

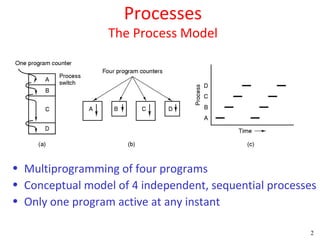



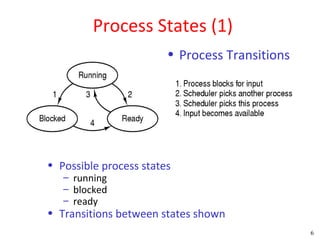
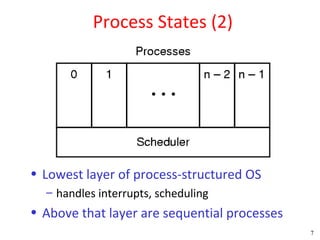



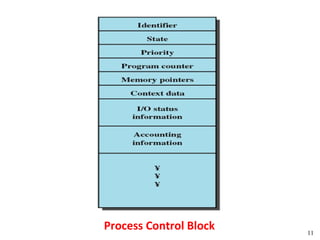
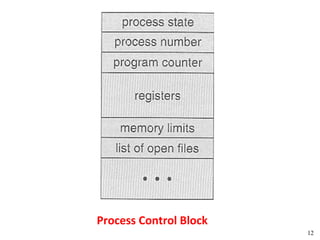
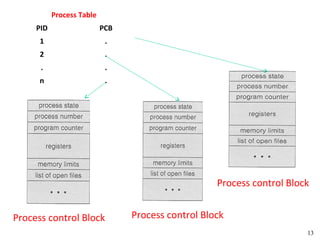
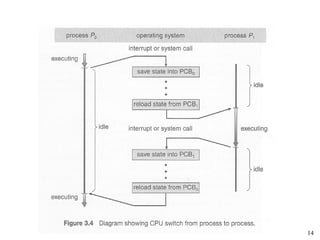
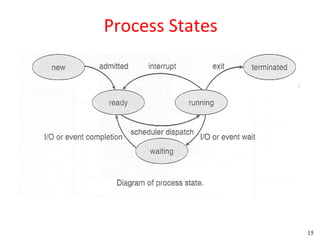

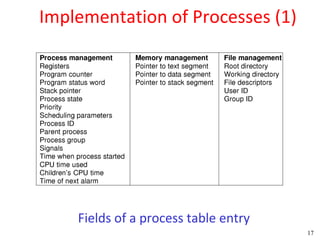




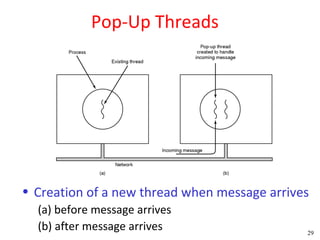
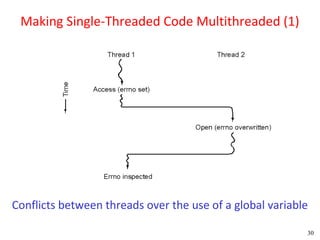
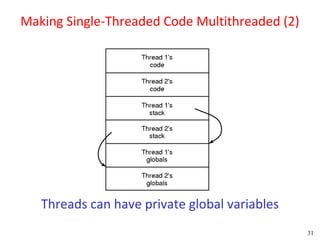



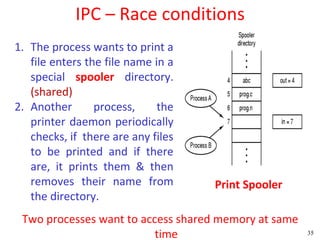
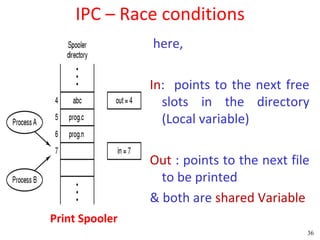
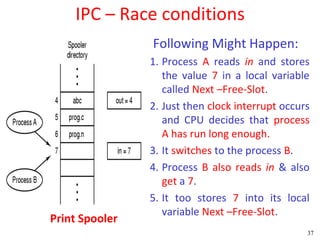
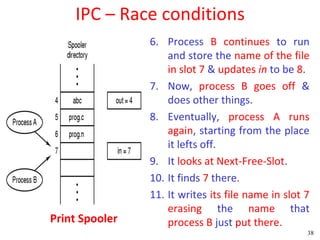













![Peterson's Solution
Let us see how this solution works.
1.Initially neither process is in its critical region.
2.Now process 0 calls enter_region.
3.It indicates its interest by setting its array element and sets turn
to 0.
4.Since process 1 is not interested, enter_region returns
immediately.
5.If process 1 now calls enter_region, it will hang there until
interested[0] goes to FALSE, an event that only happens when
process 0 calls leave_region to exit the critical region.](https://image.slidesharecdn.com/chapter-02modified-130311122813-phpapp02/85/Chapter-02-modified-53-320.jpg)










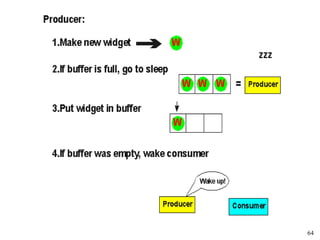
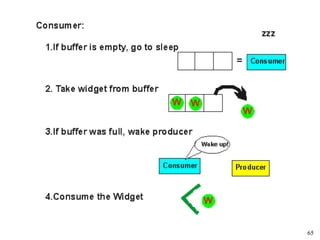























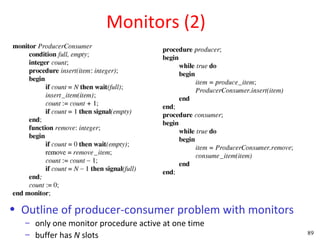









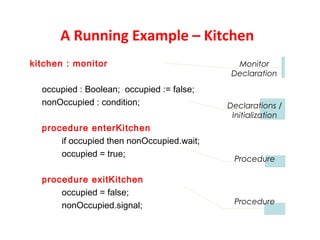










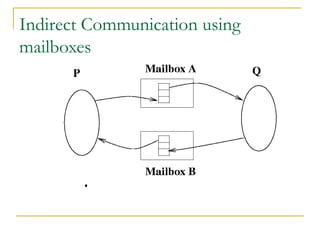

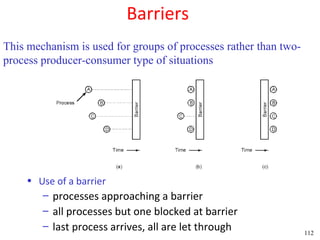






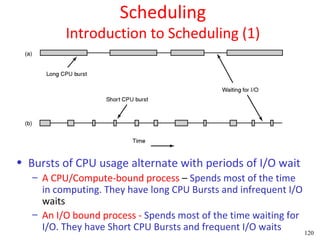









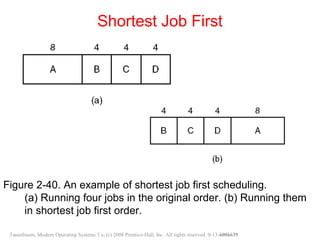


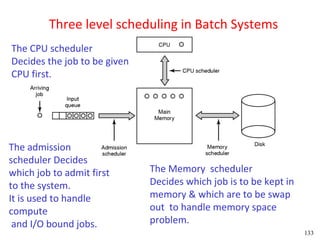
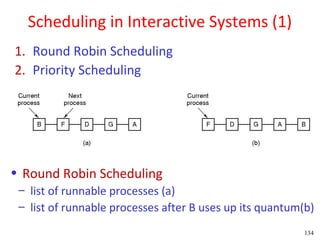





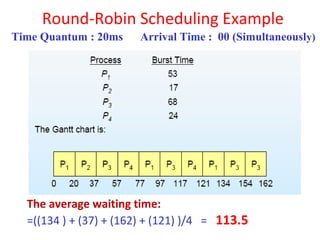





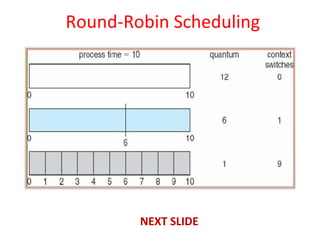

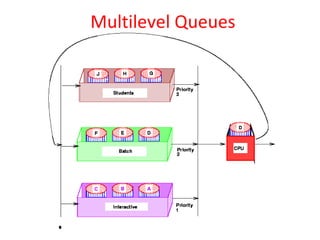
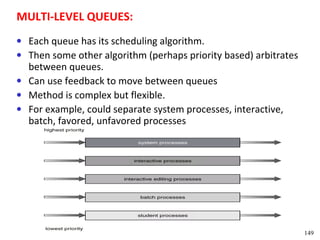
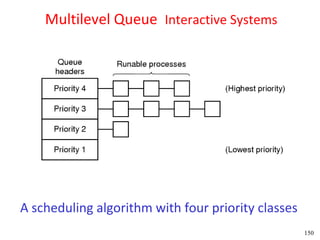




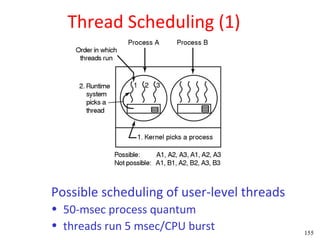
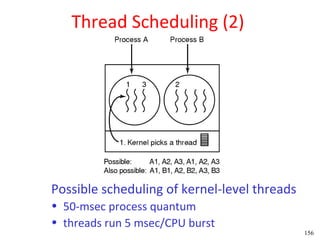





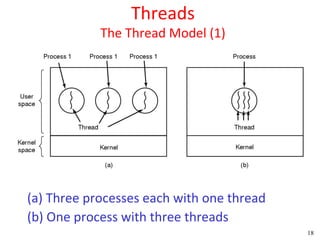
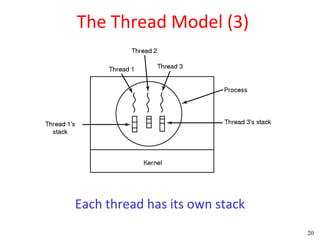
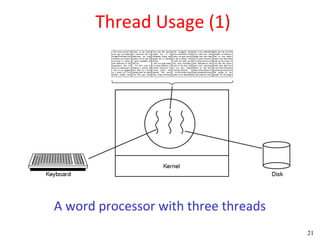
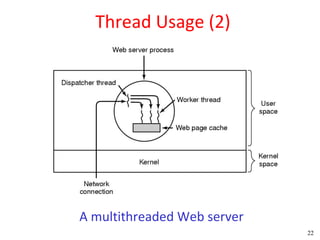
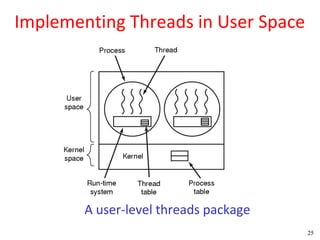
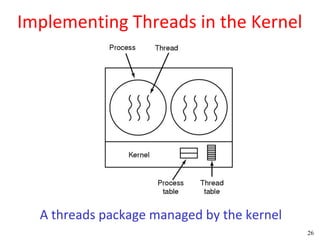
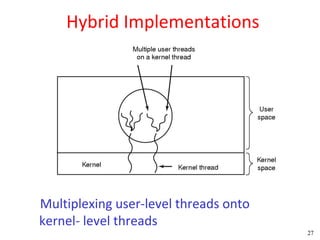
This document discusses processes and threads. It covers topics such as process models with multiprocessing, process creation and termination, process hierarchies and states. It also discusses threads models, usage and implementations. Additionally, it covers interprocess communication including classical IPC problems, race conditions, mutual exclusion and solutions like Peterson's algorithm. It discusses the priority inversion problem and provides an example.













































































