Download to read offline



















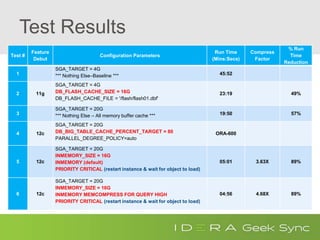


















The document provides a comprehensive overview of in-memory databases in Oracle and SQL Server, highlighting key features, benefits, and limitations. It discusses Oracle's In-Memory Column Store (IMCS) and SQL Server's In-Memory OLTP, detailing their structures, performance advantages, and settings required for implementation. The document also includes benchmarking results and considerations for using these technologies effectively in enterprise environments.





















































































