 추가
18.
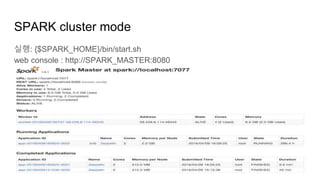
Spark 설치3
cluster 모드
sshkey 배포
ssh-keygen 실행
master 컴퓨터의 ~/.ssh/id_rsa.pub 파일을 각각의 클라이언트 컴퓨터의 ~/.ssh/authorized_keys에 추가.
spark 압축 해제 폴더에서 conf로 이동
클라이언트 설정 : slaves.template 복사 slaves, 노드를 구성하는 모든 컴퓨터의 ip입력.
spark-env.sh.template 복사 spark-env.sh 다음 사항 설정
SPARK_MASTER_IP = master IP
SPARK_MASTER_PORT = 7077
위의 모든 항목을 노드내의 모든 컴퓨터에 동일하게 설정.
19.
SPARK 실행
환경변수 설정
exportSPARK_HOME={$SPARK_HOME}
cluster 모드
실행
{$SPARK_HOME}/sbin/start-all.sh
중지
{$SPARK_HOME}/sbin/stop-all.sh
scala console 실행
{$SPARK_HOME}/bin/spark-shell.sh
python console 실행
{$SPARK_HOME}/bin/pysaprk
R console 실행
{$SPARK_HOME}/bin/sparkR
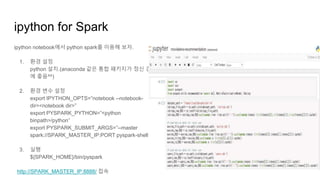
ipython for Spark
ipythonnotebook에서 python spark를 이용해 보자.
1. 환경 설정
python 설치.(anaconda 같은 통합 패키지가 정신 건강
에 좋음^^)
2. 환경 변수 설정
export IPYTHON_OPTS=”notebook --notebook-
dir=<notebook dir>”
export PYSPARK_PYTHON=”<python
binpath>/python”
export PYSPARK_SUBMIT_ARGS=”--master
spark://SPARK_MASTER_IP:PORT pyspark-shell”
3. 실행
${SPARK_HOME}/bin/pyspark
http://SPARK_MASTER_IP:8888/ 접속
22.
scala ipython forSPARK
ipython에서 python으로 spark 쓰면 좋은데…
ipython에서 scala로 spark이용 가능할까?
→ https://github.com/tribbloid/ISpark
설정 방법
ipython에 kernel을 추가.
.ipython/kernels/ispark 디렉토리를 추가,
우측 그림과 같이 설정
개발 팁
spark restjob client
https://github.com/ywilkof/spark-jobs-rest-client
SPARK 서버는 내부적으로 REST Server를 내장.
이 REST Server을 통해 spark 동작 시킴.
주요 설정
외부 jar 사용하기(주로 jdbc)
driver 실행시 추가 : -Dspark.driver.extraClassPath = “jar 경로”
executor 실행시 추가 : -Dspark.executor.extraClassPath=”jar 경로"
core제한
-Dspark.cores.max=”max” -1 이 설정이 없을 경우 클라우드 모드에서 가용한 모든 코어를 투입
메모리 크기 설정
-Dspark.executor.memory=”memory size”



















![[NDC2015] 언제 어디서나 프로파일링 가능한 코드네임 JYP 작성기 - 라이브 게임 배포 후에도 프로파일링 하기](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2015jypv3-150529000151-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[244] 분산 환경에서 스트림과 배치 처리 통합 모델](https://cdn.slidesharecdn.com/ss_thumbnails/244-150915025618-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NDC 2014] 던전앤파이터 클라이언트 로딩 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/ndc201420140605-140604221309-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[261] 실시간 추천엔진 머신한대에 구겨넣기](https://cdn.slidesharecdn.com/ss_thumbnails/216-150915054828-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[225]빅데이터를 위한 분산 딥러닝 플랫폼 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/2251016final-171017052307-thumbnail.jpg?width=640&height=640&fit=bounds)

![[D2]thread dump 분석기법과 사례](https://cdn.slidesharecdn.com/ss_thumbnails/d2threaddump-150522063949-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

![[232] 성능어디까지쥐어짜봤니 송태웅](https://cdn.slidesharecdn.com/ss_thumbnails/232-161025013504-thumbnail.jpg?width=640&height=640&fit=bounds)




![[264] large scale deep-learning_on_spark](https://cdn.slidesharecdn.com/ss_thumbnails/246large-scaledeeplearningonspark-150915055051-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NDC2016] TERA 서버의 Modern C++ 활용기](https://cdn.slidesharecdn.com/ss_thumbnails/v09teramodernc20160425-160427044156-thumbnail.jpg?width=640&height=640&fit=bounds)
![[241] Storm과 Elasticsearch를 활용한 로깅 플랫폼의 실시간 알람 시스템 구현](https://cdn.slidesharecdn.com/ss_thumbnails/83713-150915040003-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)




![[2D4]Python에서의 동시성_병렬성](https://cdn.slidesharecdn.com/ss_thumbnails/2d4pythondeview2014-140929211011-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





![[D2 COMMUNITY] Spark User Group - 스파크를 통한 딥러닝 이론과 실제](https://cdn.slidesharecdn.com/ss_thumbnails/520160211-160307085845-thumbnail.jpg?width=640&height=640&fit=bounds)
















