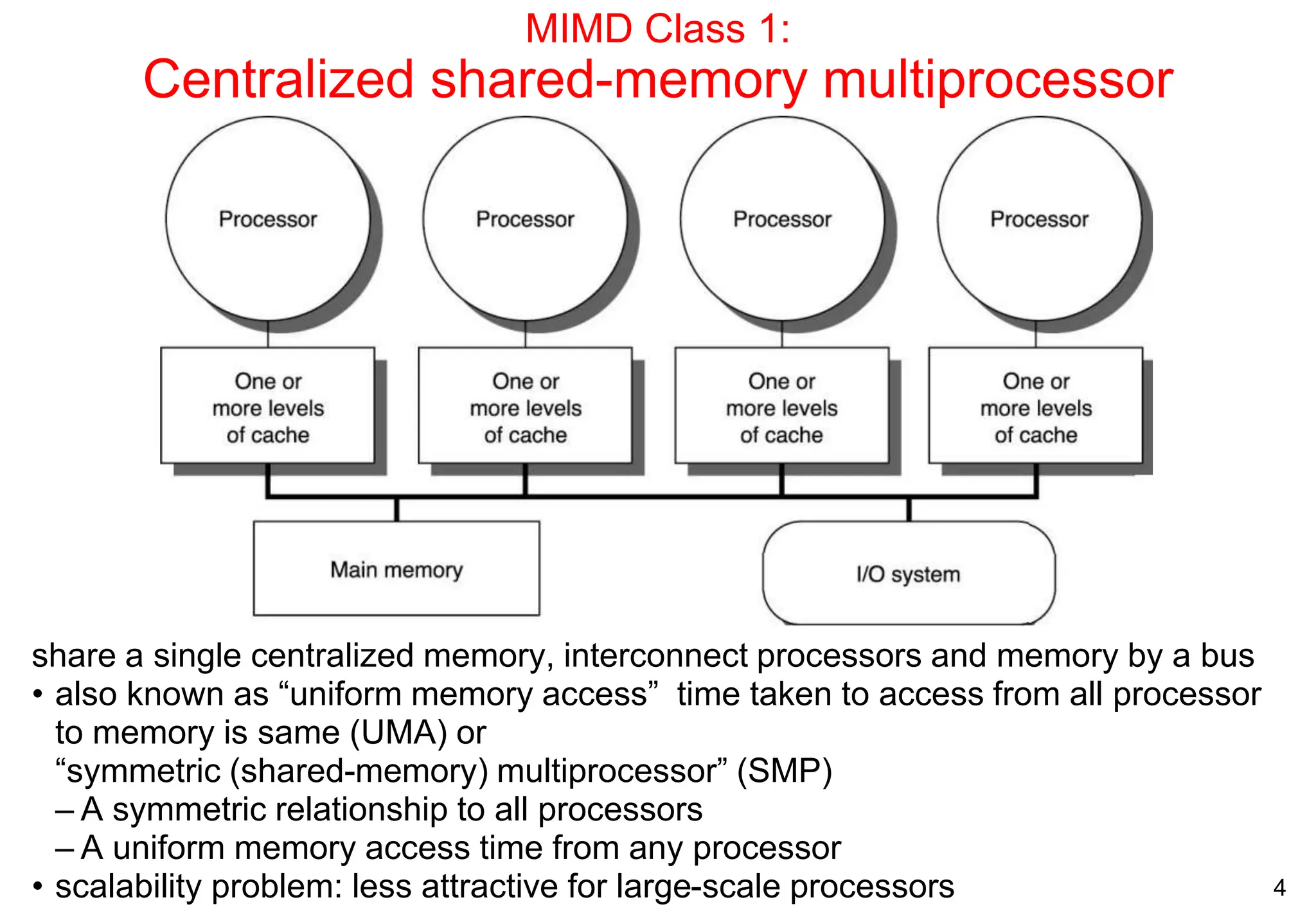
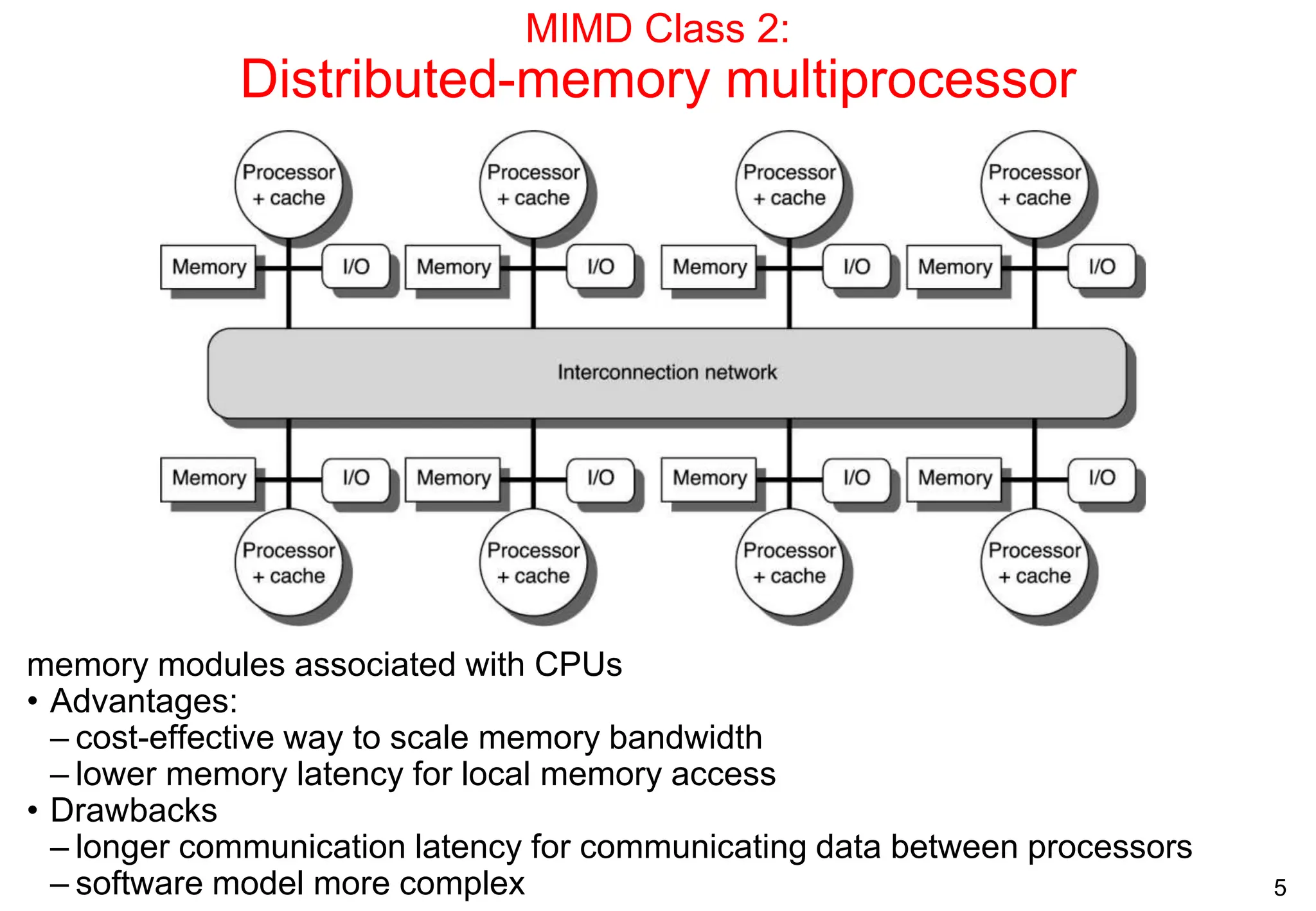
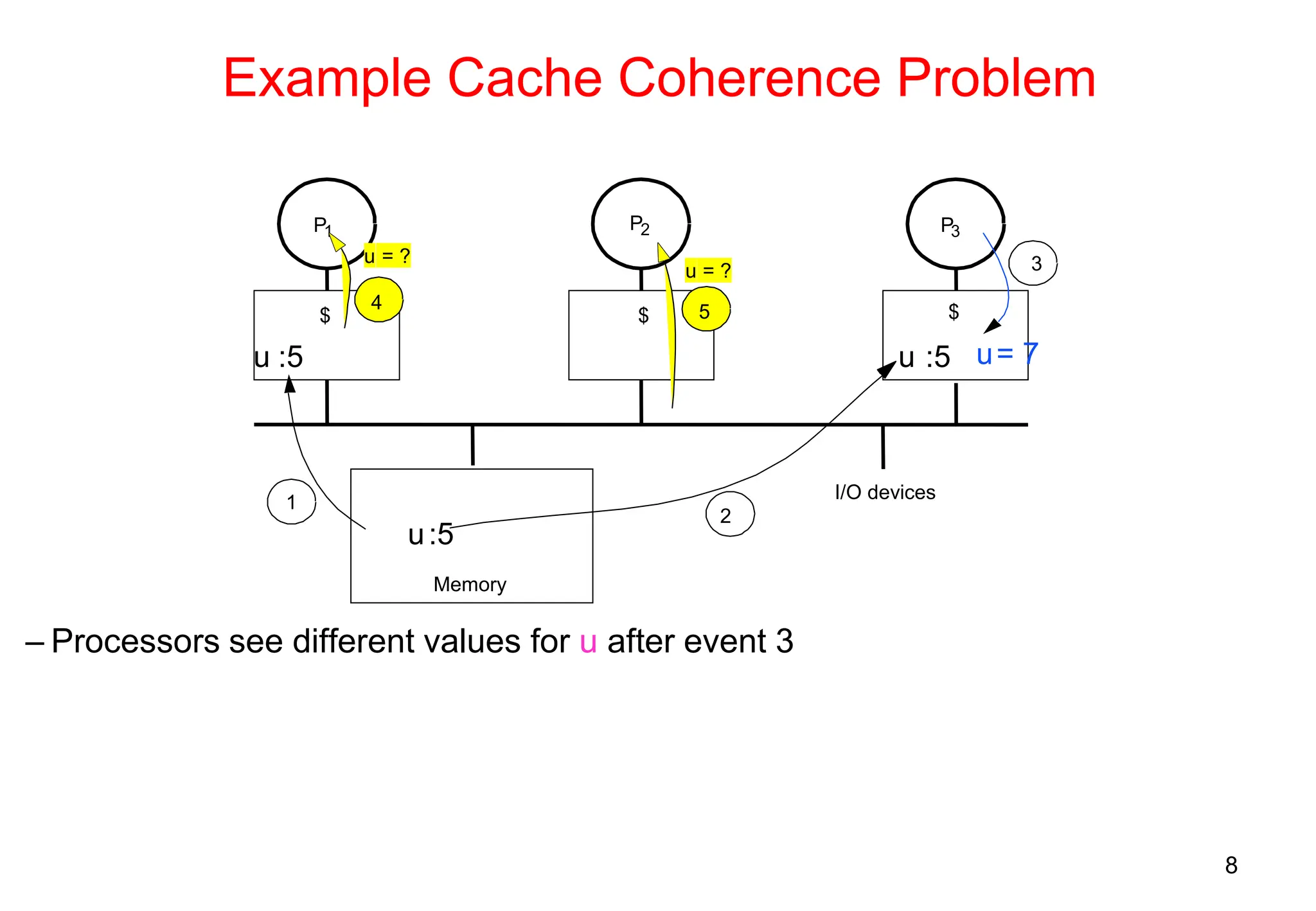
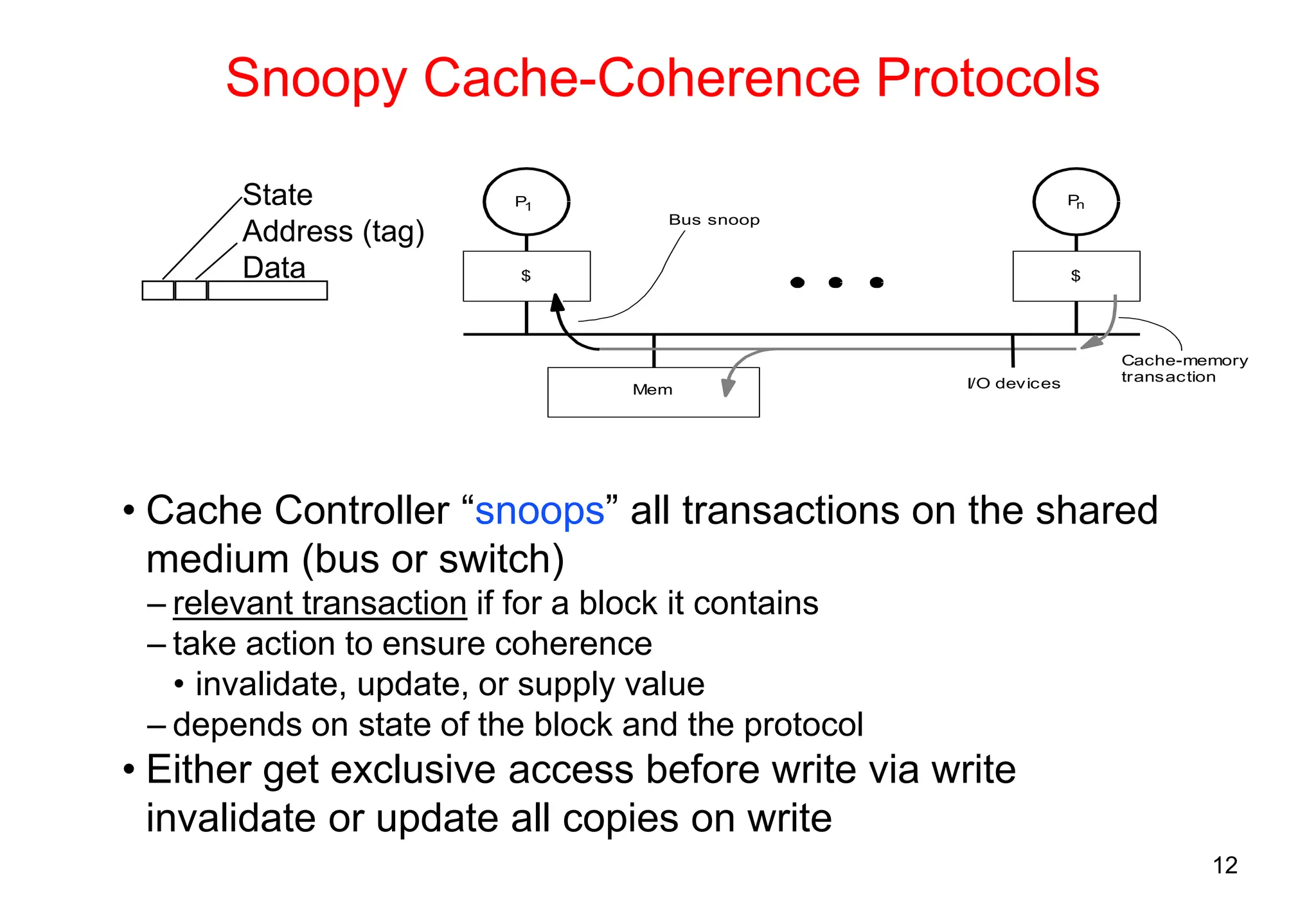
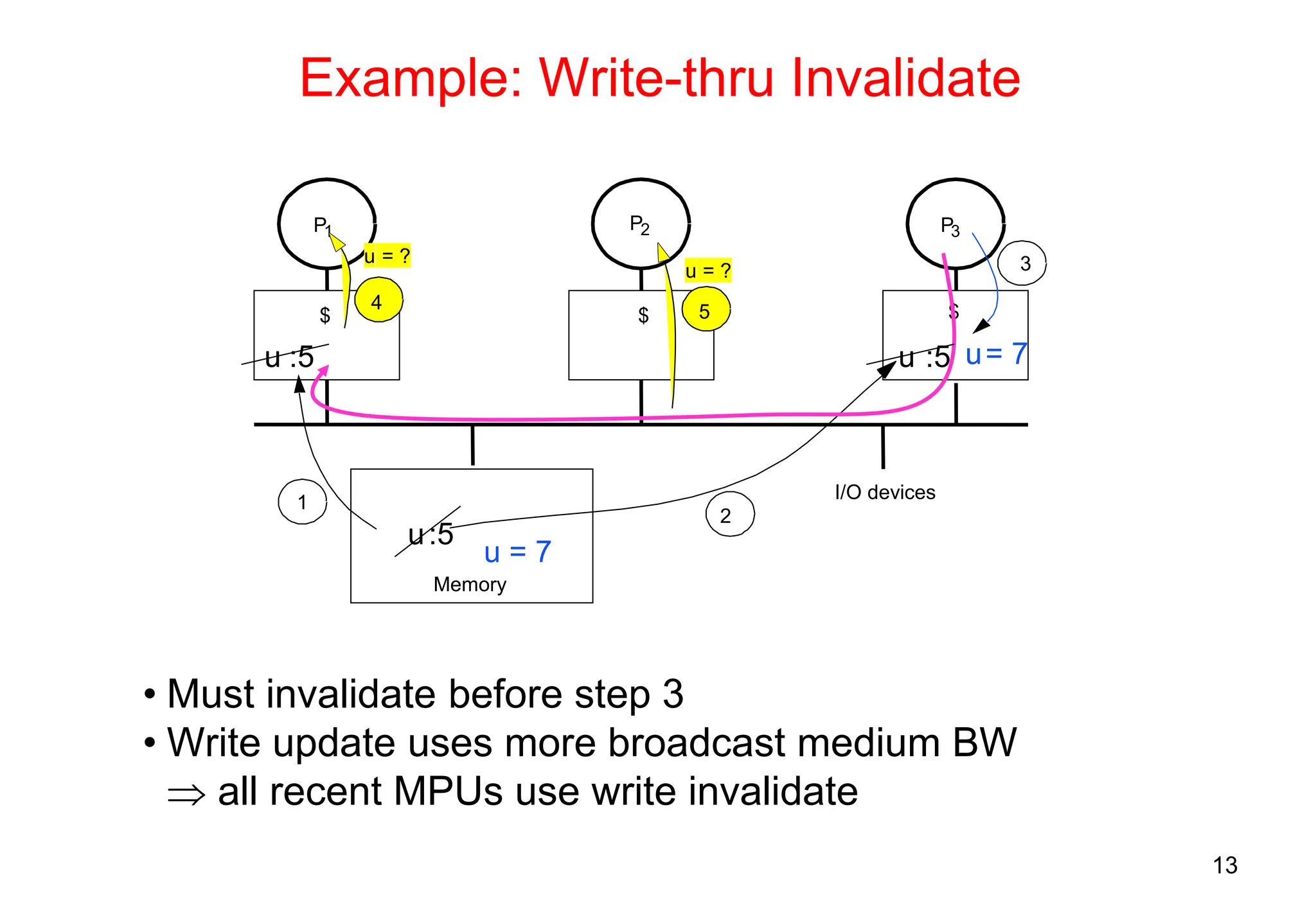
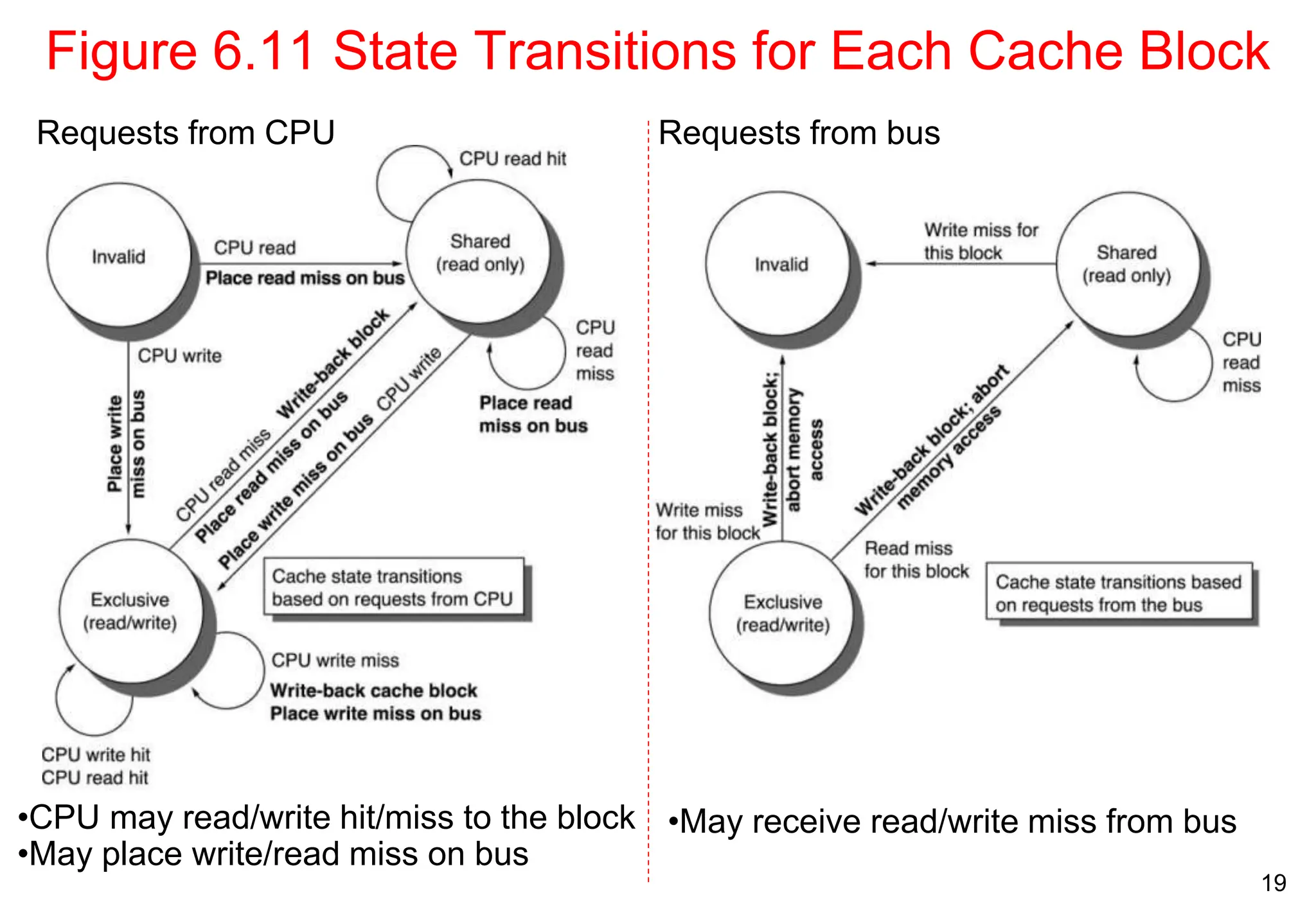
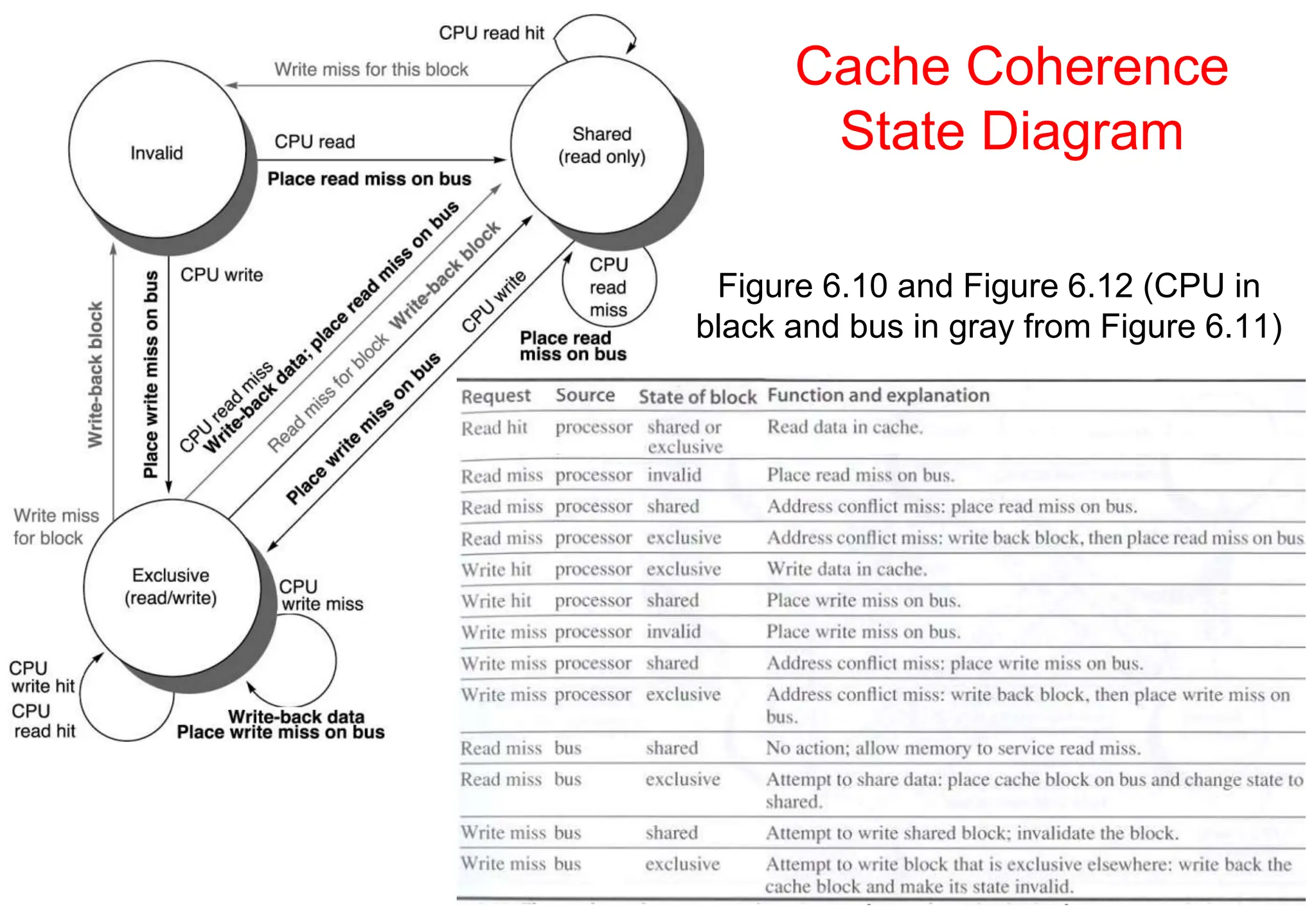
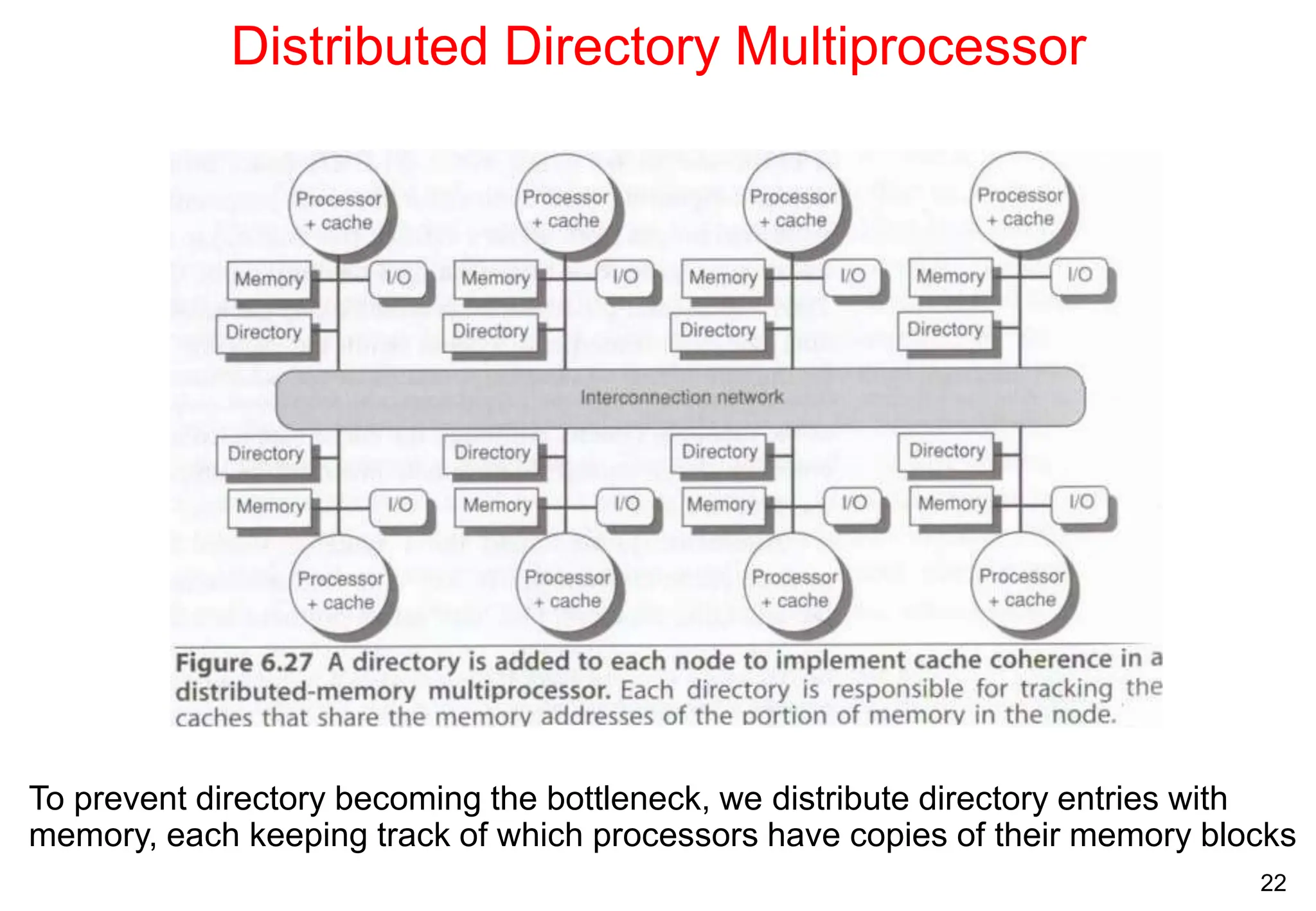
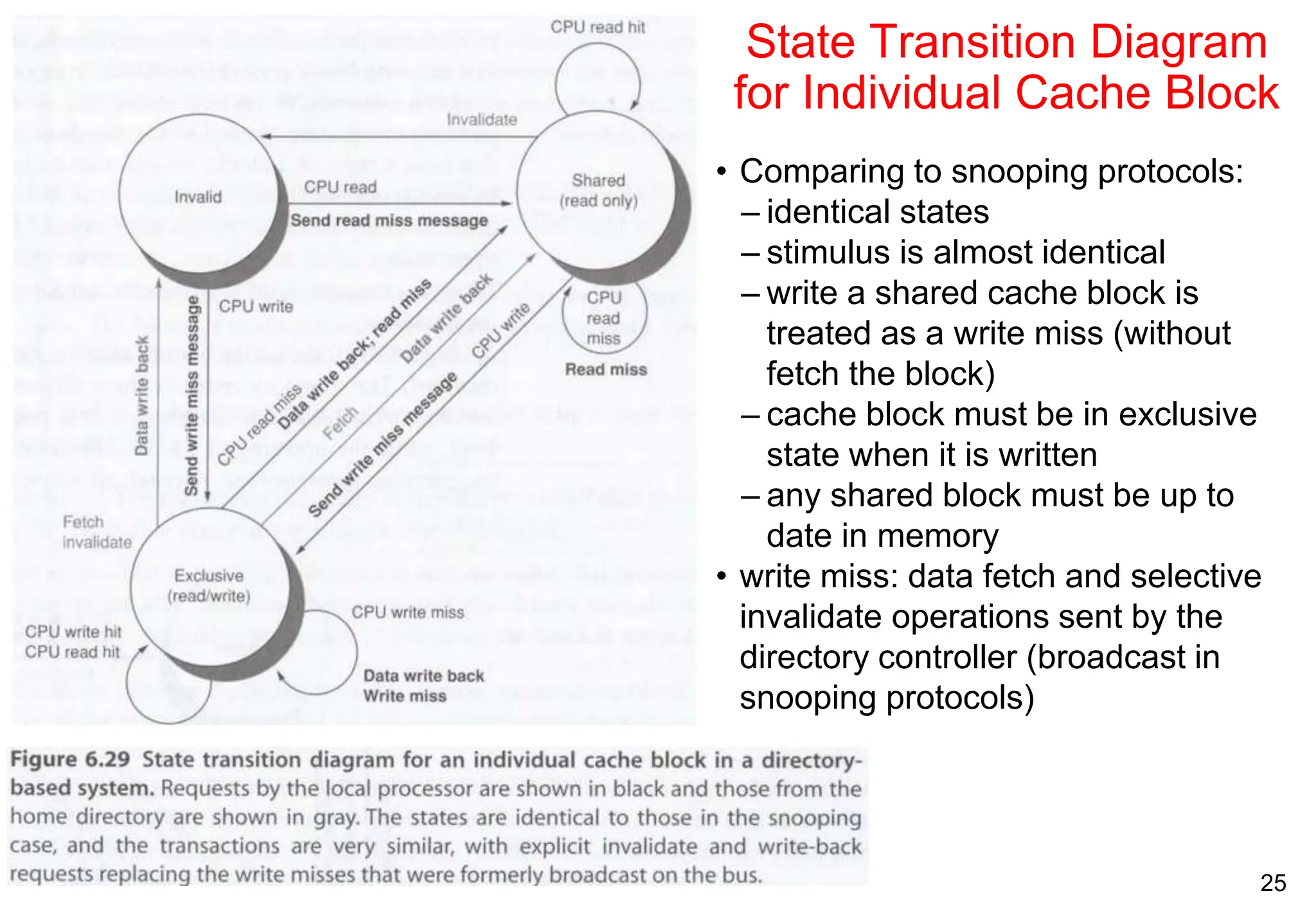
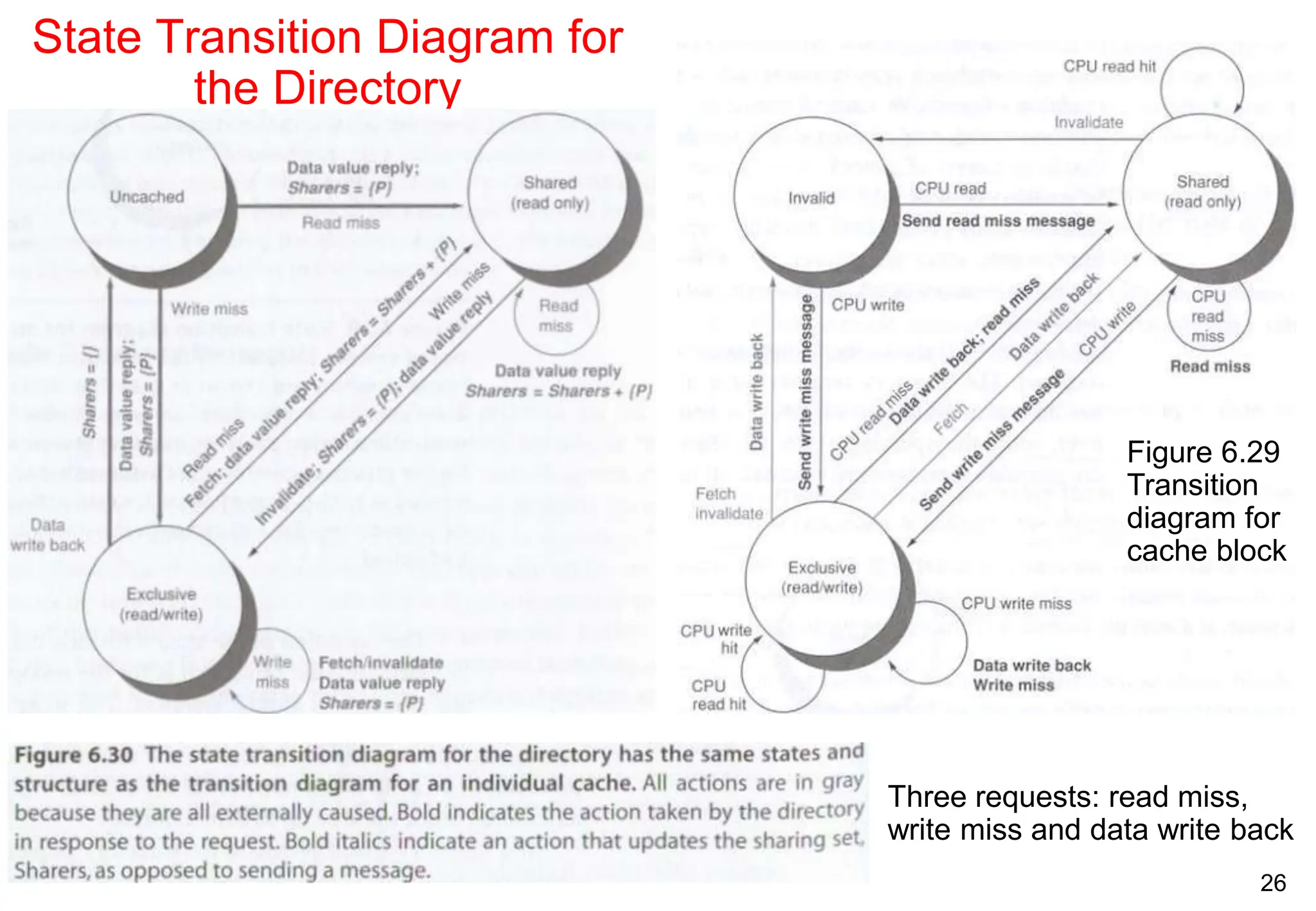
The document covers multiprocessors and thread-level parallelism, discussing various architectures such as symmetric shared-memory and distributed shared-memory systems. It highlights performance aspects, synchronization issues, cache coherence protocols, and models of memory consistency. Additionally, it defines several taxonomies of parallel architectures, including the categories of Flynn's taxonomy.