Downloaded 119 times






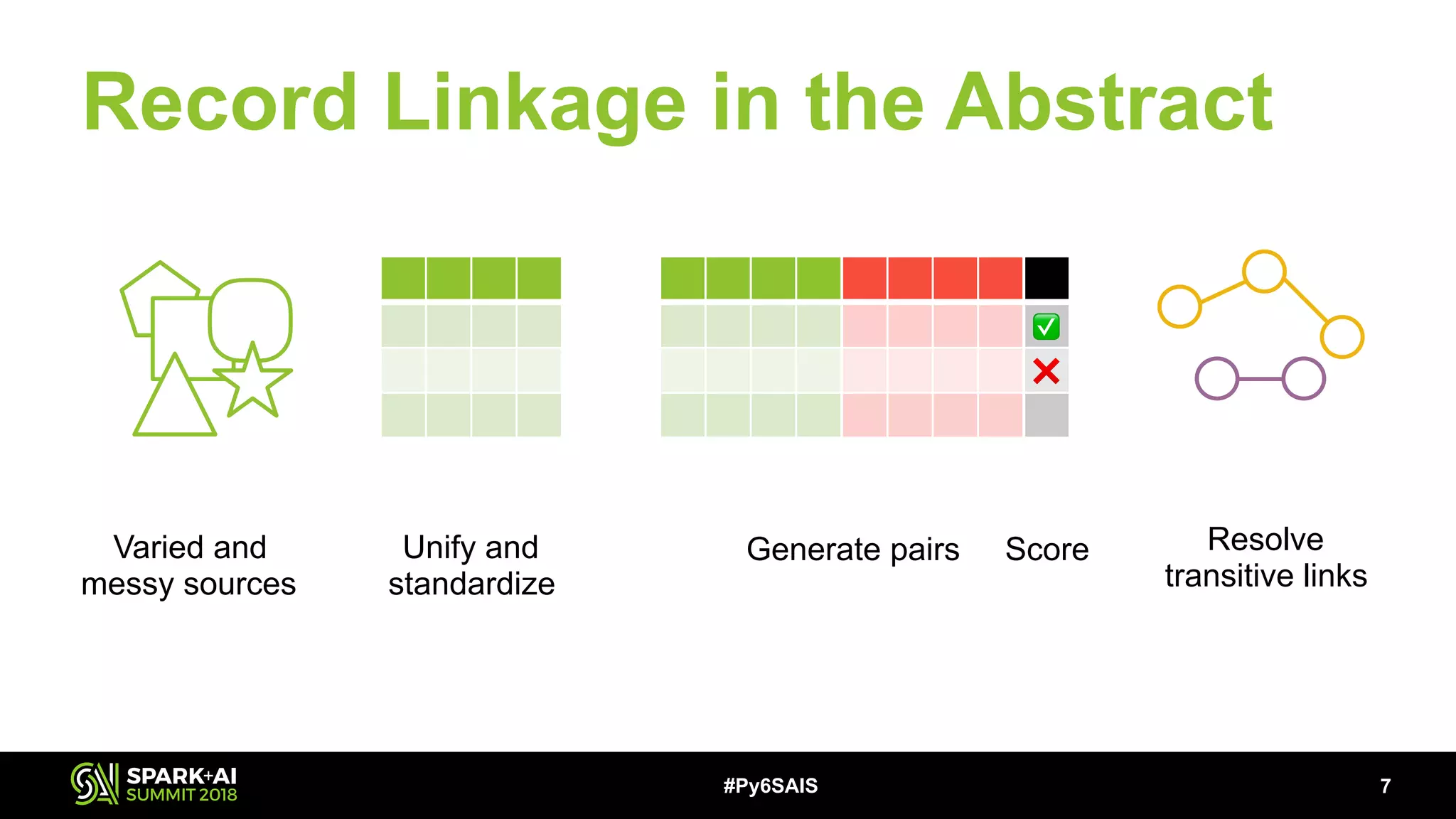







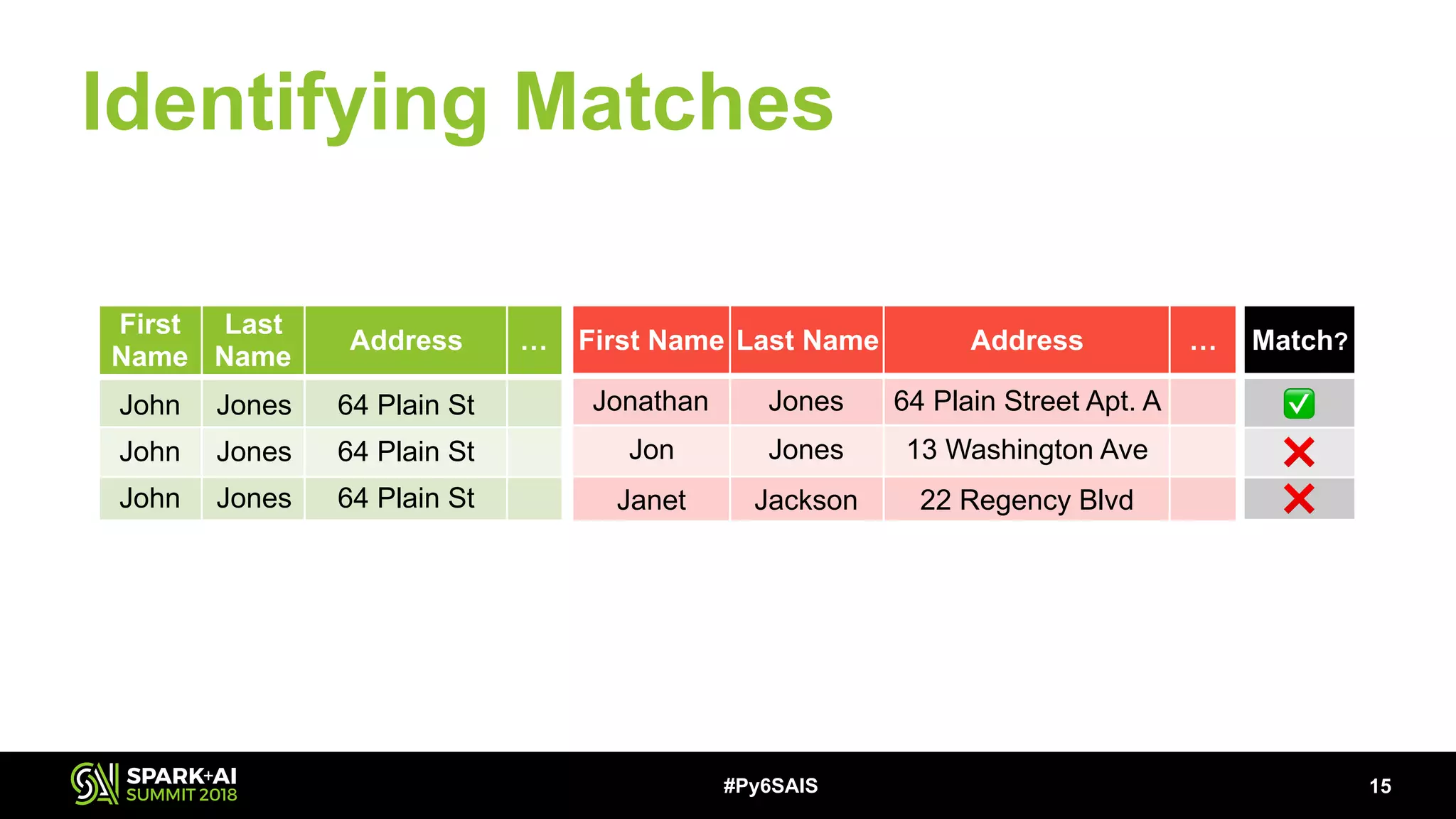
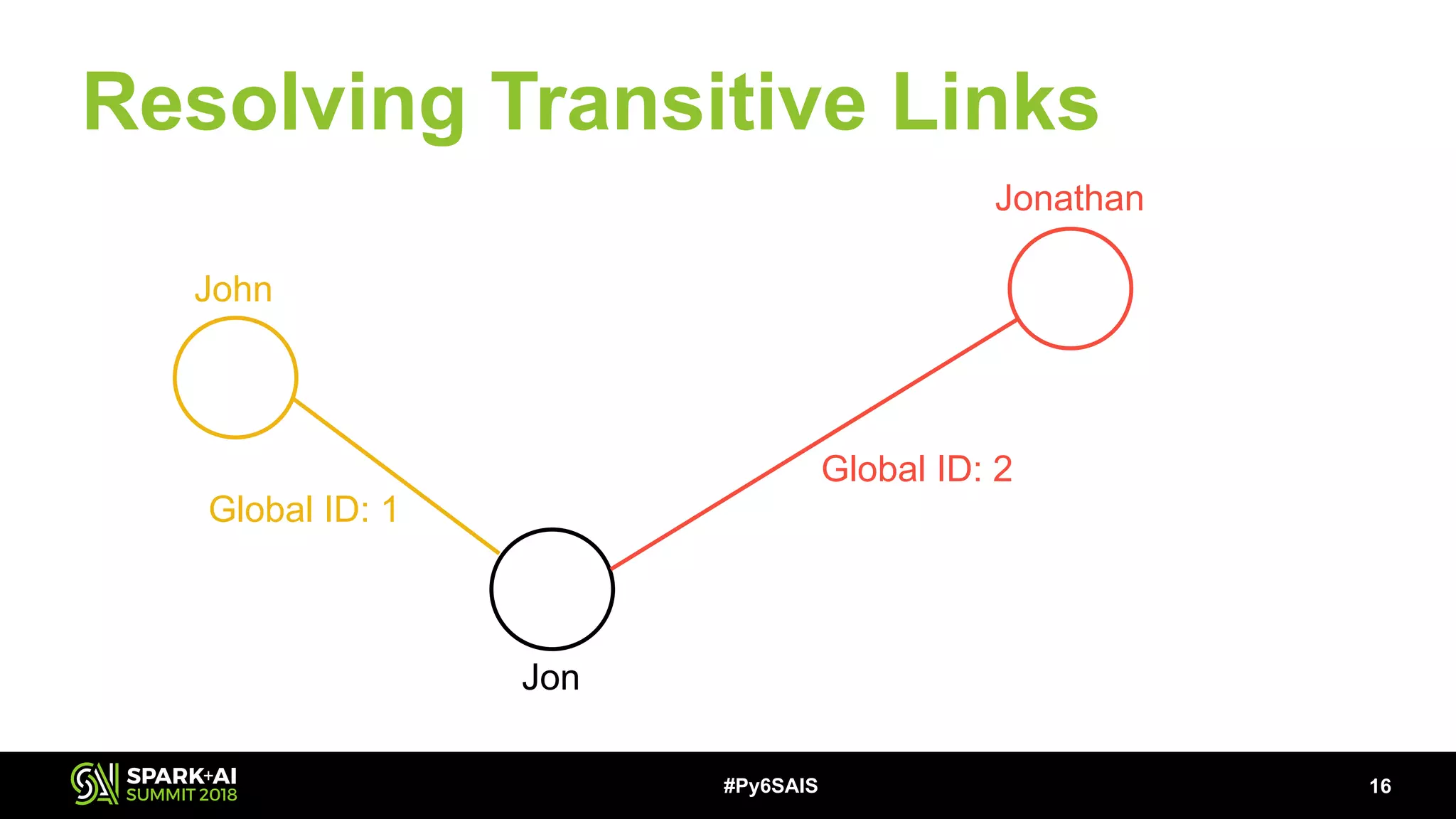
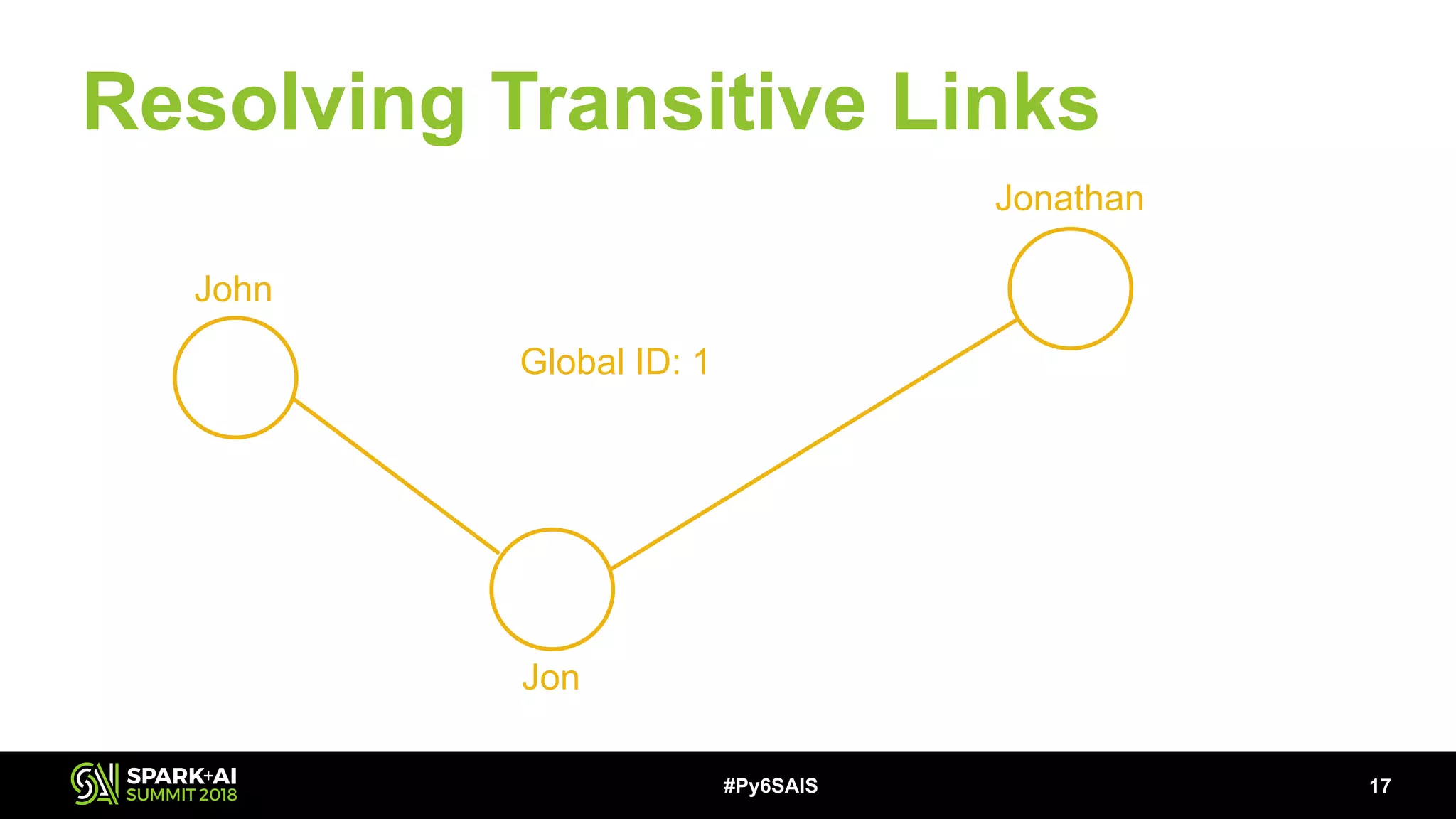











This document describes building a scalable record linkage system called Splinkr 3 using Apache Spark, Python 3, and machine learning. Splinkr 3 links over 330 million records across multiple systems to provide a comprehensive customer view. It standardizes data, generates record pairs efficiently using blocking keys, identifies matches using a logistic regression model, and resolves transitive links using GraphFrames. While experiments with neural networks showed marginal gains, logistic regression proved effective. Key challenges included training data quality and bugs in new Spark APIs.























































































