Downloaded 33 times
















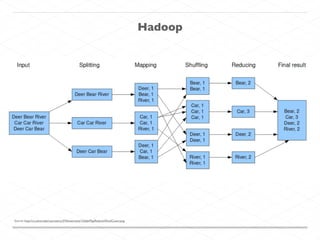


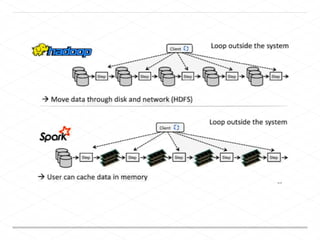






















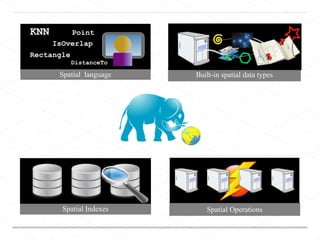
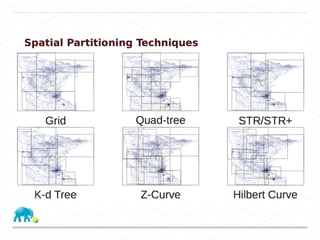
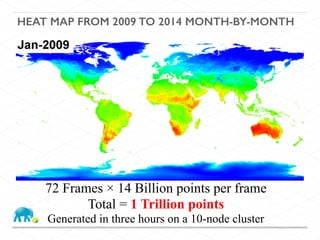
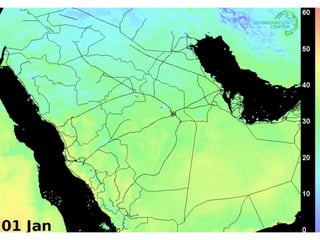



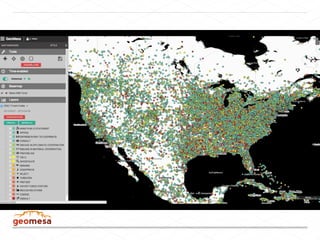
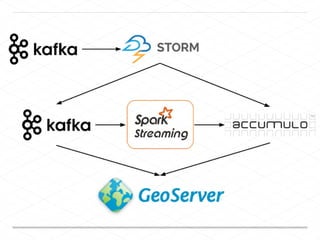
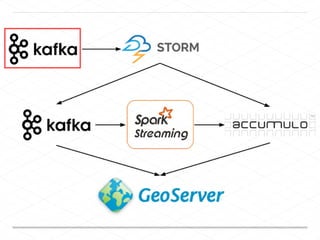
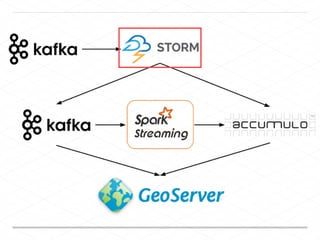
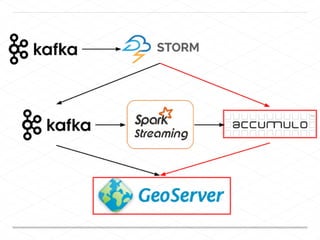
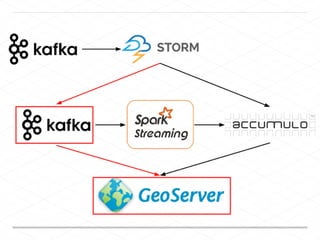
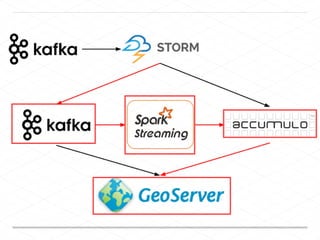



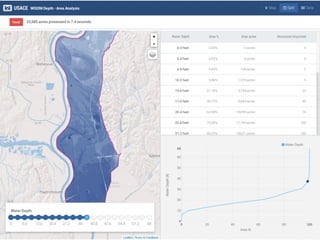
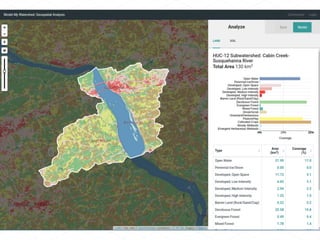
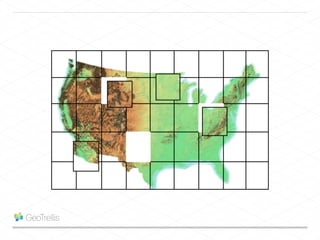
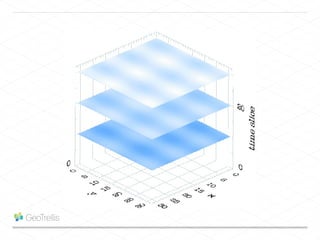
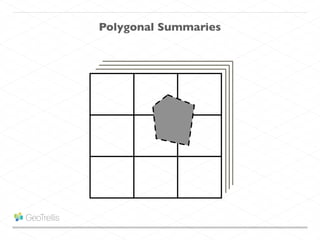
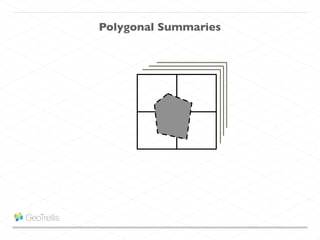


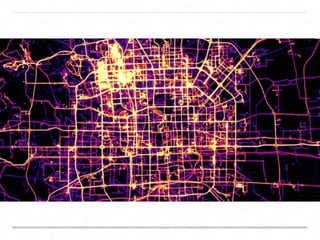



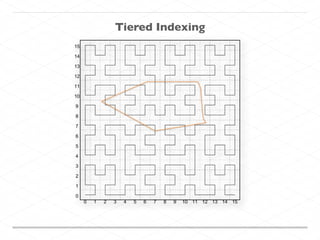
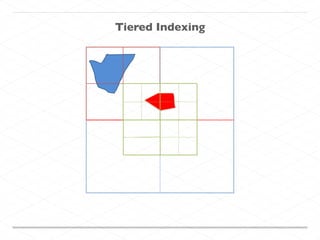
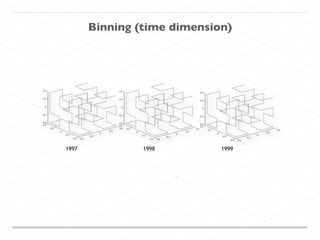
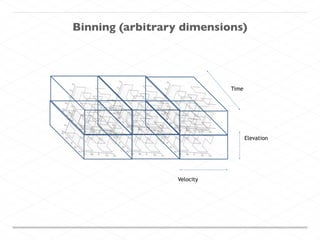



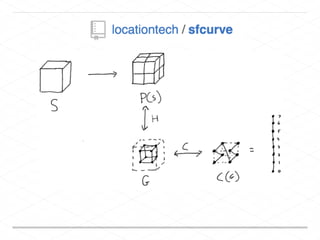



This document discusses processing large geospatial data at scale. It provides background on big data frameworks like Apache Hadoop, Apache Spark, and geospatial projects like GeoTrellis, GeoWave, and SpatialHadoop that enable processing geospatial data using these frameworks. The document outlines how these tools allow geospatial data from sources like satellite imagery, OpenStreetMap, and geotagged social media to be analyzed using distributed computing platforms and algorithms.










































































