Download to read offline












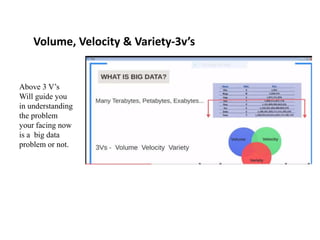















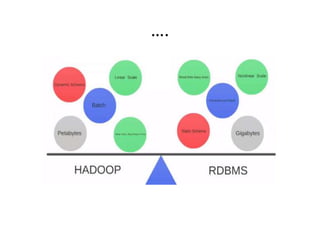

















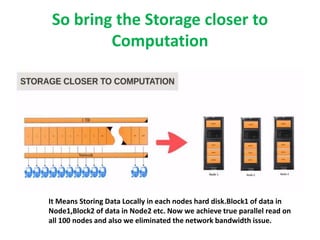


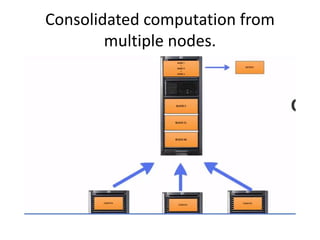








1. The document discusses big data problems faced by various domains like science, government, and private organizations. 2. It defines big data based on the 3Vs - volume, velocity, and variety. Volume alone is not sufficient, and these factors must be considered together. 3. Traditional databases are not suitable for big data problems due to issues with scalability, structure of data, and hardware limitations. Distributed file systems like Hadoop are better solutions as they can handle large and varied datasets across multiple nodes.


















































































