Download to read offline



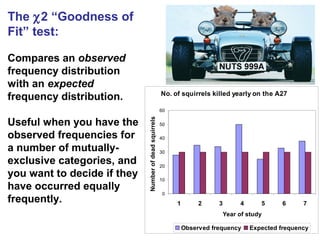




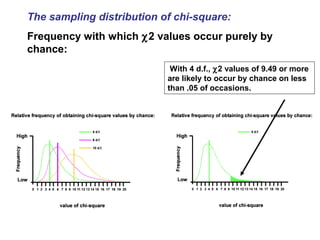


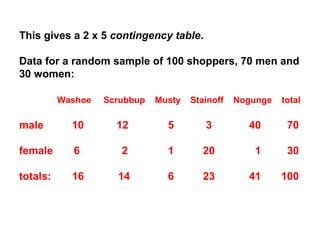
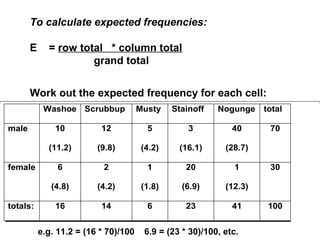



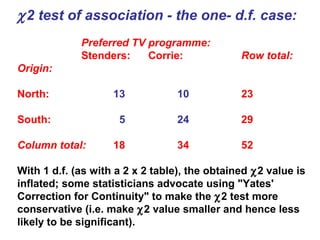



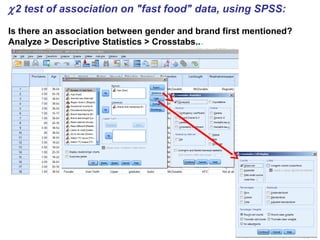
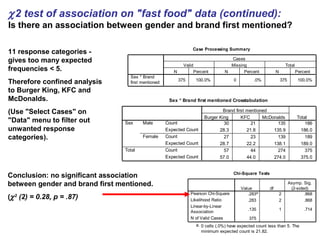

- Chi-squared (χ2) tests are used to analyze categorical data by comparing observed frequencies to expected frequencies. - The document provides examples of using the χ2 test to test if frequency distributions match expected distributions (goodness of fit test) and to test for associations between two categorical variables. - Key assumptions and considerations for χ2 tests are that observations must be independent and expected frequencies should not be too small.

































































