










![Bayesian Counters
• [A=a1;B=b1] -> 5
• [A=a1;B=b2] -> 15
Pr(A|B) = Pr(AB)/Pr(B) • …
= Count(AB)/Count(B) • [A=a2;B=b1] -> 3
• …](https://image.slidesharecdn.com/bayesiancounters-20120613-120618124928-phpapp01/85/Hadoop-Summit-2012-Bayesian-Counters-AKA-In-Memory-Data-Mining-for-Large-Data-Sets-13-320.jpg)

![Anatomy of a counter
Region (divide between)
Counter/Table
File Column family
Iris
[sepal_width=2;class=0] Column qualifier
30 mins
1321038671 Version
1321038998
15
2 hours
Value (data)
Cars …](https://image.slidesharecdn.com/bayesiancounters-20120613-120618124928-phpapp01/85/Hadoop-Summit-2012-Bayesian-Counters-AKA-In-Memory-Data-Mining-for-Large-Data-Sets-15-320.jpg)
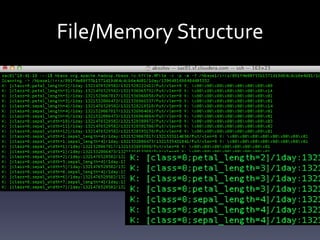




![Clique ranking
What is the best structure of a Bayesian Network
I(X;Y)=ΣΣp(x,y)log[p(x,y)/p(x)p(y)]
Where x in X and y in Y
Using random projection can generalize on
abstract subset Z](https://image.slidesharecdn.com/bayesiancounters-20120613-120618124928-phpapp01/85/Hadoop-Summit-2012-Bayesian-Counters-AKA-In-Memory-Data-Mining-for-Large-Data-Sets-21-320.jpg)
![Assoc
• Confidence (A -> B): count(A and B)/count(A)
• Lift (A -> B): count(A and B)/[count(A) x count(B)]
• Usually filtered on support: count(A and B)
• Frequent itemset search](https://image.slidesharecdn.com/bayesiancounters-20120613-120618124928-phpapp01/85/Hadoop-Summit-2012-Bayesian-Counters-AKA-In-Memory-Data-Mining-for-Large-Data-Sets-22-320.jpg)

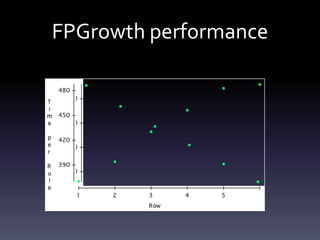
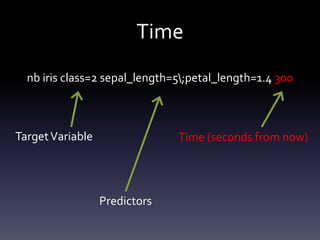




The document discusses Bayesian Counters as a method for in-memory data mining of large datasets. It covers trends in big data, performance results of various algorithms, and system designs for handling uncertainty and efficiency in data processing. Key implementations like Naïve Bayes and association rules are highlighted as ways to derive insights from complex data structures.





![[241]large scale search with polysemous codes](https://cdn.slidesharecdn.com/ss_thumbnails/241large-scalesearchwithpolysemouscodes-171017003327-thumbnail.jpg?width=640&height=640&fit=bounds)































































































