The document discusses SQL Server 2014's memory-optimized tables and in-memory processing, emphasizing the benefits for transaction processing with techniques like row/store and column/store indexing. It covers concepts such as hash indexing, multi-version concurrency control, and the handling of data in memory versus traditional on-disk storage. Key features include improved performance through optimized transactions and the importance of monitoring memory usage to avoid issues with memory constraints.
























![Garbage Collection
• Before GC can be performed:
– Rows get Durabilised to storage on COMMIT
– Checkpoint File Pairs grow, new ones created
– Various CFP will contain the “current” rows we want in case of a
failure [remember – log gets backed up and truncated]
– Merge CFP into a new one – pull out current rows into a new CFP
• CFP end up containing just old row versions no longer
required
• GC removes old CFP’s (FILESTREAM GC)](https://image.slidesharecdn.com/hekaton-zagreb-advanced-140609074847-phpapp01/85/SQL-Server-2014-Memory-Optimised-Tables-Advanced-26-320.jpg)
















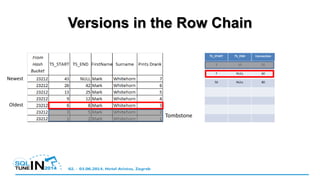
![Multi-Version Concurrency Control (MVCC)
• Compare And Swap replaces Latching
• Update is actually INSERT and Tombstone
• Row Versions [kept in memory]
• Garbage collection task cleans up versions no longer required
(stale data rows)
• Version not required determined by active transactions and
snapshot the connection has of the data
• Your in-memory table can double, triple, x 100 etc. in size
depending on access patterns (data mods + query durations)](https://image.slidesharecdn.com/hekaton-zagreb-advanced-140609074847-phpapp01/85/SQL-Server-2014-Memory-Optimised-Tables-Advanced-43-320.jpg)






















































![Ensuring compliance of patient data with big data and bi [bdii 301-m] - (4078)](https://cdn.slidesharecdn.com/ss_thumbnails/ensuringcomplianceofpatientdatawithbigdataandbibdii-301-m-4078-130430231240-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)







































