Downloaded 26 times




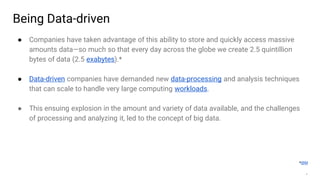









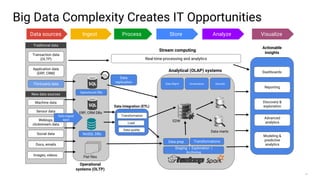

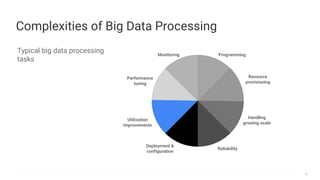


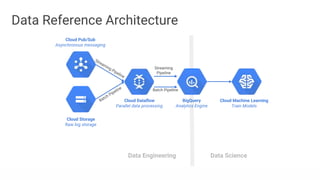

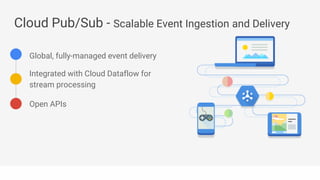


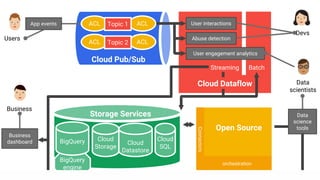




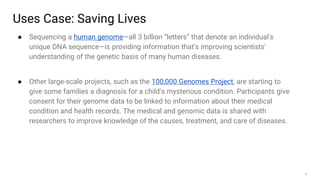








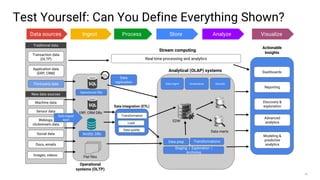


Big data refers to the massive amounts of data that are being created every day from sources like mobile devices, the internet, and sensors. As data volumes and variety have increased exponentially, traditional data processing tools are no longer adequate. This has led to the development of new techniques for data storage, processing, and analysis that can handle "big data". Some key aspects of big data include volume, velocity, and variety of data. Common big data uses cases include customer analytics, fraud detection, and scientific research. Terms related to big data include data pipelines, distributed processing, machine learning, and data visualization.




































![Big_Data_ppt[1] (1).pptx](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatappt11-230720100552-10b674be-thumbnail.jpg?width=640&height=640&fit=bounds)


















































