빅데이터분석의 시초
• GFS(GoogleFile System) 논문 (2003)
• 여러 컴퓨터를 연결하여 저장용량과 I/O성능을 scale
• 이를 구현한 오픈소스 프로젝트인 Hadoop HDFS
• MapReduce논문 (2004)
• Map과 Reduce연산을 조합하여 클러스터에서 실행, 큰 데이터를 처리
• 이를 구현한 오픈소스 프로젝트인 Hadoop MapReduce
4.
public class WordCount{
public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws
IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}
Word count in MapReduce (Java)
5.
빅데이터 분석의 시초(2)
• Hive
• MapReduce 코드를 짜는건 괴롭다
• 쿼리로 MapReduce의 거의 모든 기능을 표현할 수 있다!
• HDFS등에 있는 파일을 읽어들여 쿼리로 분석 수행
• HiveQL 을 작성하면 MapReduce 코드로 변환되어 실행
6.
그렇게 10년이 지나고,
지금까지도MapReduce와 Hive는 많이 사용되고 있는 빅데이터
기술입니다
MR, Hive에 도전하는 기술들
Impala, Pheonix, Pig, Tez 등등등등… 엄청 많다
7.
MapReduce / Hive장단점
• 장점
• 빅데이터 시대를 열어준 선구적인 기술
• 거대한 데이터를 안정적으로 처리
• 많은 사람들이 사용 중
• 단점
• 오래된 기술이다보니,
• 발전이 느리다
• 불편한점이 많다
8.
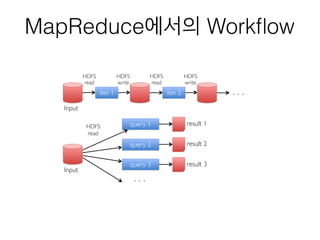
MapReduce의 문제점
• MapReduce는Map의 입출력 및 Reduce의 입출력을 매번
HDFS에 쓰고, 읽는다 - 느리다
• MapReduce코드는 작성하기 불편하다 - 좀더 좋은 인터페이스가
있으면 좋겠다
9.
Spark
• 핵심 개념:RDD (Resilient Distributed Dataset)
• 인터페이스: Scala
RDD
• Resilient DistributedDataset - 탄력적으로 분산된
데이터셋
• 클러스터에 분산된 메모리를 활용하여 계산되는 List
• 데이터를 어떻게 구해낼지를 표현하는 Transformation
을 기술한 Lineage(계보)를 interactive하게 만들어
낸 후, Action을 통해 lazy하게 값을 구해냄
• 클러스터 중 일부의 고장 등으로 작업이 중간에 실패하
더라도, Lineage를 통해 데이터를 복구
Interface - Scala
•매우 간결한 표현이 가능한 언어
• REPL(aka Shell) 제공, interactive하게 데이터를 다루는것이 가
능
• Functional Programming이 가능하므로 MapReduce와 같은
functional한 개념을 표현하기에 적합함
15.
public class WordCount{
public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws
IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}
val file = spark.textFile("hdfs://...")
val counts = file.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")
Word count in Spark(Scala)
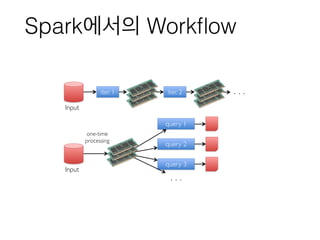
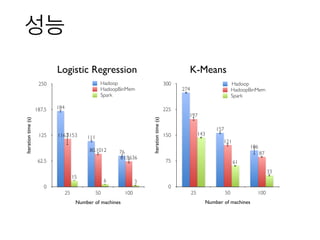
장점들
• 시간과 비용을아껴준다
• 수십대의 Hadoop Cluster를 10대 이하의 Cluster로 대체할 수 있다
• 수십분 기다려야 하던 작업이 1분만에 완료된다
• 작업 능률 향상
• MR 작업 코드 만들고, 패키징하고, submit하고 하던 복잡한 과정이,
shell에서 코드 한줄 치는것으로 대체된다
• 처음 접하는 사람도 배우기 쉽다
• 다양한 제품을 조합해야 했던 작업이 Spark으로 다 가능하다




![public class WordCount {
public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws
IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}
Word count in MapReduce (Java)](https://image.slidesharecdn.com/2015-04-23-spark-150423204538-conversion-gate01/85/Spark-4-320.jpg)







![public class WordCount {
public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws
IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}
val file = spark.textFile("hdfs://...")
val counts = file.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")
Word count in Spark(Scala)](https://image.slidesharecdn.com/2015-04-23-spark-150423204538-conversion-gate01/85/Spark-15-320.jpg)



















![[NDC 2018] Spark, Flintrock, Airflow 로 구현하는 탄력적이고 유연한 데이터 분산처리 자동화 인프라 구축](https://cdn.slidesharecdn.com/ss_thumbnails/jparktemp-180424105624-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D2 COMMUNITY] Spark User Group - 스파크를 통한 딥러닝 이론과 실제](https://cdn.slidesharecdn.com/ss_thumbnails/520160211-160307085845-thumbnail.jpg?width=640&height=640&fit=bounds)




































