Hive
Hive Introduction
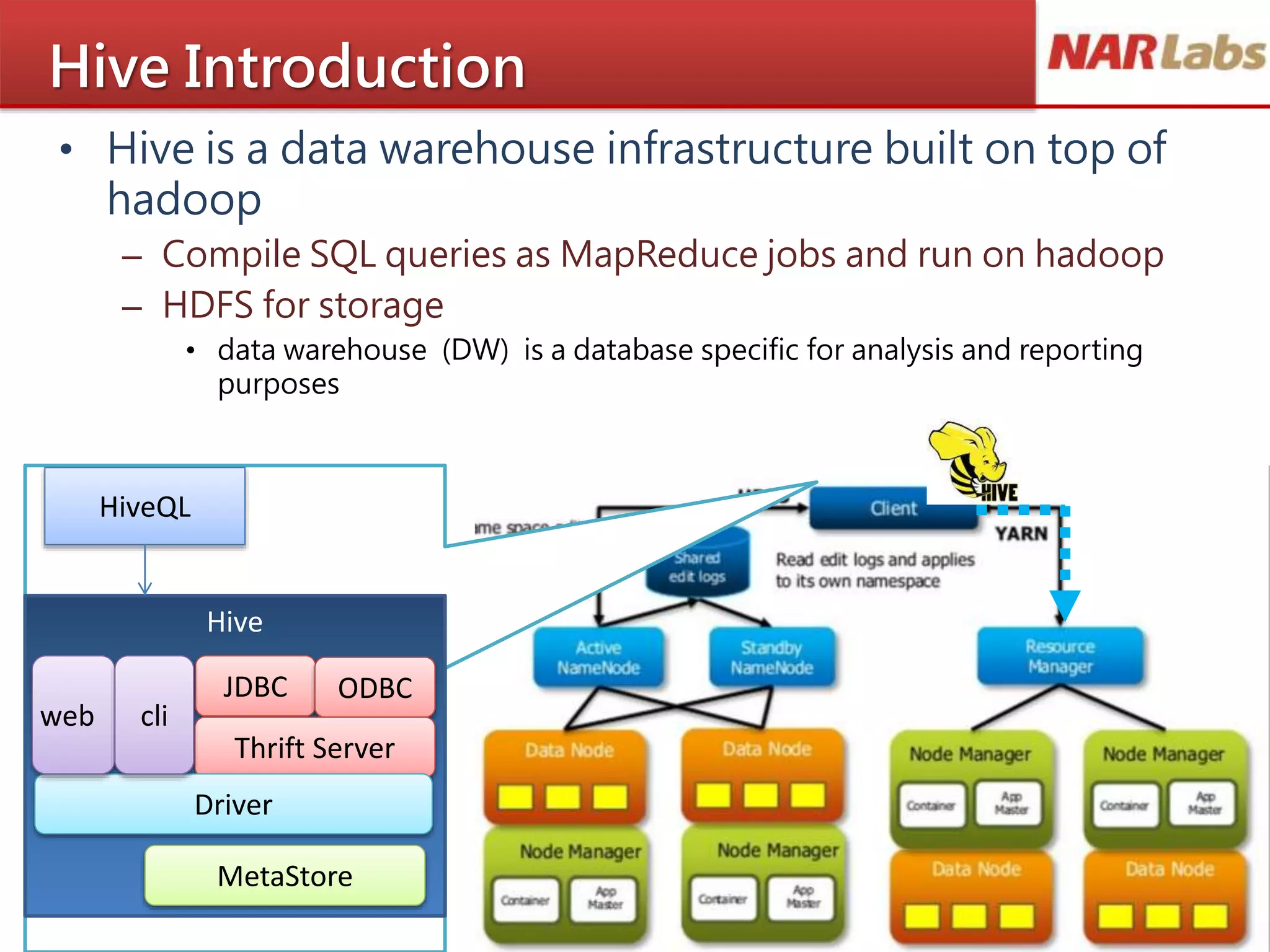
• Hiveis a data warehouse infrastructure built on top of
hadoop
– Compile SQL queries as MapReduce jobs and run on hadoop
– HDFS for storage
• data warehouse (DW) is a database specific for analysis and reporting
purposes
HiveQL
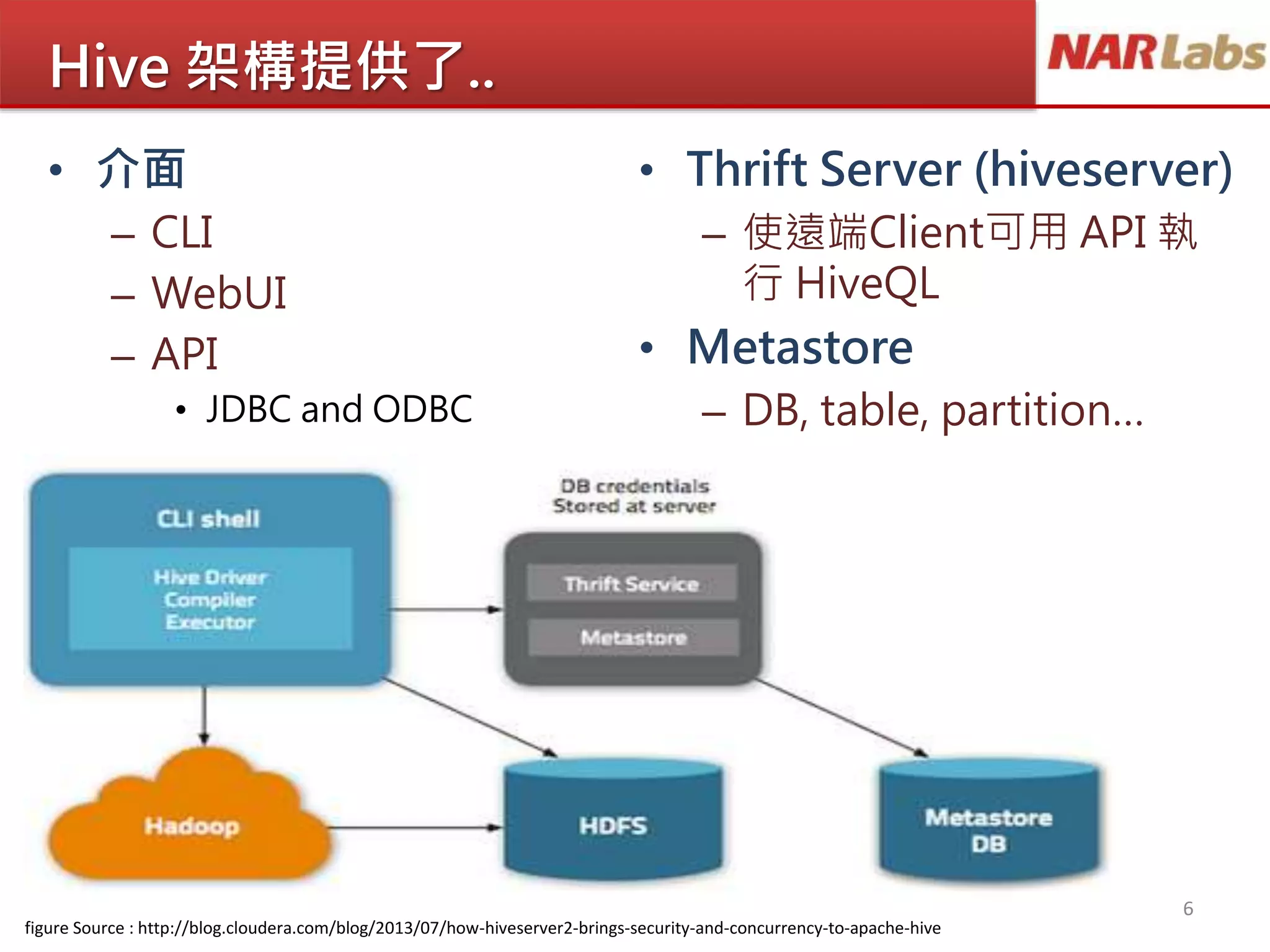
JDBC ODBC
Thrift Server
Driver
MetaStore
web cli
蜂 也會的程式設計
8
$ hive
hive>create table A(x int, y int, z int)
hive> load data local inpath ‘file1 ’ into table A;
hive> select * from A where y>10000
hive> insert table B select *
from A where y>10000
figure Source : http://hortonworks.com/blog/stinger-phase-2-the-journey-to-100x-faster-hive/
9.
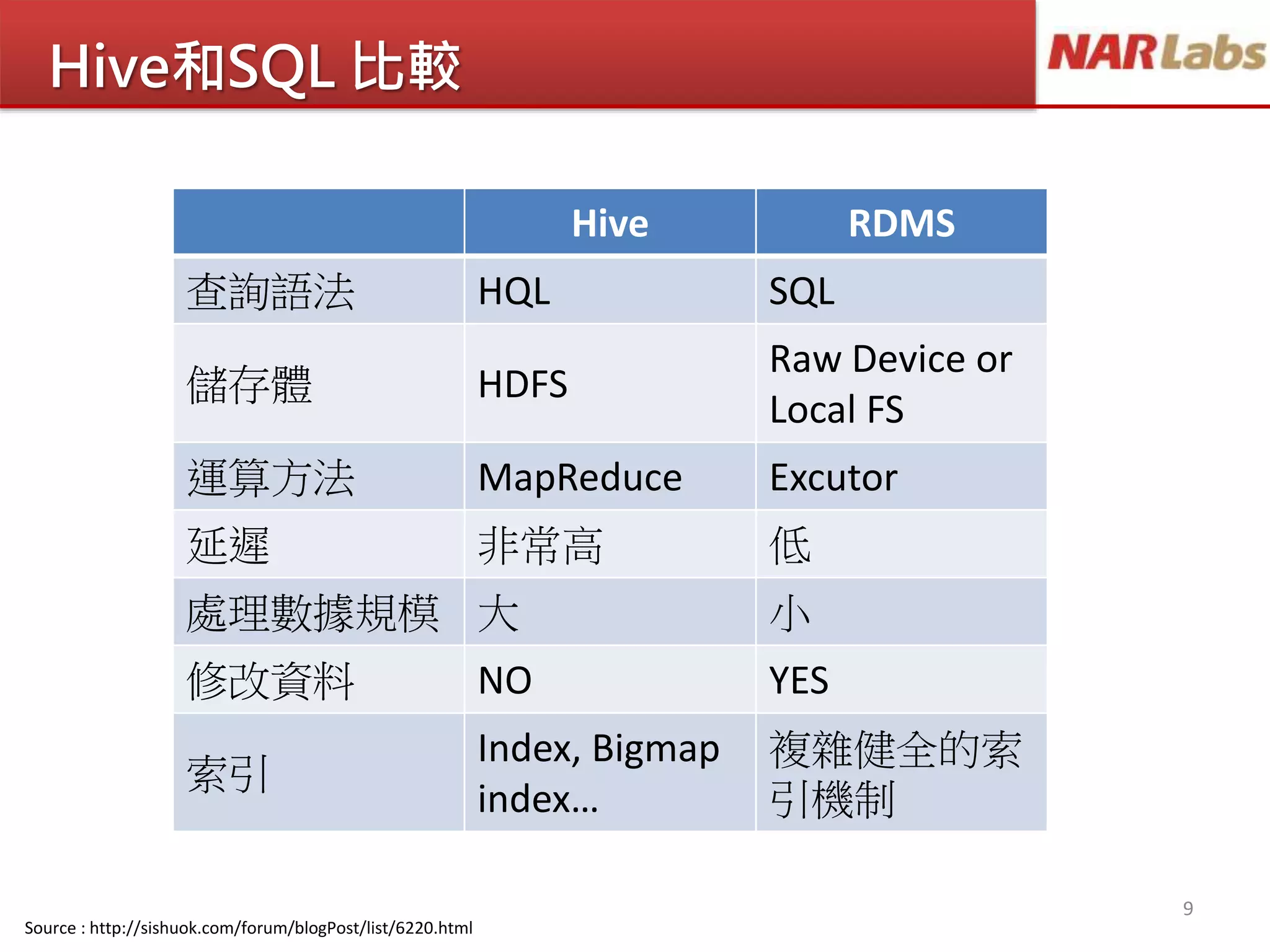
Hive和SQL 比較
Hive RDMS
查詢語法HQL SQL
儲存體 HDFS
Raw Device or
Local FS
運算方法 MapReduce Excutor
延遲 非常高 低
處理數據規模 大 小
修改資料 NO YES
索引
Index, Bigmap
index…
複雜健全的索
引機制
9
Source : http://sishuok.com/forum/blogPost/list/6220.html
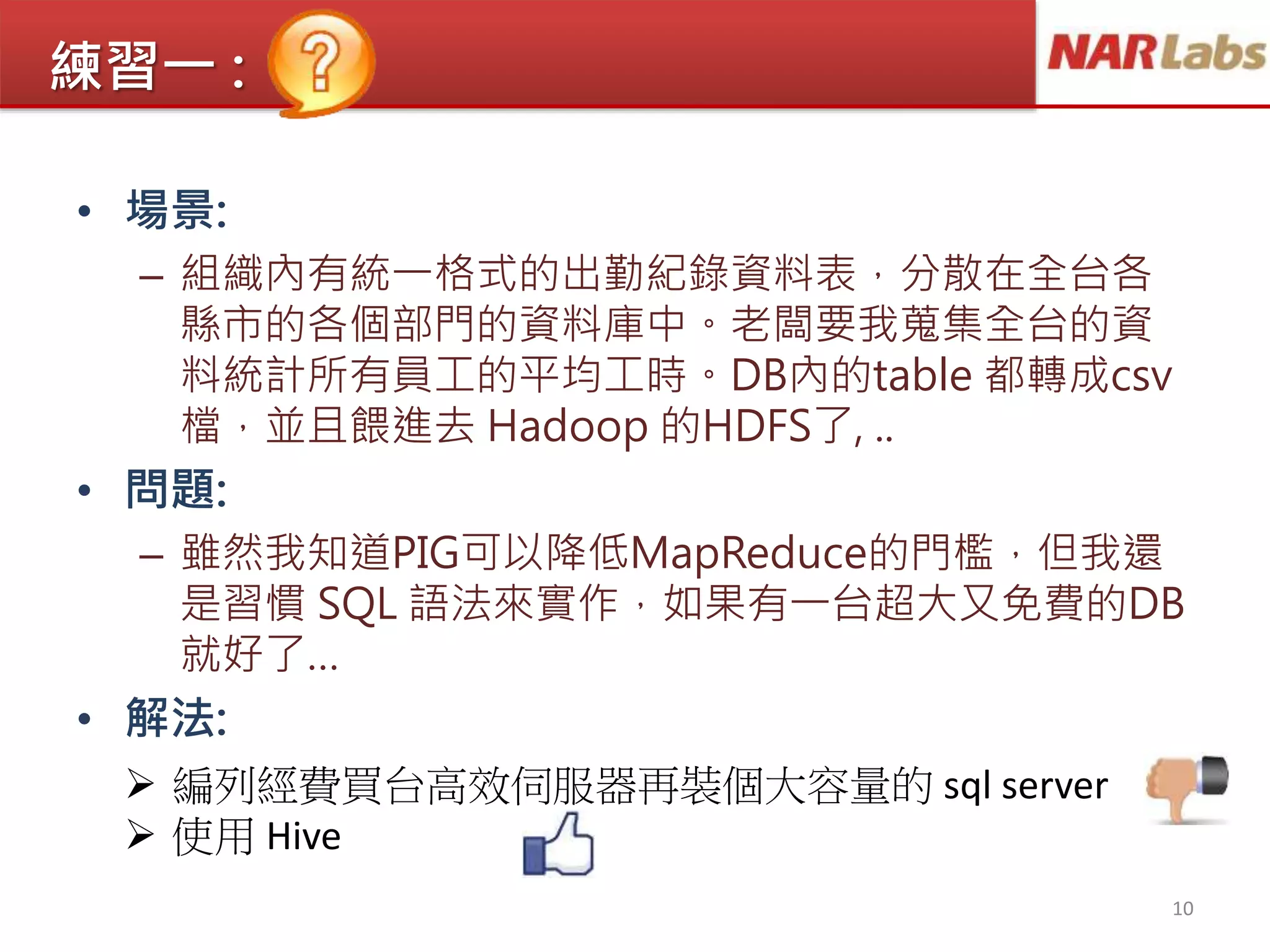
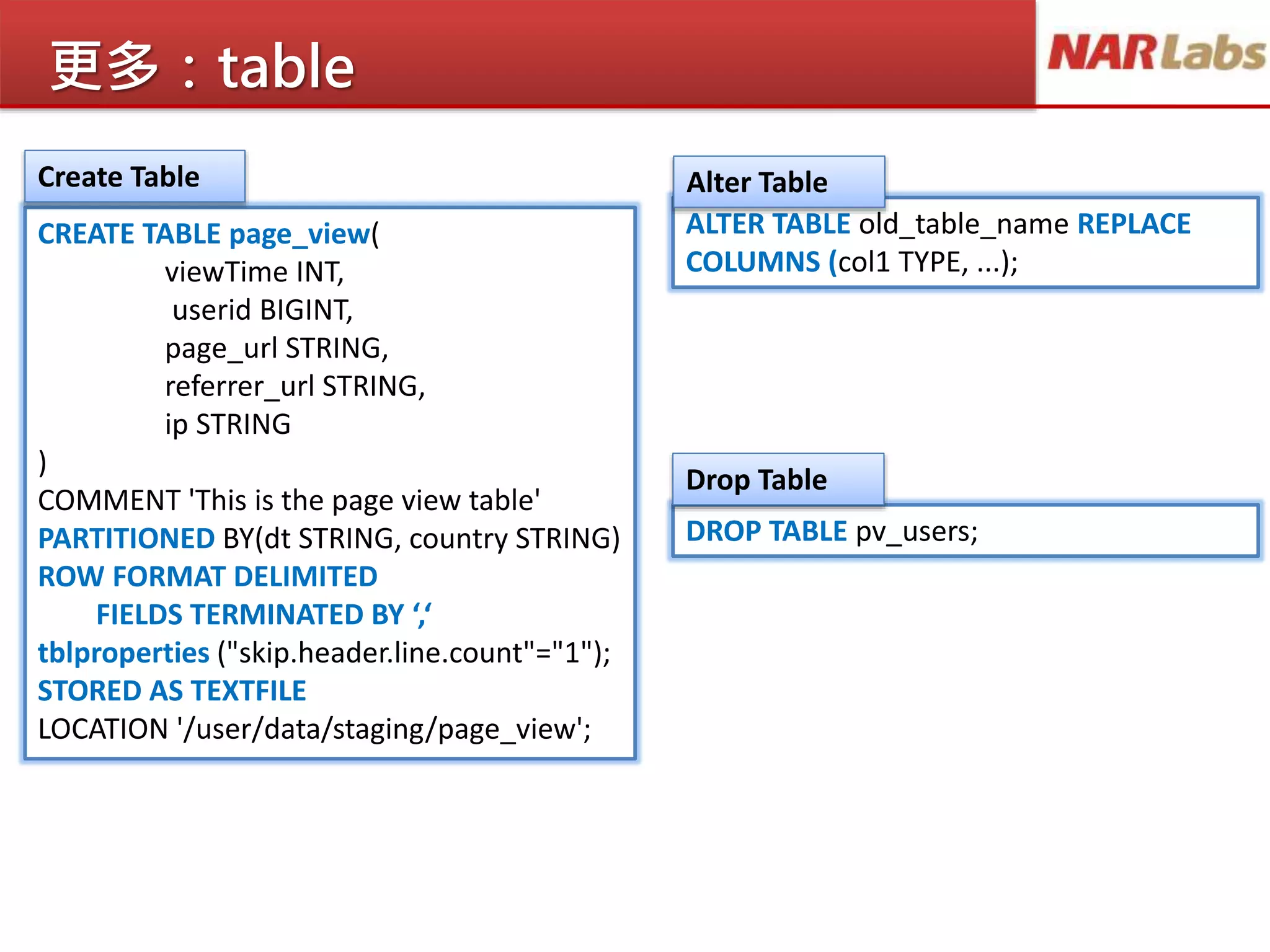
更多:table
CREATE TABLE page_view(
viewTimeINT,
userid BIGINT,
page_url STRING,
referrer_url STRING,
ip STRING
)
COMMENT 'This is the page view table'
PARTITIONED BY(dt STRING, country STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘,‘
tblproperties ("skip.header.line.count"="1");
STORED AS TEXTFILE
LOCATION '/user/data/staging/page_view';
DROP TABLE pv_users;
ALTER TABLE old_table_name REPLACE
COLUMNS (col1 TYPE, ...);
Create Table Alter Table
Drop Table
14.
更多:data
LOAD DATA
INPATH '/user/data/pv_2008-06-08_us.txt'
INTOTABLE page_view PARTITION(date='2008-06-08',
country='US')
INSERT OVERWRITE TABLE xyz_com_page_views
SELECT page_views.*
FROM page_views
WHERE page_views.date >= '2008-03-01' AND
page_views.date <= '2008-03-31' AND
page_views.referrer_url like '%xyz.com';
Insert Table
Import data
15.
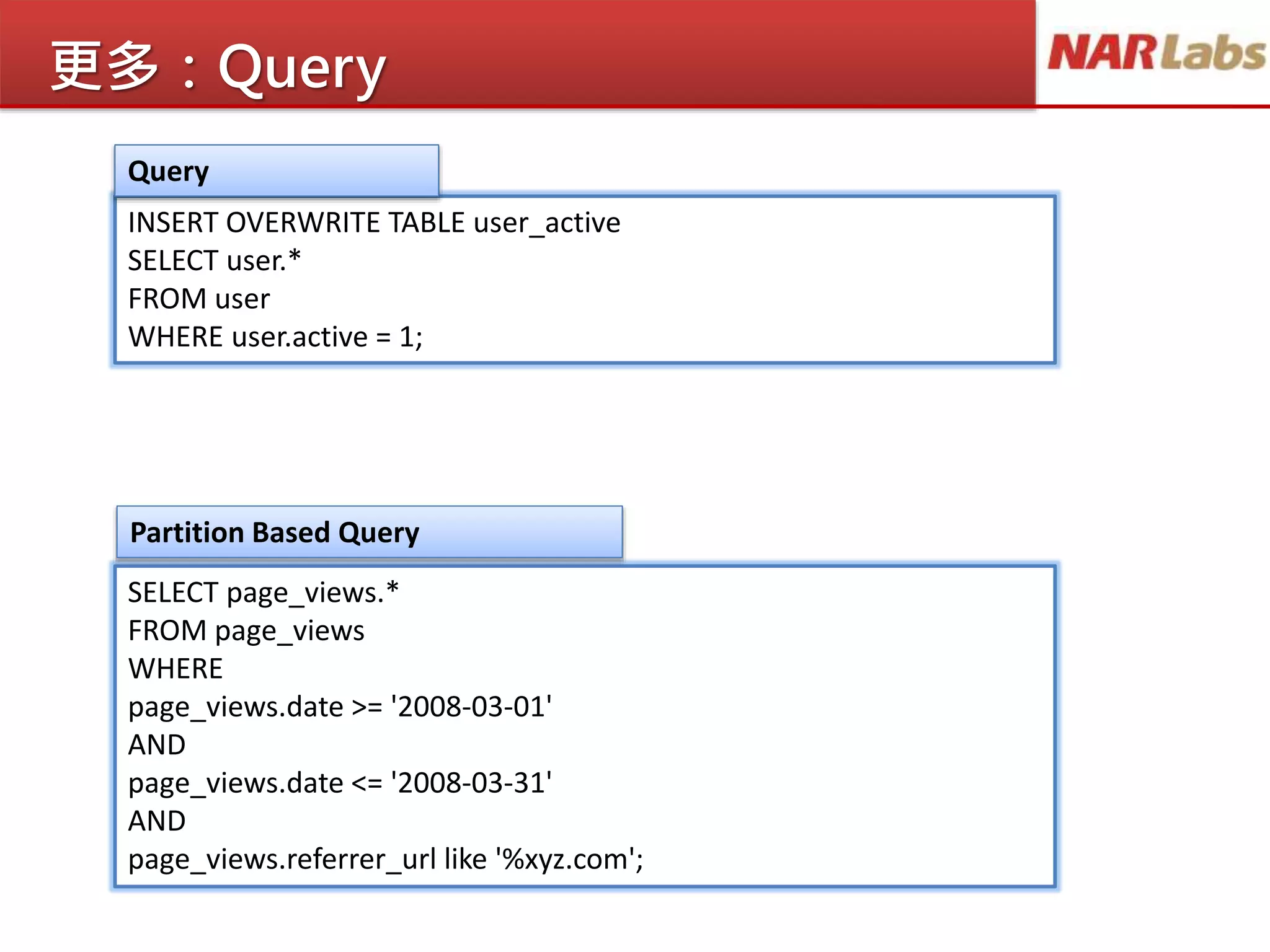
更多:Query
INSERT OVERWRITE TABLEuser_active
SELECT user.*
FROM user
WHERE user.active = 1;
SELECT page_views.*
FROM page_views
WHERE
page_views.date >= '2008-03-01'
AND
page_views.date <= '2008-03-31'
AND
page_views.referrer_url like '%xyz.com';
Query
Partition Based Query
16.
更多:aggregate
INSERT OVERWRITE TABLEpv_users
SELECT pv.*, u.gender, u.age
FROM user u
JOIN
page_view pv
ON (pv.userid = u.id)
WHERE pv.date = '2008-03-03';
INSERT OVERWRITE TABLE pv_gender_sum
SELECT pv_users.gender,
count (DISTINCT pv_users.userid),
collect_set (pv_users.name)
FROM pv_users
GROUP BY pv_users.gender;
Joins
Aggregations
17.
更多:union
• Tips:
– UNION: 兩個 SQL 語句所產生的欄位需要是同樣的資料種類
– JOIN : 透過相同鍵值將兩table合併成大的
INSERT OVERWRITE TABLE actions_users
SELECT u.id, actions.date
FROM (
SELECT av.uid AS uid
FROM action_video av
WHERE av.date = '2008-06-03'
UNION ALL
SELECT ac.uid AS uid
FROM action_comment ac
WHERE ac.date = '2008-06-03'
) actions JOIN users u ON(u.id = actions.uid);
UNION ALL
18.
更多:動動腦
name sex age
michaelmale 30
will male 35
shelley female 27
lucy female 57
steven male 30
sex_age.se
x
age name
female 57 lucy
male 35 will
See : http://willddy.github.io/2014/12/23/Hive-Get-MAX-MIN-Value-Rows.html
SELECT employee.sex_age.sex, employee.sex_age.age, name
FROM
employee JOIN
(
SELECT
max(sex_age.age) as max_age, sex_age.sex as sex
FROM employee
GROUP BY sex_age.sex
) maxage
ON employee.sex_age.age = maxage.max_age
AND employee.sex_age.sex = maxage.sex;
Solution
#20 mkdir source; cd source
wget "http://plvr.land.moi.gov.tw//Download?type=zip&fileName=lvr_landcsv.zip" -O lvr_landcsv.zip
unzip lvr_landcsv.zip
mkdir ../input;
for i in $(ls ./*.CSV ) ;do iconv -c -f big5 -t utf8 $i -o $i".utf8";done
mv *.utf8 ../input/
cd ../input/
rm *_BUILD.CSV.utf8
rm *_LAND.CSV.utf8
rm *_PARK.CSV.utf8
#21 A = LOAD 'myfile.txt' USING PigStorage('\t') AS (f1,f2,f3);
B = LOAD 'B.txt' ;
Y = FILTER A BY f1 == '8';
Y = FILTER A BY (f1 == '8') OR (NOT (f2+f3 > f1));
======
(1,{(1,2,3)})
(4,{(4,3,3),(4,2,1)})
(7,{(7,2,5)})
(8,{(8,4,3),(8,3,4)})
======
X = GROUP A BY f1;
====
(1,{(1,2,3)})
(4,{(4,3,3),(4,2,1)})
(7,{(7,2,5)})
(8,{(8,4,3),(8,3,4)})
====
Projection
X = FOREACH A GENERATE f1, f2;
====
1,2)
(4,2)
(8,3)
(4,3)
(7,2)
(8,4)
====
X = FOREACH A GENERATE f1+f2 as sumf1f2;
Y = FILTER X by sumf1f2 > 5.0;
=====
(6.0)
(11.0)
(7.0)
(9.0)
(12.0)
=====
C = COGROUP A BY $0 INNER, B BY $0 INNER;
====
(1,{(1,2,3)},{(1,3)})
(4,{(4,3,3),(4,2,1)},{(4,9),(4,6)})
(8,{(8,4,3),(8,3,4)},{(8,9)})
====