Spark Intro
• In-memory기반 범용 클러스터 컴퓨팅 엔진
- 하둡 맵리듀스보다 100배 빠름(공홈에서 주장)
• Unified Engine
- batch/stream, SQL 및 Machine learning, Graph processing 제공
• 다양한 언어 지원
- Java, Scala, Python, R
• 여러 클러스터 매니저를 지원하여 다양한 환경에서 구동 가능
- Standalone, YARN, mesos 등
Why Spark Streaming?
데이터를실시간으로 바로 처리 하고 싶어요
“웹사이트를 모니터링할 수 없을까요?”
“이거 추가되거나 삭제되면 바로 반영해주세요”
“실시간 데이터로 머신러닝 모델을 학습시키고 싶어요”
“문제를 바로 알고 싶어요”
Website monitoring Fraud detection ML from streaming data
13.
Why Spark Streaming?
•Integration with Batch Processing
같은 프레임워크에서 배치와 스트리밍을 같이 처리하고 싶어요
“배치는 MapReduce, 스트리밍은 Storm…”
“유지 보수가 너무 어려워요 ㅠㅠ”
“배치를 쉽게 스트리밍으로 바꿀수 없을까요?”
14.
Why Spark Streaming?
•Integration with Batch Processing
같은 프레임워크에서 배치와 스트리밍을 같이 처리하고 싶어요
“배치는 MapReduce, 스트리밍은 Storm…”
“유지 보수가 너무 어려워요 ㅠㅠ”
“배치를 쉽게 스트리밍으로 바꿀수 없을까요?”
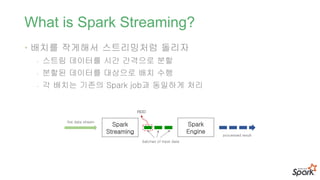
What is SparkStreaming?
• 배치를 작게해서 스트리밍처럼 돌리자
- 스트림 데이터를 시간 간격으로 분할
- 분할된 데이터를 대상으로 배치 수행
- 각 배치는 기존의 Spark job과 동일하게 처리
Spark
Streaming
live data stream
batches of input data
Spark
Engine
processed result
RDD
17.
Streaming Context
• Sparkstreaming을 사용하기 위해서 제일 먼저 생성하는 인스
턴스
- SparkContext, SparkSession과 비슷
• 어떤 주기로 배치 처리를 수행할지에 대한 정보를 함께 제공
• SparkConf나 SparkContext를 이용해 생성
18.
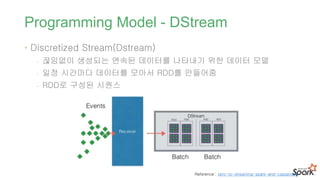
Programming Model -DStream
• Discretized Stream(Dstream)
- 끊임없이 생성되는 연속된 데이터를 나타내기 위한 데이터 모델
- 일정 시간마다 데이터를 모아서 RDD를 만들어줌
- RDD로 구성된 시퀀스
Reference : zero-to-streaming-spark-and-cassandra
19.
그림과 함께 보는예제
Spark
Streaming
live data stream
batches of input data
Spark
Engine
processed result
20.
그림과 함께 보는예제
Spark
Streaming
live data stream
batches of input data
Spark
Engine
processed result
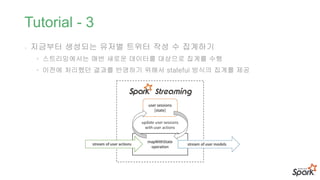
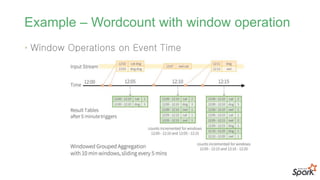
Example – Twitter데이터와 놀아보기
• 살펴볼 예제
- 초당 생성되는 트윗 수 세어보기
- 최근 10초동안 생성되는 트윗 중 가장 많이 사용되는 단어수를 매 초마
다 확인하기
- 지금부터 유저별 트위터 작성 수 집계하기
예제 저장소 : https://github.com/eoriented/spark-streaming-tutorial
Data source
• 지원하는데이터 소스
- Default data source
• Socket
• 파일 (HDFS 호환 파일 가능)
• RDD Queue
- Advanced data source (외부 연동 라이브러리)
• Kafka
• Flume
• Kinesis
• Twitter
- Receiver를 직접 구현
35.
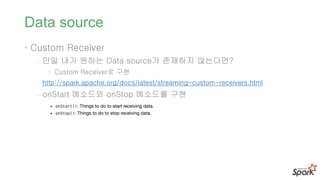
Data source
• CustomReceiver
- 만일 내가 원하는 Data source가 존재하지 않는다면?
• Custom Receiver로 구현
- http://spark.apache.org/docs/latest/streaming-custom-receivers.html
- onStart 메소드와 onStop 메소드를 구현
Fault tolerance
• CheckPoint
- Metadata checkpoint
• 드라이버의 장애 대응
- Data checkpoint
• 최종 상태의 데이터를 빠르게 복구하기 위한 용도
- 파일 시스템
• HDFS, S3, local FS(test용) 등이 사용 가능
38.
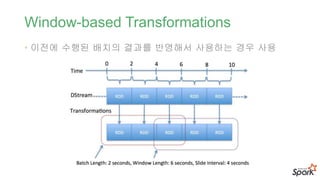
성능 고려사항
• 배치/ 윈도우 사이즈
- 500ms 가 적당
- 큰 배치로 시작하여 작은 사이즈로 낮춰가면서 배치 사이즈 결정 추천
• 병렬화
- 리시버 개수 늘리기
• 하나의 리시버가 받는게 아닌 여러 리시버가 받아서 처리하는게 효율적
- Repartitioning
• 입력 스트림의 파티션을 재설정하여 처리
• 메모리 튜닝
- GC 옵션 튜닝
- Spark.cleaner.ttl 옵션을 이용하여 RDD 제거 시간 조정
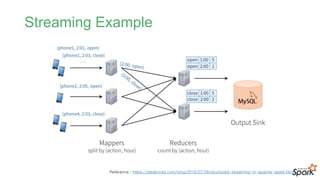
#41 기존 맵리듀스 패턴을 이용하여 스트리밍을 처리하는 방식의 예
- 사용자가 앱을 열때 open 이벤트를 보내고, 닫을 때 close 이벤트를 보내는 예제
#42 사용자가 앱을 열때 open 이벤트를 보내고, 닫을 때 close 이벤트를 보내는 예제
Consistency
open을 처리하는 reducer와 close를 담당하는 리듀서가 있을 때 open을 처리하는 리듀서가 close를 담당하는 리듀서보다 느린 경우 mysql에서는 open 보다 close가 더 많아질 수도 있어서 데이터의 일관성이 깨질 수 있음
Fault tolerance
Mapper나 리듀서가 죽는 경우는?
Out-of-order data
여러 출처의 데이터가 순서가 다른 경우 문제가 될 수 있음
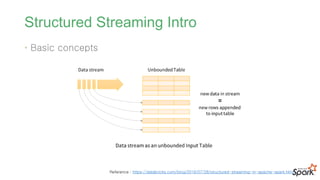
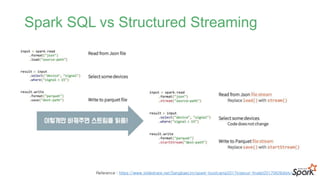
#44 입력 데이터의 스트림을 입력테이블로 간주해서 처리.
스트림에 도착하는 모든 데이터는 입력 테이블에 추가되는 새로운 row와 같이 처리
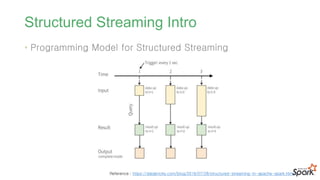
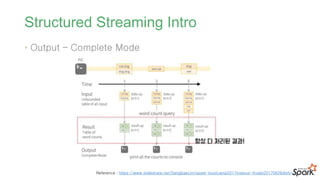
#45 결과를 Result Table에 업데이트 한다. 결과 테이블이 업데이트 될때마다 변경된 결과와 행을 외부 싱크에 기록해야 함
#48 결과를 Result Table에 업데이트 한다. 결과 테이블이 업데이트 될때마다 변경된 결과와 행을 외부 싱크에 기록해야 함
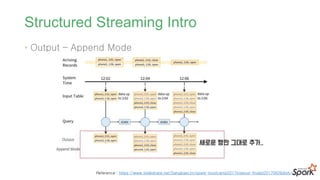
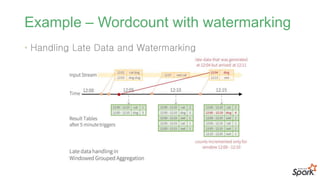
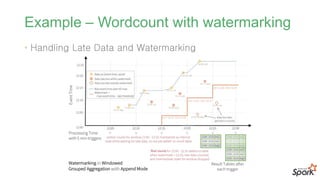
#57 늦게 들어오는 데이터를 어떻게 처리할 것인가?
한참 후에(하루, 일주일) 들어오는 데이터를 처리하기 위해서 기존 데이터를 계속 유지할 수 없음
한참 지난 후에 도달하는 데이터를 적절히 처리하기 위한 방법으로 워터마크 도입
이벤트의 유효기간을 설정하여 처리하는 방식입니다.
#58 해당 트리거가 발생하기 전에 인입된 모든 이벤트중에
가장 마지막에 발생된 이벤트 발생시각에서
미리 지정해둔 유효기간을 뺀 것으로 결정












































![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유 (2부)](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-2-180430180517-thumbnail.jpg?width=640&height=640&fit=bounds)

![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-1-180430181759-thumbnail.jpg?width=640&height=640&fit=bounds)
![[AWSKRUG&JAWS-UG Meetup #1] 태양광발전소 원격 감시 시스템의 대량데이터 해석【株式会社fusic】](https://cdn.slidesharecdn.com/ss_thumbnails/160526krugfusic-160526114434-thumbnail.jpg?width=640&height=640&fit=bounds)







![[113]apache zeppelin 이문수](https://cdn.slidesharecdn.com/ss_thumbnails/113apachezeppelin-161023163318-thumbnail.jpg?width=640&height=640&fit=bounds)




![[테크데이즈2015] 개발하기 바쁜데 푸시와 메시지큐는 있는거 쓸래요](https://cdn.slidesharecdn.com/ss_thumbnails/20151027techdaysazurepushandeventbus-160210062525-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Gaming on AWS] AWS와 함께 한 쿠키런 서버 Re-architecting 사례 - 데브시스터즈](https://cdn.slidesharecdn.com/ss_thumbnails/6-140305055030-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




![[236] 카카오의데이터파이프라인 윤도영](https://cdn.slidesharecdn.com/ss_thumbnails/236-161025031702-thumbnail.jpg?width=640&height=640&fit=bounds)






![[D2 COMMUNITY] Spark User Group - 스파크를 통한 딥러닝 이론과 실제](https://cdn.slidesharecdn.com/ss_thumbnails/520160211-160307085845-thumbnail.jpg?width=640&height=640&fit=bounds)







![[215]네이버콘텐츠통계서비스소개 김기영](https://cdn.slidesharecdn.com/ss_thumbnails/215-161025030904-thumbnail.jpg?width=640&height=640&fit=bounds)

![[경북] I'mcloud information](https://cdn.slidesharecdn.com/ss_thumbnails/imcloudinformation-151105091525-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
