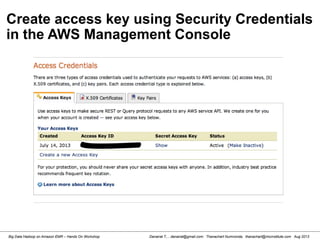
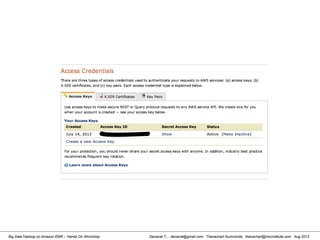
Downloaded 357 times





![Danairat T., , danairat@gmail.com: Thanachart Numnonda, thanachart@imcinstitute.com Aug 2013Big Data Hadoop on Amazon EMR – Hands On Workshop
Starting Hadoop
[hdadmin@localhost hadoop]$ /usr/local/hadoop/bin/start-all.sh
Starting up a Namenode, Datanode, Jobtracker and a Tasktracker on your machine.
[hdadmin@localhost hadoop]$ /usr/lib/jvm/jdk1.6.0_39/bin/jps
11567 Jps
10766 NameNode
11099 JobTracker
11221 TaskTracker
10899 DataNode
11018 SecondaryNameNode
[hdadmin@localhost hadoop]$
Checking Java Process and you are now running Hadoop as pseudo distributed mode](https://image.slidesharecdn.com/bigdatahadoopamazonv2-130803035124-phpapp02/85/Big-Data-Hadoop-using-Amazon-Elastic-MapReduce-Hands-On-Labs-8-320.jpg)
![Danairat T., , danairat@gmail.com: Thanachart Numnonda, thanachart@imcinstitute.com Aug 2013Big Data Hadoop on Amazon EMR – Hands On Workshop
Stopping Hadoop
[hdadmin@localhost hadoop]$ /usr/local/hadoop/bin/stop-all.sh
stopping jobtracker
localhost: stopping tasktracker
stopping namenode
localhost: stopping datanode
localhost: stopping secondarynamenode](https://image.slidesharecdn.com/bigdatahadoopamazonv2-130803035124-phpapp02/85/Big-Data-Hadoop-using-Amazon-Elastic-MapReduce-Hands-On-Labs-10-320.jpg)



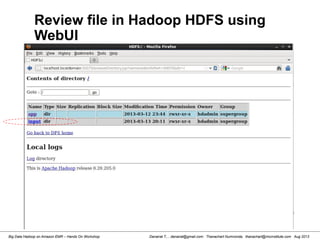
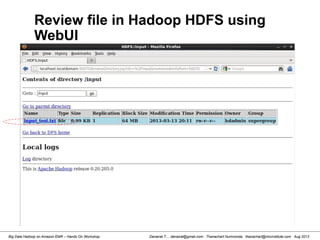
![Danairat T., , danairat@gmail.com: Thanachart Numnonda, thanachart@imcinstitute.com Aug 2013Big Data Hadoop on Amazon EMR – Hands On Workshop
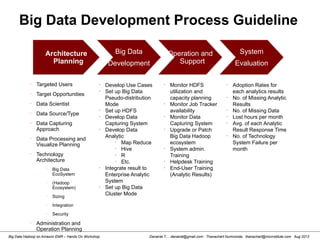
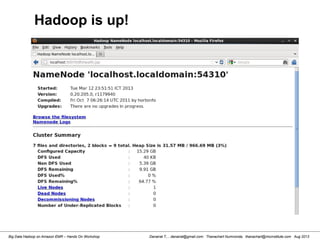
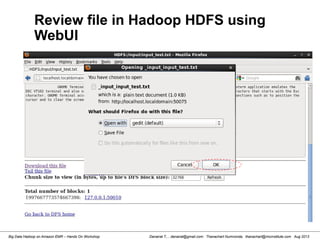
Review file in Hadoop HDFS
[hdadmin@localhost bin]$ hadoop dfs -ls /input
Found 1 items
-rw-r--r-- 1 hdadmin supergroup 1016 2013-03-13 20:11 /input/input_test.txt
[hdadmin@localhost bin]$ hadoop dfs -cat /input/input_test.txt
List HDFS File
Read HDFS File
Retrieve HDFS File to Local File System
Please see also http://hadoop.apache.org/docs/r1.0.4/commands_manual.html
[hdadmin@localhost bin]$ hadoop dfs -copyToLocal /input/input_test.txt /tmp/file.txt](https://image.slidesharecdn.com/bigdatahadoopamazonv2-130803035124-phpapp02/85/Big-Data-Hadoop-using-Amazon-Elastic-MapReduce-Hands-On-Labs-14-320.jpg)
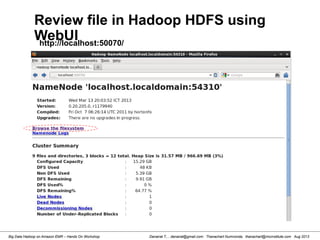
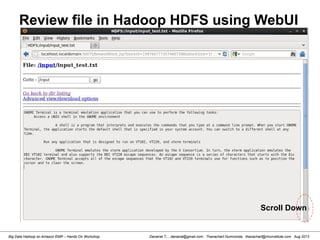
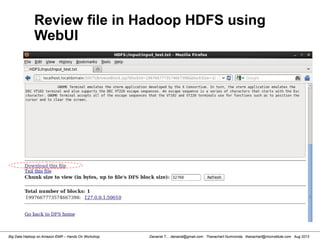
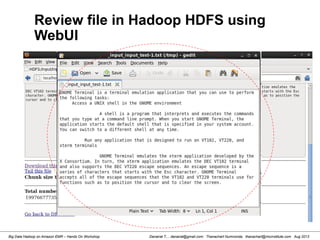

![Danairat T., , danairat@gmail.com: Thanachart Numnonda, thanachart@imcinstitute.com Aug 2013Big Data Hadoop on Amazon EMR – Hands On Workshop
Review Content from System shell
[hdadmin@localhost current]$ cd /app/hadoop/tmp/dfs/data/current
[hdadmin@localhost current]$ ls -l
total 24
-rw-r--r--. 1 hdadmin hadoop 1016 Mar 13 20:11 blk_1997667773574667398
-rw-r--r--. 1 hdadmin hadoop 15 Mar 13 20:11 blk_1997667773574667398_1005.meta
-rw-r--r--. 1 hdadmin hadoop 4 Mar 13 20:04 blk_-6735227193197163844
-rw-r--r--. 1 hdadmin hadoop 11 Mar 13 20:04 blk_-6735227193197163844_1004.meta
-rw-r--r--. 1 hdadmin hadoop 482 Mar 13 20:18 dncp_block_verification.log.curr
-rw-r--r--. 1 hdadmin hadoop 154 Mar 13 20:03 VERSION
[hdadmin@localhost current]$ more blk_1997667773574667398
GNOME Terminal is a terminal emulation application that you can use to perform the following tasks:
Access a UNIX shell in the GNOME environment
A shell is a program that interprets and executes the commands that you type at a
command lin
e prompt. When you start GNOME Terminal, the application starts the default shell that is specified
in your system account. You can switch to a different shell at any time.
[hdadmin@localhost current]$](https://image.slidesharecdn.com/bigdatahadoopamazonv2-130803035124-phpapp02/85/Big-Data-Hadoop-using-Amazon-Elastic-MapReduce-Hands-On-Labs-23-320.jpg)
![Danairat T., , danairat@gmail.com: Thanachart Numnonda, thanachart@imcinstitute.com Aug 2013Big Data Hadoop on Amazon EMR – Hands On Workshop
Removing data from HDFS using
Shell Command
hdadmin@localhost detach]$ hadoop dfs -rm /input/input_test.txt
Deleted hdfs://localhost:54310/input/input_test.txt
hdadmin@localhost detach]$](https://image.slidesharecdn.com/bigdatahadoopamazonv2-130803035124-phpapp02/85/Big-Data-Hadoop-using-Amazon-Elastic-MapReduce-Hands-On-Labs-24-320.jpg)



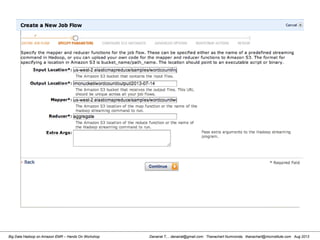
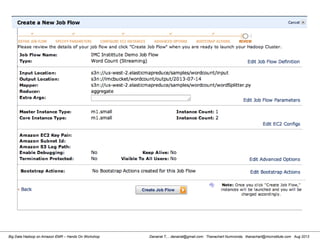

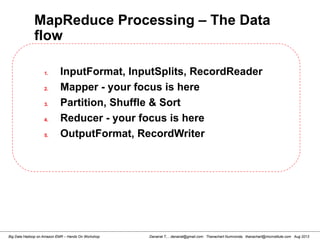
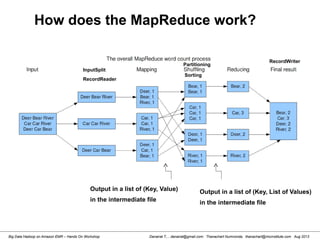
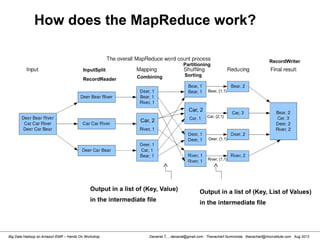







![Danairat T., , danairat@gmail.com: Thanachart Numnonda, thanachart@imcinstitute.com Aug 2013Big Data Hadoop on Amazon EMR – Hands On Workshop
Wordcount (HelloWord in Hadoop)
38. public static void main(String[] args) throws Exception {
39. JobConf conf = new JobConf(WordCount.class);
40. conf.setJobName("wordcount");
41.
42. conf.setOutputKeyClass(Text.class);
43. conf.setOutputValueClass(IntWritable.class);
44.
45. conf.setMapperClass(Map.class);
46.
47. conf.setReducerClass(Reduce.class);
48.
49. conf.setInputFormat(TextInputFormat.class);
50. conf.setOutputFormat(TextOutputFormat.class);
51.
52. FileInputFormat.setInputPaths(conf, new Path(args[0]));
53. FileOutputFormat.setOutputPath(conf, new Path(args[1]));
54.
55. JobClient.runJob(conf);
57. }
58. }
59.](https://image.slidesharecdn.com/bigdatahadoopamazonv2-130803035124-phpapp02/85/Big-Data-Hadoop-using-Amazon-Elastic-MapReduce-Hands-On-Labs-53-320.jpg)



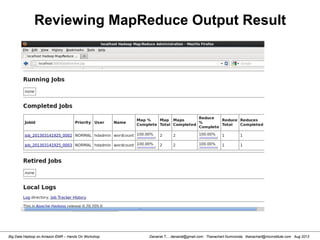
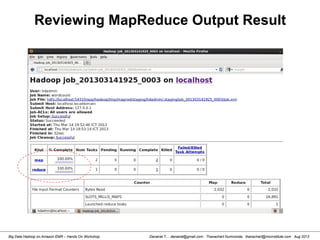
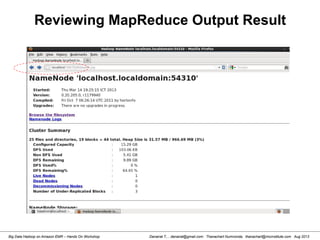
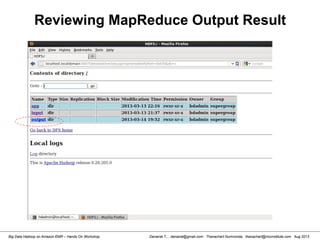
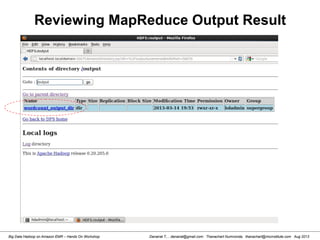



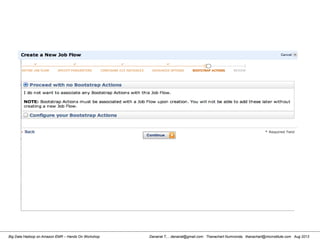
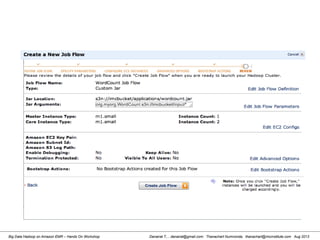
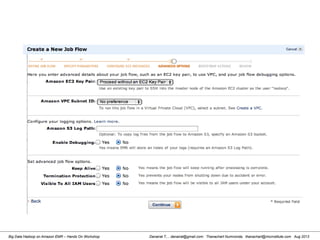










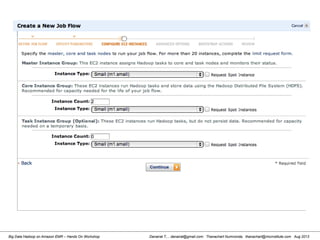
![Danairat T., , danairat@gmail.com: Thanachart Numnonda, thanachart@imcinstitute.com Aug 2013Big Data Hadoop on Amazon EMR – Hands On Workshop
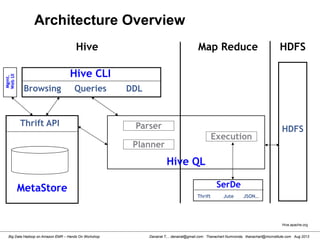
2. Reviewing Hive Table in HDFS
[hdadmin@localhost hdadmin]$ hadoop fs -ls /user/hive/warehouse
Found 1 items
drwxr-xr-x - hdadmin supergroup 0 2013-03-17 17:51 /user/hive/warehouse/test_tbl
[hdadmin@localhost hdadmin]$
Review Hive Table from
HDFS WebUI](https://image.slidesharecdn.com/bigdatahadoopamazonv2-130803035124-phpapp02/85/Big-Data-Hadoop-using-Amazon-Elastic-MapReduce-Hands-On-Labs-84-320.jpg)





![Danairat T., , danairat@gmail.com: Thanachart Numnonda, thanachart@imcinstitute.com Aug 2013Big Data Hadoop on Amazon EMR – Hands On Workshop
6. Reviewing Hive Table Content from HDFS Command and WebUI
[hdadmin@localhost hdadmin]$ hadoop fs -ls /user/hive/warehouse/test_tbl
Found 1 items
-rw-r--r-- 1 hdadmin supergroup 59 2013-03-17 18:08
/user/hive/warehouse/test_tbl/test_tbl_data.csv
[hdadmin@localhost hdadmin]$
[hdadmin@localhost hdadmin]$ hadoop fs -cat
/user/hive/warehouse/test_tbl/test_tbl_data.csv
1,USA
62,Indonesia
63,Philippines
65,Singapore
66,Thailand
[hdadmin@localhost hdadmin]$](https://image.slidesharecdn.com/bigdatahadoopamazonv2-130803035124-phpapp02/85/Big-Data-Hadoop-using-Amazon-Elastic-MapReduce-Hands-On-Labs-90-320.jpg)

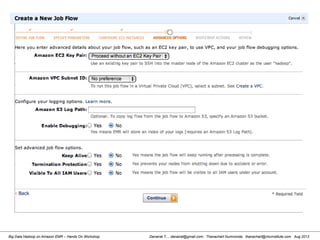
![Danairat T., , danairat@gmail.com: Thanachart Numnonda, thanachart@imcinstitute.com Aug 2013Big Data Hadoop on Amazon EMR – Hands On Workshop
Review Hive Table Created in HDFS and WebUI
[hdadmin@localhost hdadmin]$ hadoop fs -ls /user/hive/warehouse/test_tbl
Found 1 items
-rw-r--r-- 1 hdadmin supergroup 3510 2013-03-17 18:25
/user/hive/warehouse/test_tbl/test_tbl_data_updated.csv
[hdadmin@localhost hdadmin]$
[hdadmin@localhost hdadmin]$ hadoop fs -cat
/user/hive/warehouse/test_tbl/test_tbl_data_updated.csv
93,Afghanistan
355,Albania
213,Algeria
1684,AmericanSamoa
376,Andorra
244,Angola
1264,Anguilla
672,Antarctica
1268,AntiguaandBarbuda
54,Argentina
374,Armenia
297,Aruba
61,Australia
43,Austria
994,Azerbaijan
1242,Bahamas
973,Bahrain](https://image.slidesharecdn.com/bigdatahadoopamazonv2-130803035124-phpapp02/85/Big-Data-Hadoop-using-Amazon-Elastic-MapReduce-Hands-On-Labs-92-320.jpg)






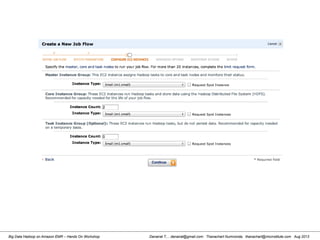
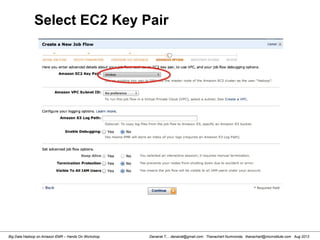
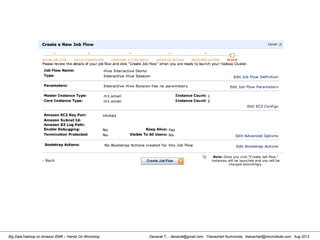
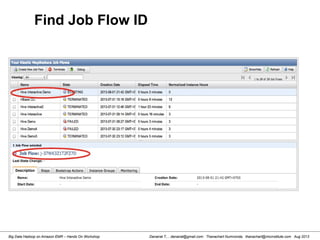









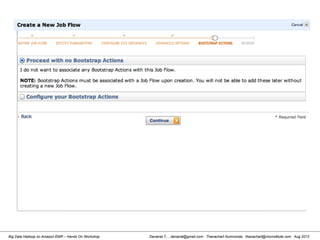
![Danairat T., , danairat@gmail.com: Thanachart Numnonda, thanachart@imcinstitute.com Aug 2013Big Data Hadoop on Amazon EMR – Hands On Workshop
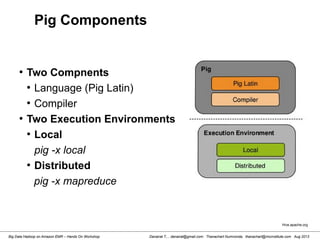
Starting Pig Command Line
[hdadmin@localhost ~]$ pig -x local
2013-08-01 10:29:00,027 [main] INFO org.apache.pig.Main - Apache Pig
version 0.11.1 (r1459641) compiled Mar 22 2013, 02:13:53
2013-08-01 10:29:00,027 [main] INFO org.apache.pig.Main - Logging error
messages to: /home/hdadmin/pig_1375327740024.log
2013-08-01 10:29:00,066 [main] INFO org.apache.pig.impl.util.Utils -
Default bootup file /home/hdadmin/.pigbootup not found
2013-08-01 10:29:00,212 [main] INFO
org.apache.pig.backend.hadoop.executionengine.HExecutionEngine - Connecting
to hadoop file system at: file:///
grunt>](https://image.slidesharecdn.com/bigdatahadoopamazonv2-130803035124-phpapp02/85/Big-Data-Hadoop-using-Amazon-Elastic-MapReduce-Hands-On-Labs-119-320.jpg)
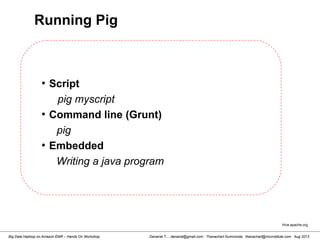
![Danairat T., , danairat@gmail.com: Thanachart Numnonda, thanachart@imcinstitute.com Aug 2013Big Data Hadoop on Amazon EMR – Hands On Workshop
countryFilter.pig
A = load 'hdi-data.csv' using PigStorage(',') AS (id:int, country:chararray, hdi:float,
lifeex:int, mysch:i
nt, eysch:int, gni:int);
B = FILTER A BY gni > 2000;
C = ORDER B BY gni;
dump C;
#Preparing Data
[hdadmin@localhost ~]$ cp hadoop_data/hdi-data.csv /usr/local/pig-0.11.1/bin/
#Edit Your Script
[hdadmin@localhost ~]$ cd /usr/local/pig-0.11.1/bin/
[hdadmin@localhost ~]$ vi countryFilter.pig
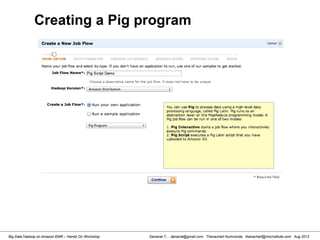
Writing a Pig Script](https://image.slidesharecdn.com/bigdatahadoopamazonv2-130803035124-phpapp02/85/Big-Data-Hadoop-using-Amazon-Elastic-MapReduce-Hands-On-Labs-120-320.jpg)
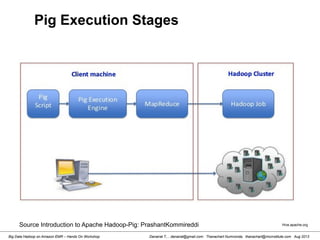
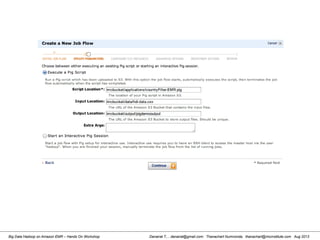
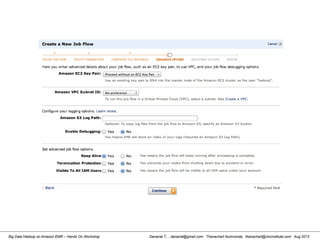
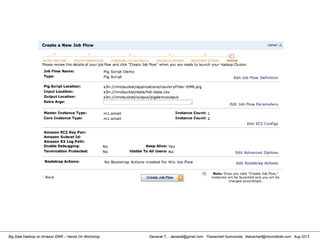
![Danairat T., , danairat@gmail.com: Thanachart Numnonda, thanachart@imcinstitute.com Aug 2013Big Data Hadoop on Amazon EMR – Hands On Workshop
[hdadmin@localhost ~]$ cd /usr/local/pig-0.11.1/bin/
[hdadmin@localhost ~]$ pig -x local
grunt > run countryFilter.pig
....
(150,Cameroon,0.482,51,5,10,2031)
(126,Kyrgyzstan,0.615,67,9,12,2036)
(156,Nigeria,0.459,51,5,8,2069)
(154,Yemen,0.462,65,2,8,2213)
(138,Lao People's Democratic Republic,0.524,67,4,9,2242)
(153,Papua New Guinea,0.466,62,4,5,2271)
(165,Djibouti,0.43,57,3,5,2335)
(129,Nicaragua,0.589,74,5,10,2430)
(145,Pakistan,0.504,65,4,6,2550)
Running a Pig Script](https://image.slidesharecdn.com/bigdatahadoopamazonv2-130803035124-phpapp02/85/Big-Data-Hadoop-using-Amazon-Elastic-MapReduce-Hands-On-Labs-121-320.jpg)








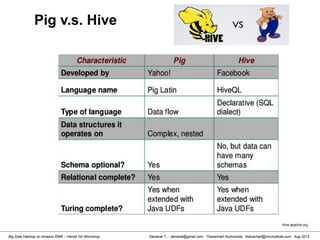
![Danairat T., , danairat@gmail.com: Thanachart Numnonda, thanachart@imcinstitute.com Aug 2013Big Data Hadoop on Amazon EMR – Hands On Workshop
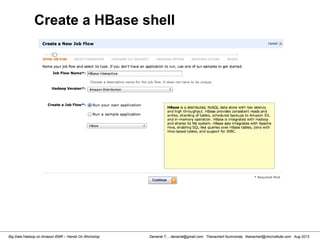
Starting HBase shell
[hdadmin@localhost ~]$ start-hbase.sh
starting master, logging to /usr/local/hbase-0.94.10/logs/hbase-hdadmin-
master-localhost.localdomain.out
[hdadmin@localhost ~]$ jps
3064 TaskTracker
2836 SecondaryNameNode
2588 NameNode
3513 Jps
3327 HMaster
2938 JobTracker
2707 DataNode
[hdadmin@localhost ~]$ hbase shell
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 0.94.10, r1504995, Fri Jul 19 20:24:16 UTC 2013
hbase(main):001:0>](https://image.slidesharecdn.com/bigdatahadoopamazonv2-130803035124-phpapp02/85/Big-Data-Hadoop-using-Amazon-Elastic-MapReduce-Hands-On-Labs-137-320.jpg)


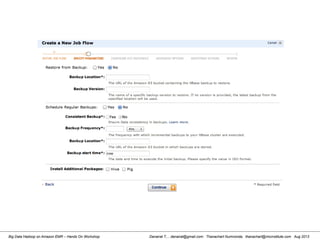
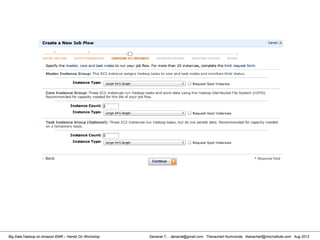
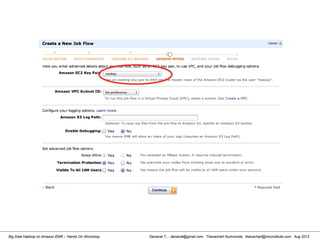
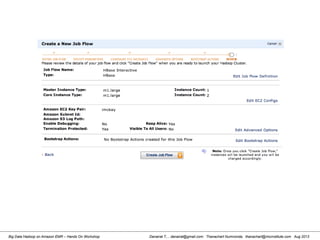






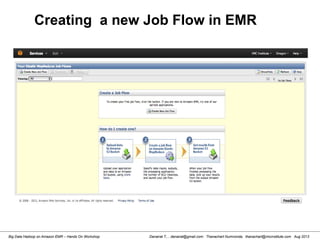
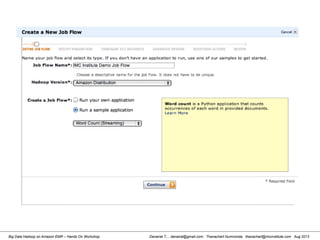
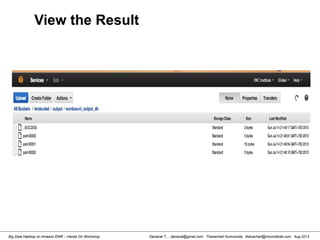
This document provides an overview of a hands-on workshop on running Hadoop on Amazon Elastic MapReduce. It discusses setting up an AWS account, signing up for necessary services like S3 and EC2, creating an S3 bucket, generating access keys, creating a new EMR job flow, and viewing results from the S3 bucket. It also covers installing and running Hadoop locally, importing and reviewing data in HDFS, and the MapReduce programming model.









































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)













