

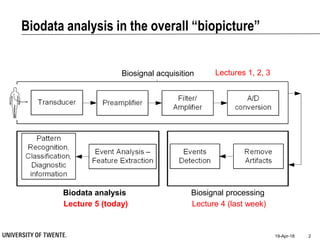





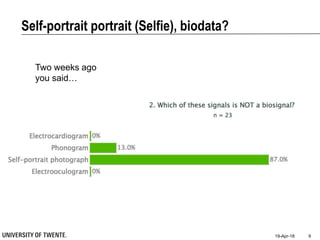

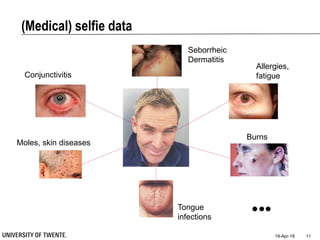
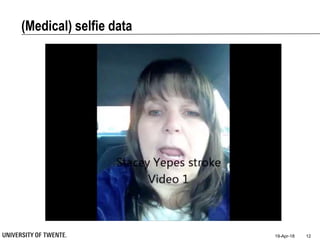
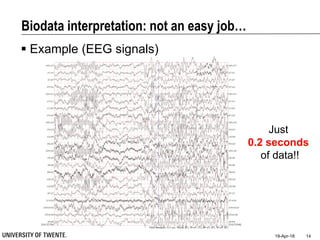

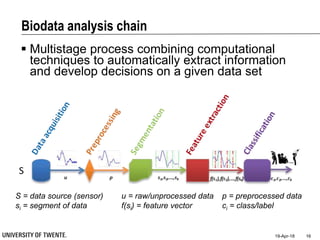


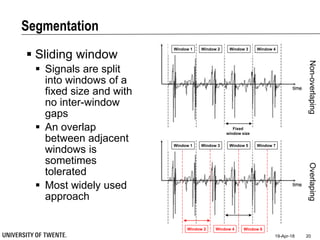
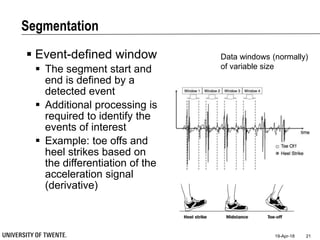
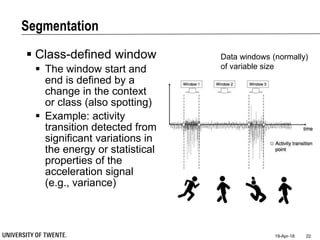


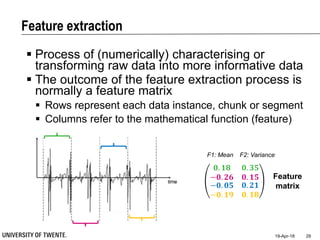
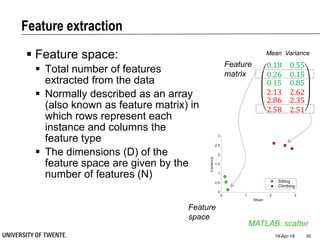




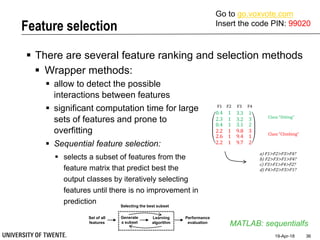
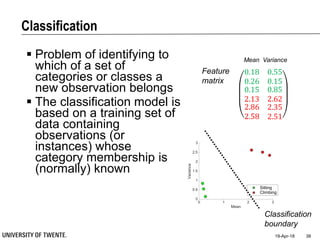
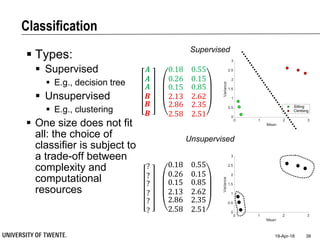
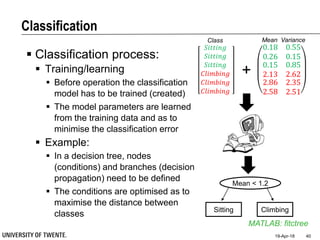
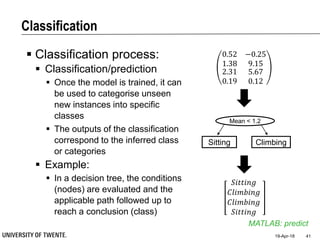

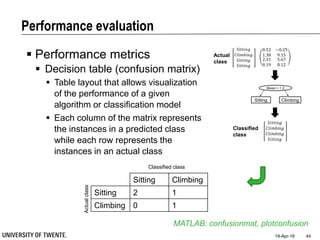
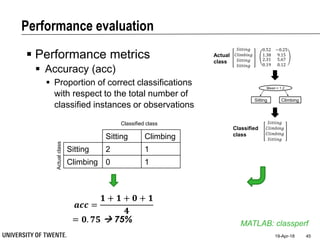




This document provides an overview of biodata analysis techniques for medical applications. It defines biodata as biological data collected from living systems. The biodata analysis chain involves several key steps: segmentation to divide data into windows, feature extraction to characterize the data numerically, feature selection to identify the most relevant features, and classification to assign categories or labels to new data based on a trained model. The document reviews techniques for each step of the analysis chain and provides examples of applying these techniques to motion and other types of medical biodata. The overall aim is to automatically extract useful information from large amounts of biodata to help medical experts with interpretation and decision making.




![Digital Signal Processing[ECEG-3171]-Ch1_L06](https://cdn.slidesharecdn.com/ss_thumbnails/dspl6ch2-180427094424-thumbnail.jpg?width=640&height=640&fit=bounds)


















































































