Download to read offline

![Agenda
[Big]Data Source: when it becomes Big?
What cluster is? Horizontal and vertical scaling
[Big]Data Storage challenges
Disadvantages
NoSQL = Not only SQL
Most popular and trendy](https://image.slidesharecdn.com/bigdatastorages-161115111410/85/Big-data-storages-2-320.jpg)






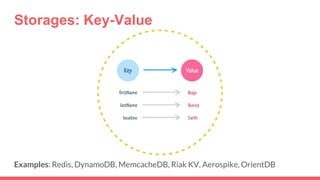
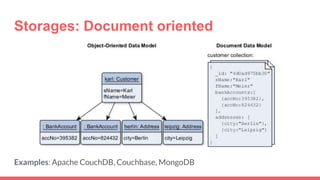
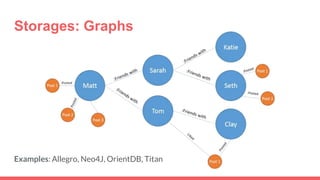




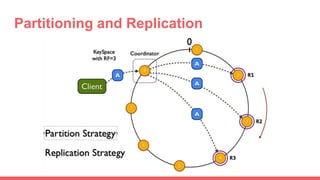




Big data storage systems are designed to store large volumes of immutable data from sources like sensors, social networks, and log files. They provide horizontal and vertical scaling through clustering to ensure size, speed, and availability. Common approaches include NoSQL key-value, document, and column-oriented databases like Redis, MongoDB, and Cassandra that sacrifice transactions for performance but lack standardization and analytics capabilities.







































































































