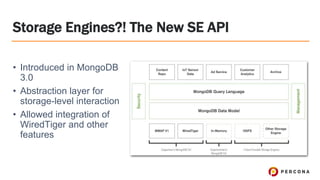
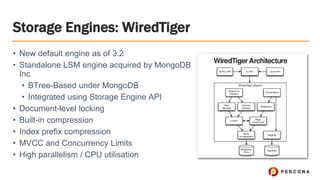
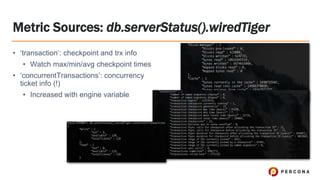
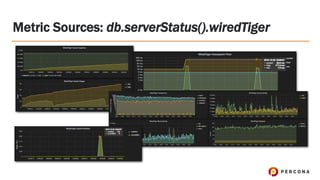
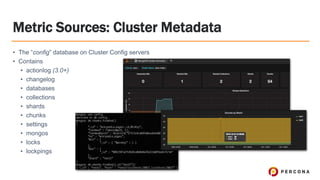
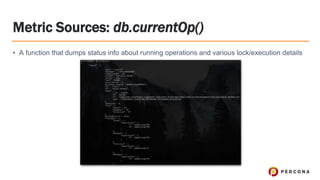
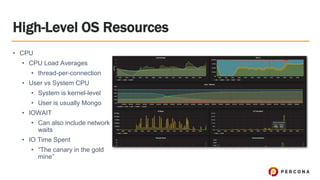
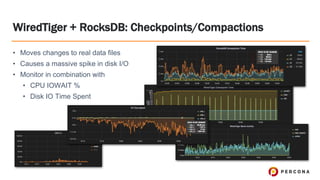
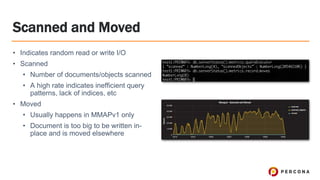
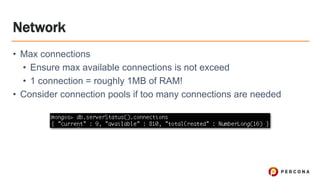
Tim Vaillancourt is a senior technical operations architect specializing in MongoDB. He has over 10 years of experience tuning Linux for database workloads and monitoring technologies like Nagios, MRTG, Munin, Zabbix, Cacti, and Graphite. He discussed the various MongoDB storage engines including MMAPv1, WiredTiger, RocksDB, and TokuMX. Key metrics for monitoring the different engines include lock ratio, page faults, background flushing times, checkpoints/compactions, replication lag, and scanned/moved documents. High-level operating system metrics like CPU, memory, disk, and network utilization are also important for ensuring MongoDB has sufficient resources.