Downloaded 25 times



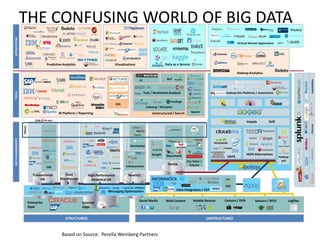
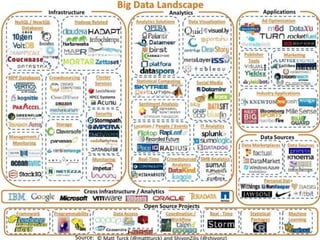
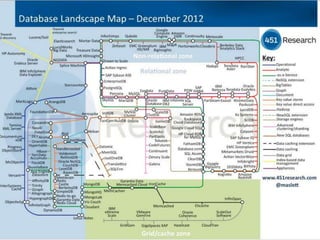

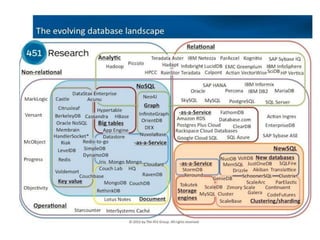
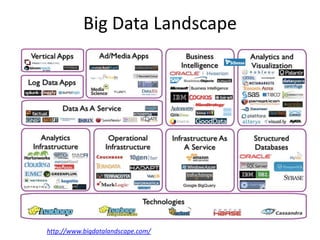
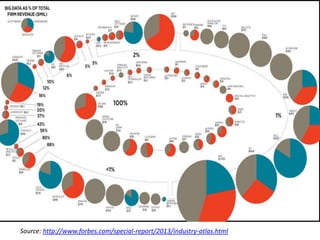


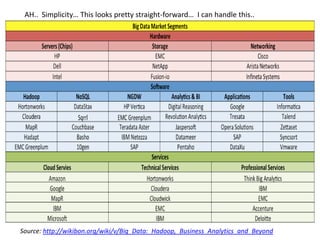



The document provides an agenda for a meeting on big data. It begins with acknowledging those in attendance from various companies. It then lists the agenda items which include an overview of big data connections, a presentation on demystifying big data, and success stories from SAP HANA startups. There will also be a quick poll of attendees and a networking session with Q&A. Additional slides provide background on the American Institute of Big Data Professionals and their mission to educate on big data solutions. Diagrams map the big data landscape and key vendors in related areas like analytics, visualization and predictive analytics.
















![[Strata NYC 2019] Turning big data into knowledge: Managing metadata and data...](https://cdn.slidesharecdn.com/ss_thumbnails/dkpstratanyc2019presentation-191004091826-thumbnail.jpg?width=640&height=640&fit=bounds)























































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)














