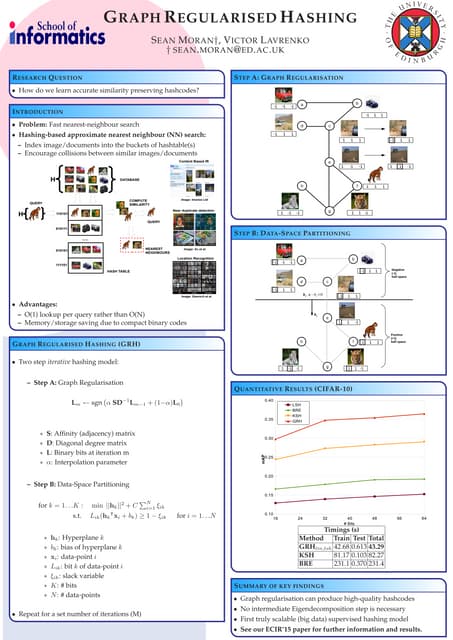
Downloaded 13 times



![Counting Algorithm for Contiguity Weights Creation
7
Counting Algorithms:
• Inspired by TopoJson:
• Same vertices only stored once.
• Counting how many polygons share a point (Queen Weights): O(n)
1
2
3 4
6
5
7
8
9
10
11
12
13
14
16
15
17
18
20
19
Count A:
{1:[A],
2:[A],
3:[A],
4:[A],
5:[A],
6:[A]}
Count B:
{1:[A]
,2:[A]
,3:[A]
,4:[A]
,5:[A,B]
,6:[A,B]
,7:[B]
,8:[B]
,9:[B]
,10:[B]}
Count C:
{1:[A]
,2:[A],
,3:[A,C]
,4:[A,C]
,5:[A,B]
,6:[A,B]
,7:[B]
,8:[B]
,9:[B]
,10:[B]
,13:[C]
,14:[C]
,15:[C]
,16:[C]}
Neighbors:
[A,C]
[A,B]](https://image.slidesharecdn.com/bigspatial2014mapreduceweights-141107134314-conversion-gate02/85/Big-spatial2014-mapreduceweights-7-320.jpg)
![Counting Algorithm for Contiguity Weights Creation
8
Counting Algorithms:
• Counting how many polygons share an edge (Rook Weights): O(n)
1
2
3 4
6
5
7
8
9
10
11
12
13
14
16
15
17
18
20
19
Count A:
{(1,2):[A]
,(2,3):[A]
,(3,4):[A]
,(4,5):[A]
,(5,6):[A]
,(6,1):[A]}
Count B:
{(1,2):[A]
,(2,3):[A]
,(3,4):[A]
,(4,5):[A]
,(5,6):[A,B]
,(6,1):[A]
,(6,7):[B]
,(7,8):[B]
,(8,9):[B]
,(9,10):[B]}
Neighbors:
[A,B]](https://image.slidesharecdn.com/bigspatial2014mapreduceweights-141107134314-conversion-gate02/85/Big-spatial2014-mapreduceweights-8-320.jpg)
![Parallel Counting Algorithm?
9
1
2
3 4
6
5
7
8
9
10
11
12
13
14
16
15
17
18
20
19
7
Count Results:
{1:[A]
,2:[A]
,3:[A,C]
,4:[A,C]
,5:[A]
,6:[A]
,13:[C]
,14:[C]
…}
Count Results:
{5:[B,D]
,6:[B]
…,9:[B]
,10:[B,D]
,11:[D,E]
,12:[D,E]
,13:[D]
…}
1
2
3 4
6
5
13
14
16
15
4
6
5
7
8
9
10
11
12
13
17
20
19
7](https://image.slidesharecdn.com/bigspatial2014mapreduceweights-141107134314-conversion-gate02/85/Big-spatial2014-mapreduceweights-9-320.jpg)
![Parallel Counting Algorithm? –Conti.
10
Print line by line
1:[A]
2:[A]
3:[A,C]
4:[A,C]
5:[A]
6:[A]
13:[C]
14:[C]
…
Print line by line
5:[B,D]
6:[B]
…
9:[B]
10:[B,D]
11:[D,E]
12:[D,E]
13:[D]
…
1
2
3 4
6
5
13
14
16
15
4
6
5
7
8
9
10
11
12
13
17
20
19
7
Merge & Sort
Two Results:
1:[A]
2:[A]
3:[A,C]
4:[A,C]
4:[A]
4:[D]
5:[A]
5:[B,D]
6:[A]
6:[B]
7:[B]
11:[D,E]
12:[D,E]
13:[C]
13:[D]
14:[C]
…
{3:[A,C]}
{4:[A,C,D]}
{5:[A,B,D]}
{6:[A,B]}
{11:[D,E]}
{12:[D,E]}
{13:[C,D]}
A B C D E
A 0 1 1 1 0
B 1 0 0 1 0
C 1 0 0 1 0
D 1 1 1 0 1
E 0 0 0 1 0](https://image.slidesharecdn.com/bigspatial2014mapreduceweights-141107134314-conversion-gate02/85/Big-spatial2014-mapreduceweights-10-320.jpg)


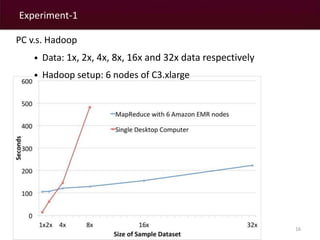
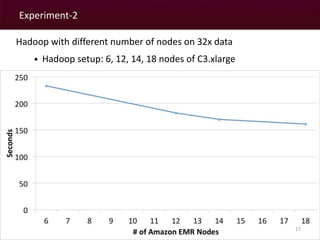
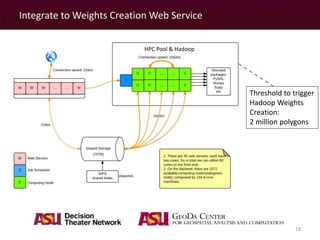




The document discusses a MapReduce algorithm developed to create contiguity weights for spatial analysis of large datasets. It outlines various methods for generating spatial weights, including counting algorithms for both rook and queen contiguity, and compares performances on different computing systems. The findings highlight potential issues of the algorithm, particularly concerning spatial neighbors without shared points or edges, and propose ongoing work to incorporate an r-tree structure to address these challenges.