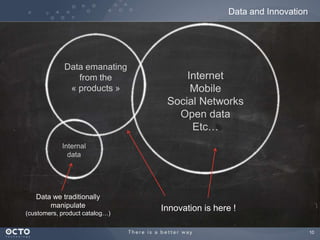
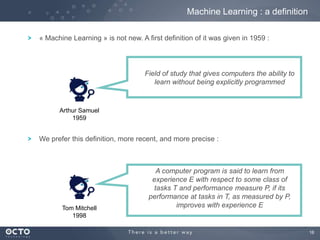
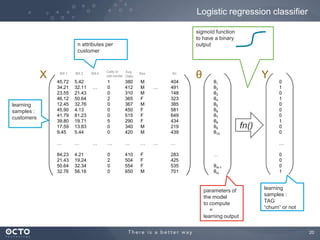
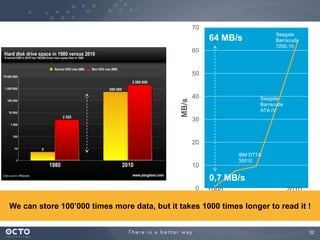
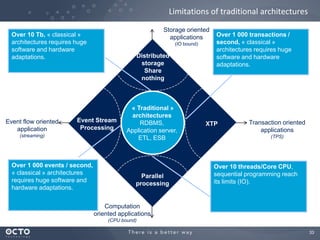
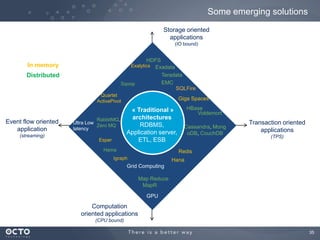
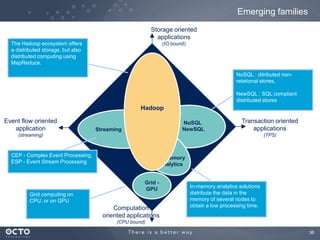
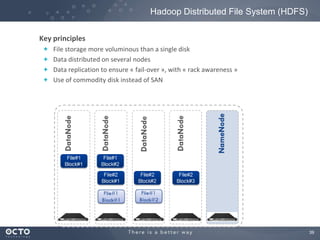
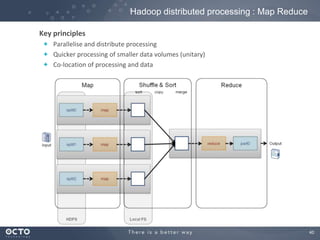
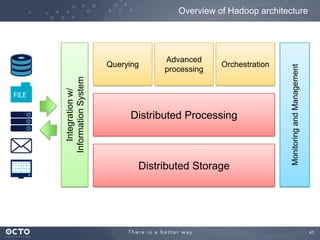
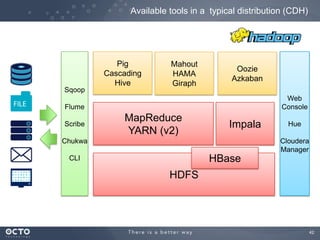
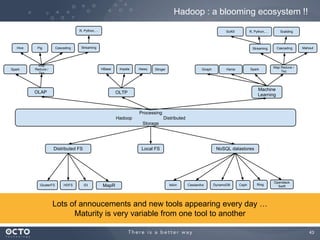
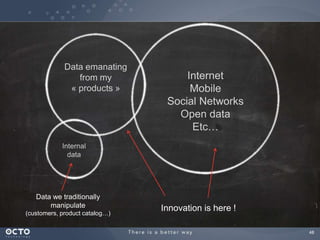
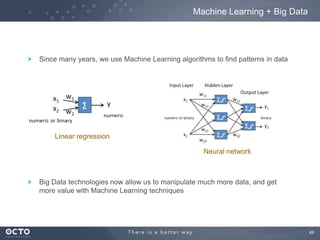
The document discusses the concept of big data, its origins, and its integration with machine learning to enhance data analysis and decision-making. It highlights the economic advantages of using big data and outlines various use cases where machine learning can improve processes like customer behavior analysis and risk modeling. Additionally, the document emphasizes the evolving technologies and architectures, particularly with Hadoop, that support the storage and processing of large data volumes.




























![[Webinar] How Big Data and Machine Learning Are Transforming ITSM](https://cdn.slidesharecdn.com/ss_thumbnails/webinarhowbigdataandmachinelearningaretransformingitsm-160602174503-thumbnail.jpg?width=640&height=640&fit=bounds)









































































































