
![Who We Are Raghu Kashyap Director, Web Analytics [email_address] @ragskashyap http://kashyaps.com Jonathan Seidman Lead Engineer, Business Intelligence/Big Data Team Co-founder/organizer of Chicago Hadoop User Group http://www.meetup.com/Chicago-area-Hadoop-User-Group-CHUG/ and Chicago Big Data http://www.meetup.com/Chicago-Big-Data/ [email_address] @jseidman page](https://image.slidesharecdn.com/gartnerpeerforumsept2011-orbitzfinal-110914235622-phpapp01/75/Gartner-peer-forum-sept-2011-orbitz-2-2048.jpg)



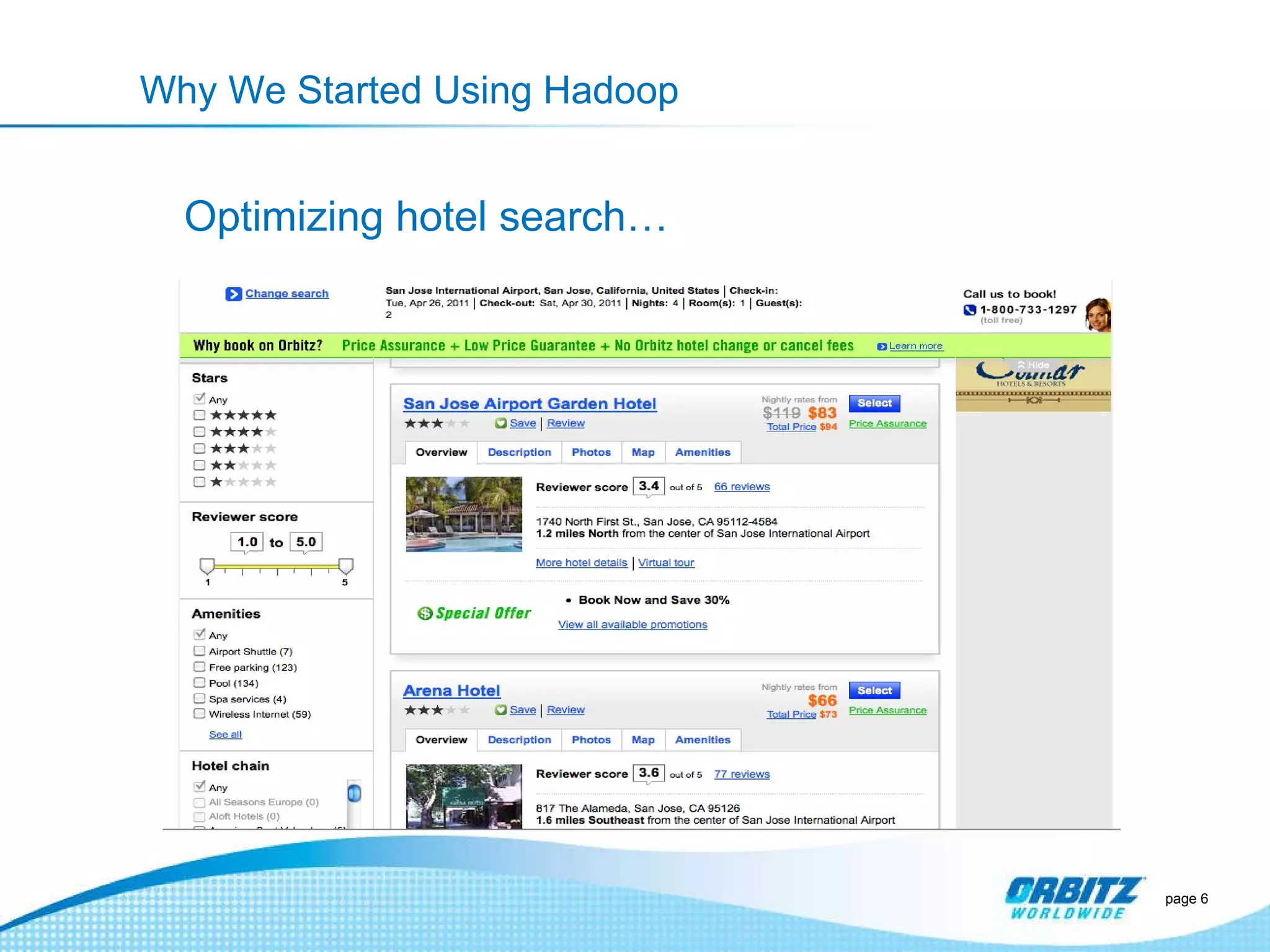


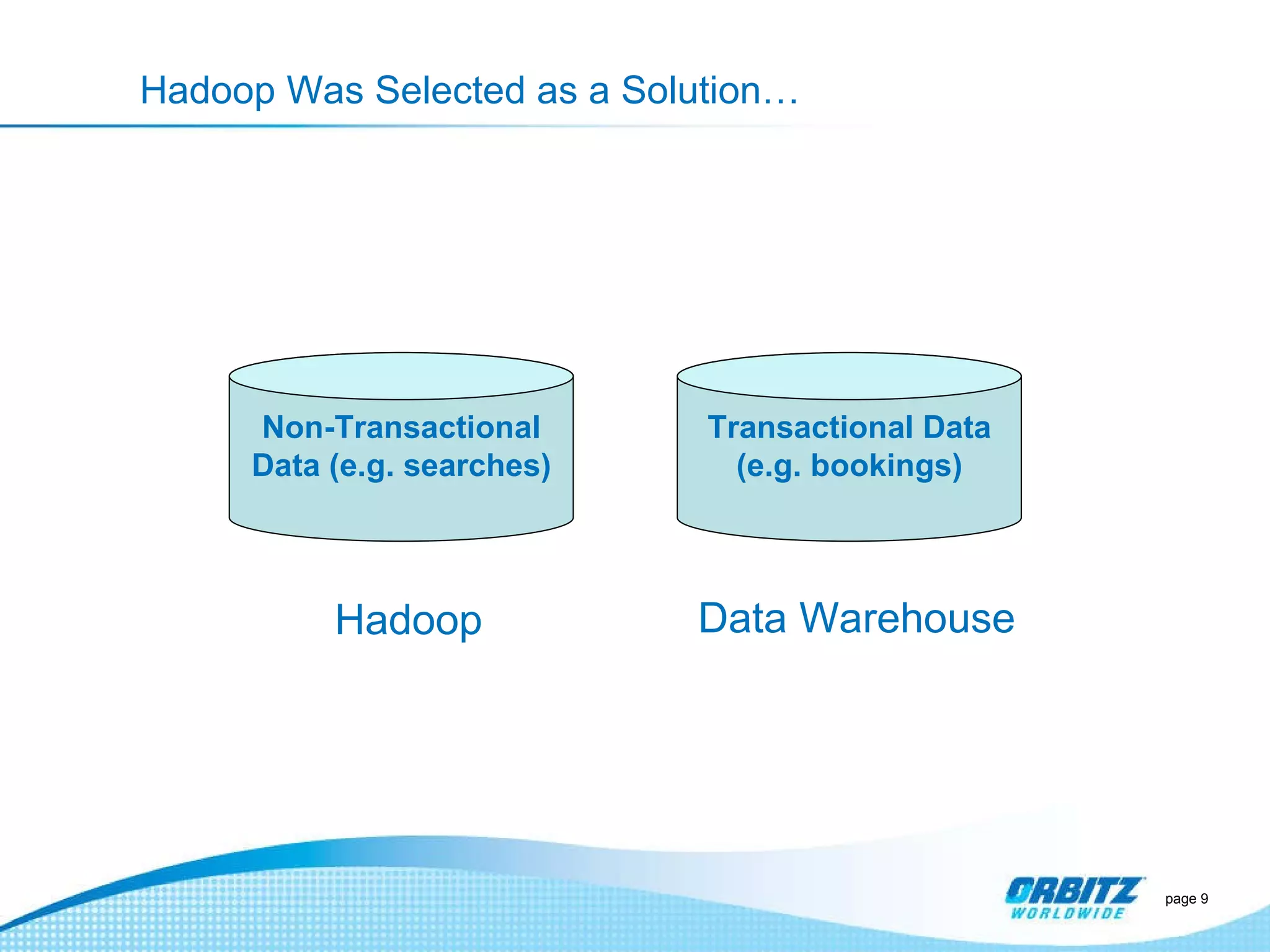

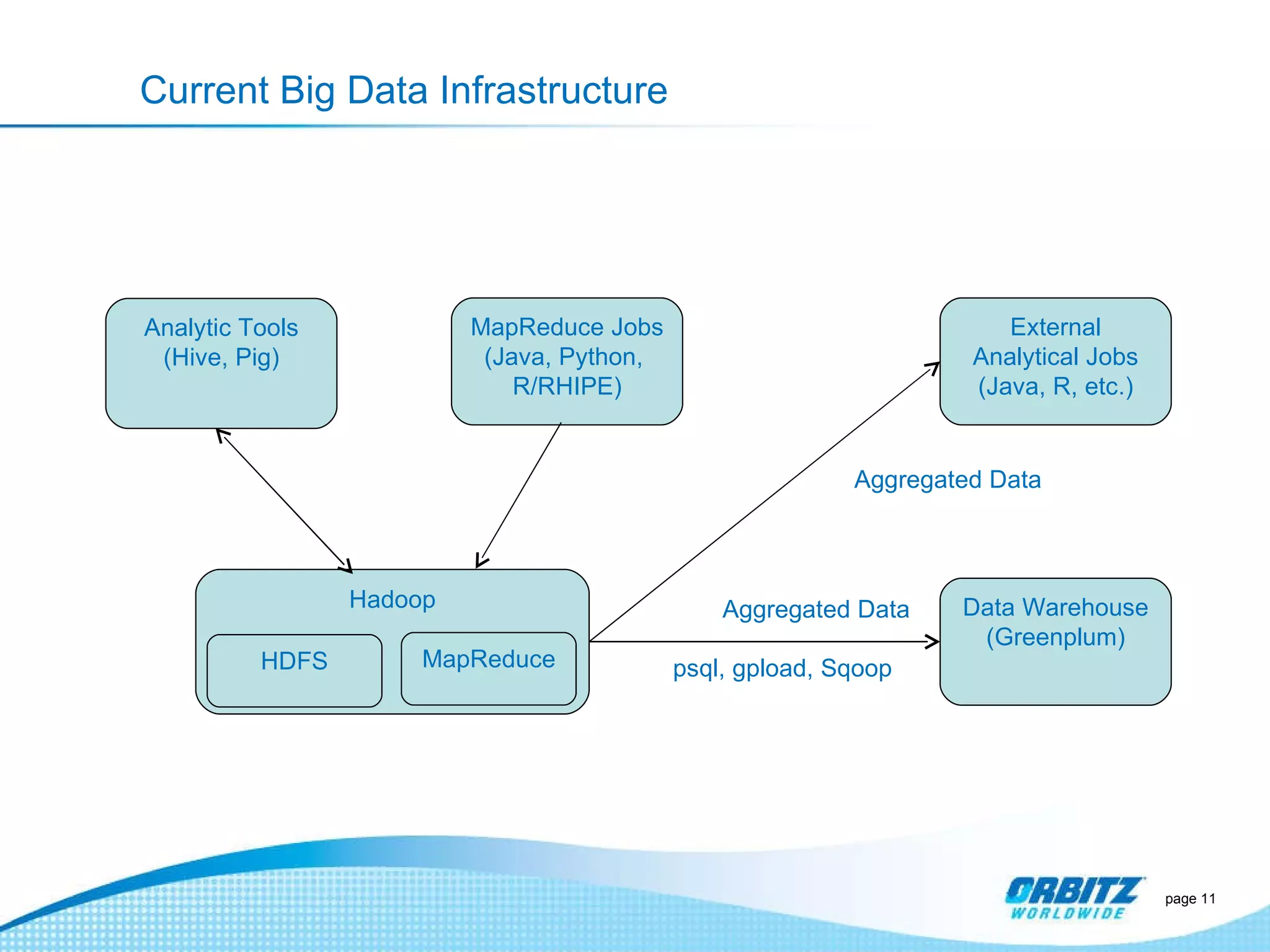

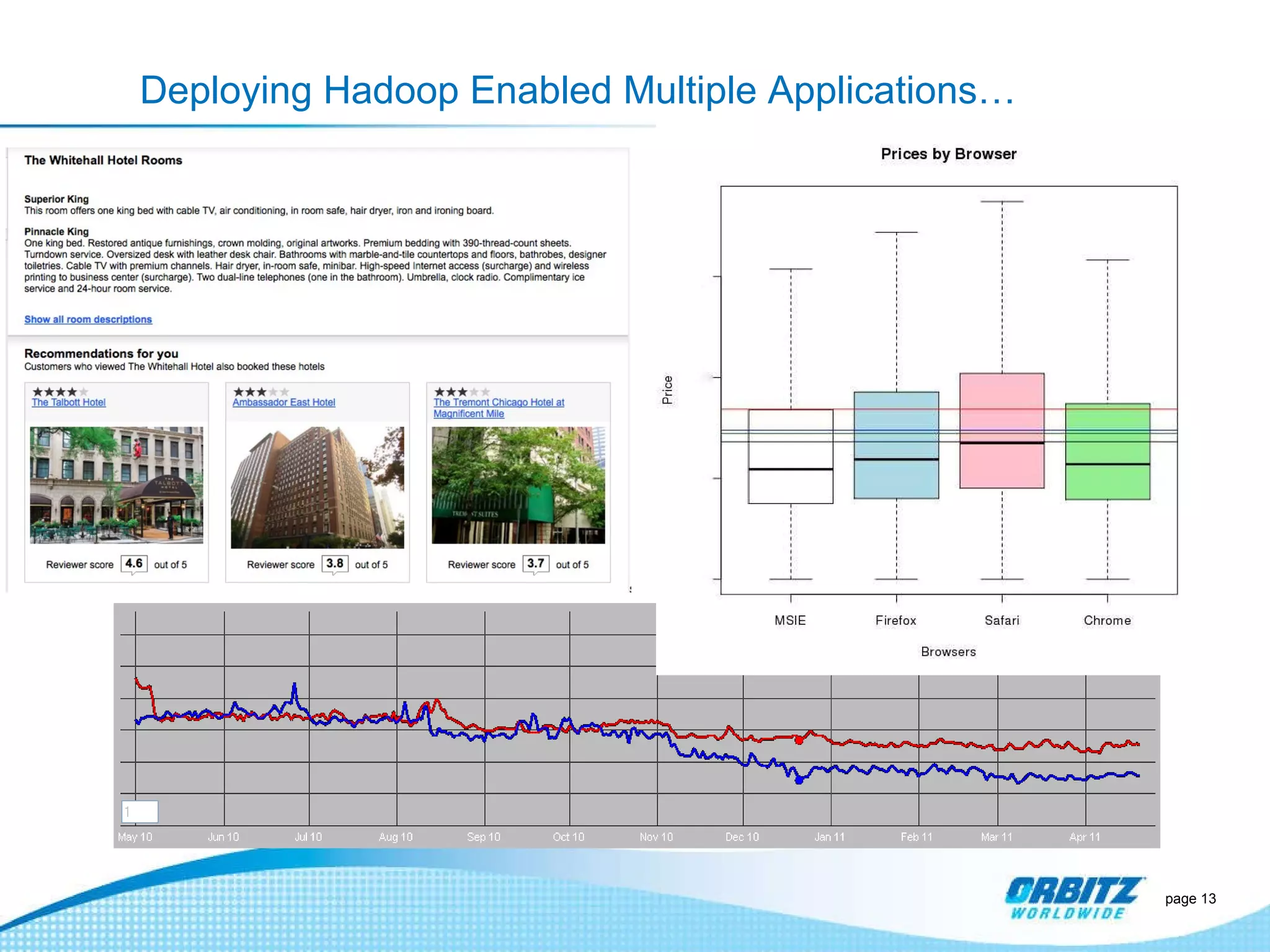


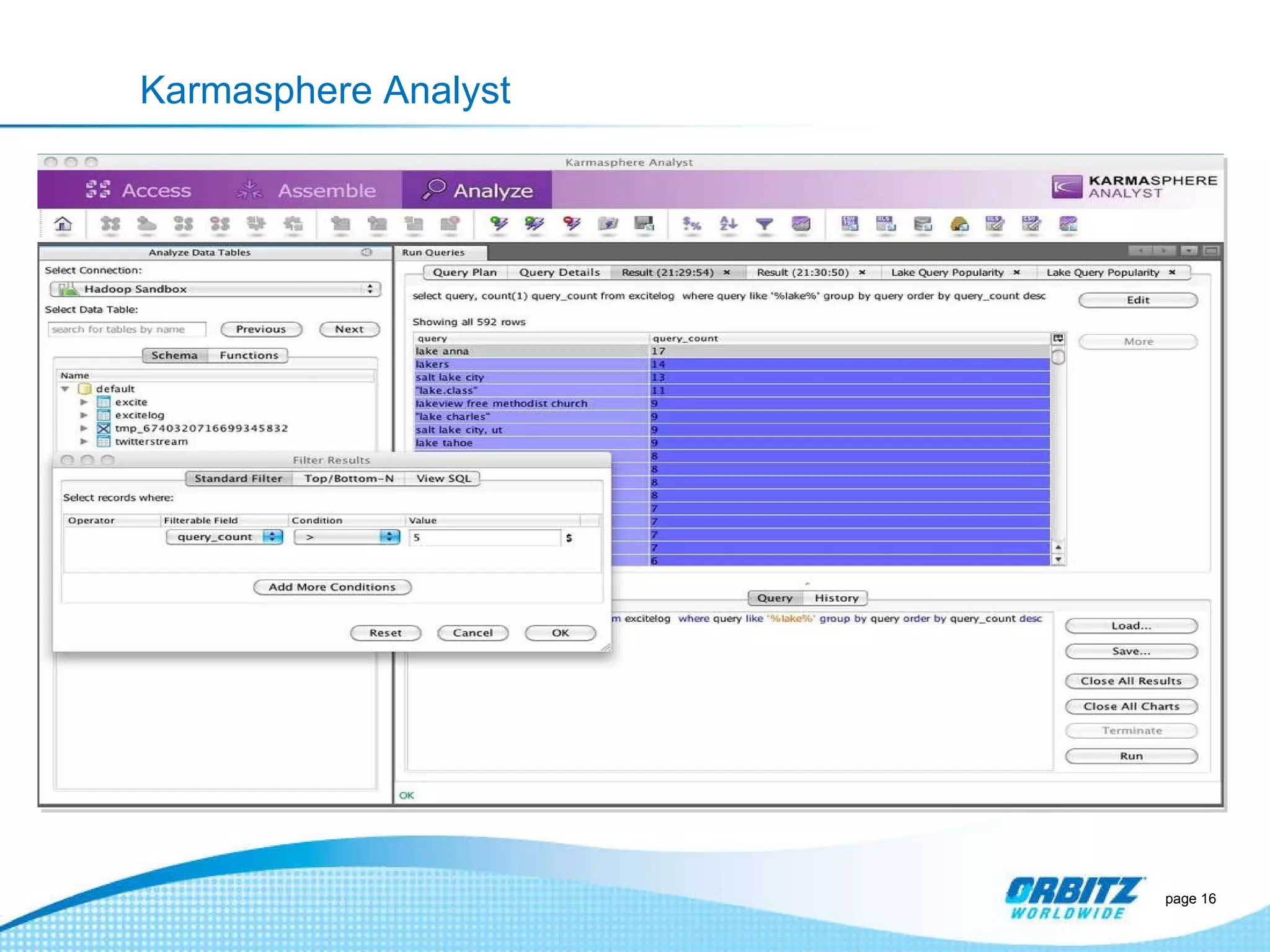
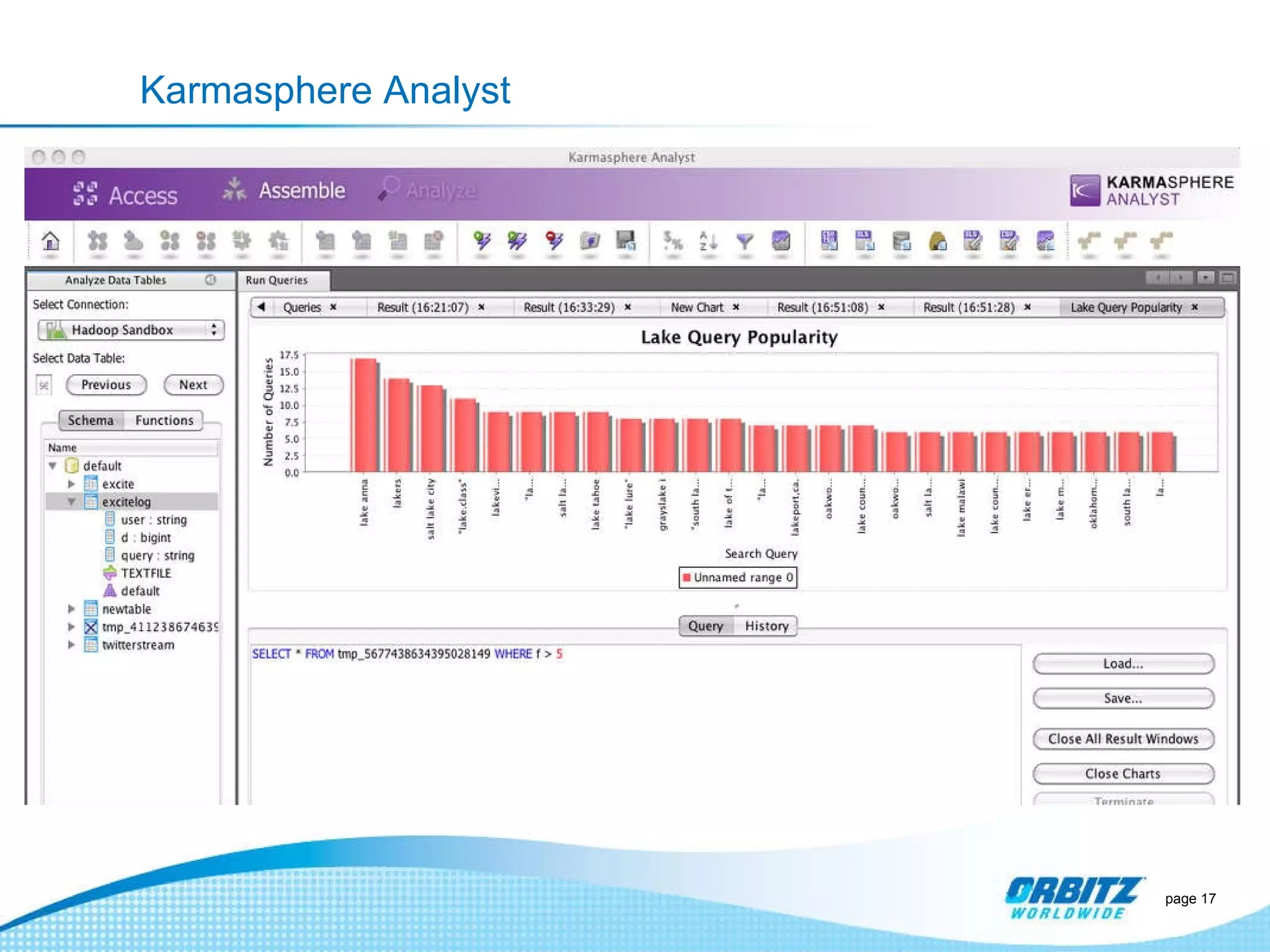
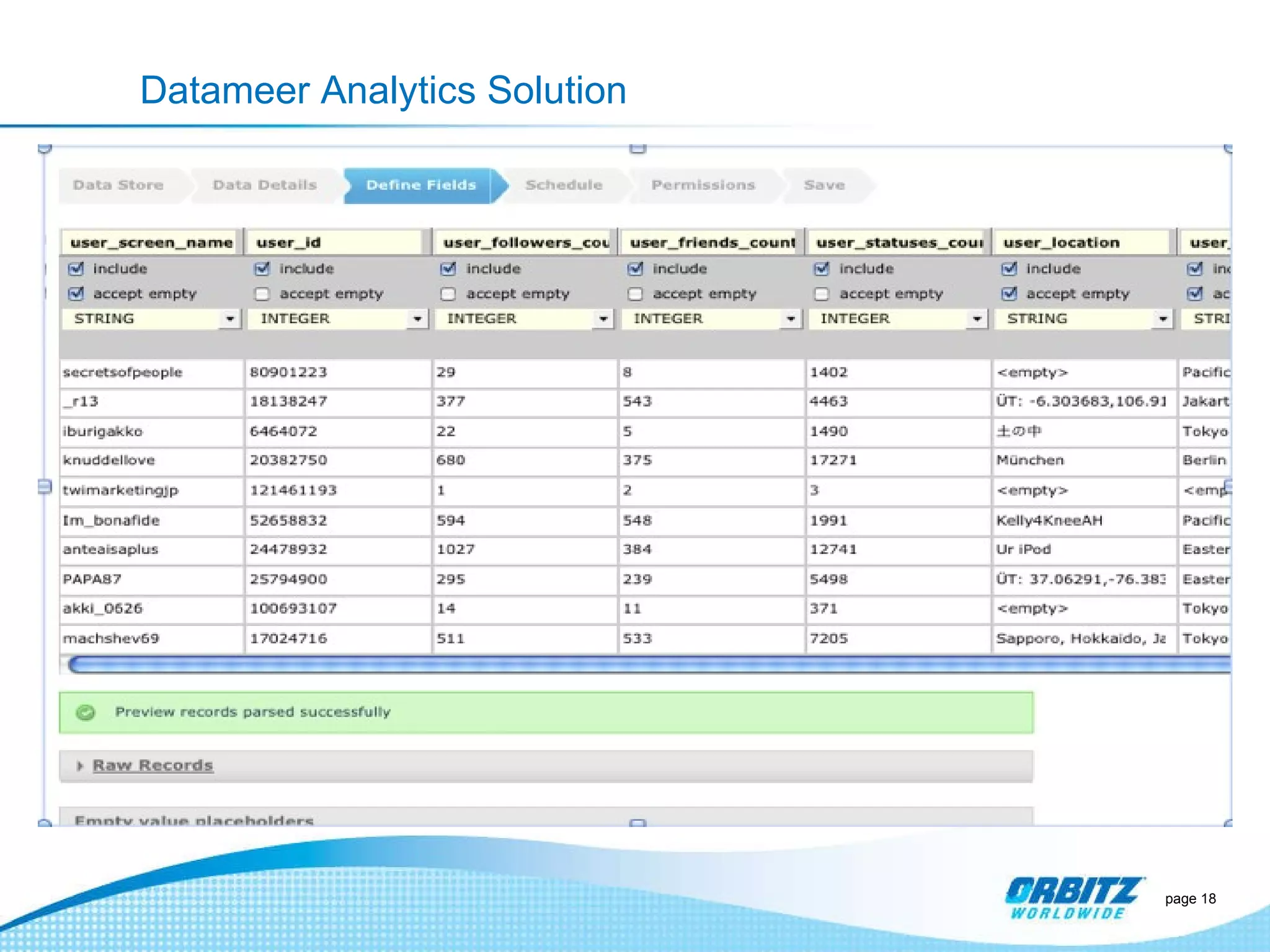
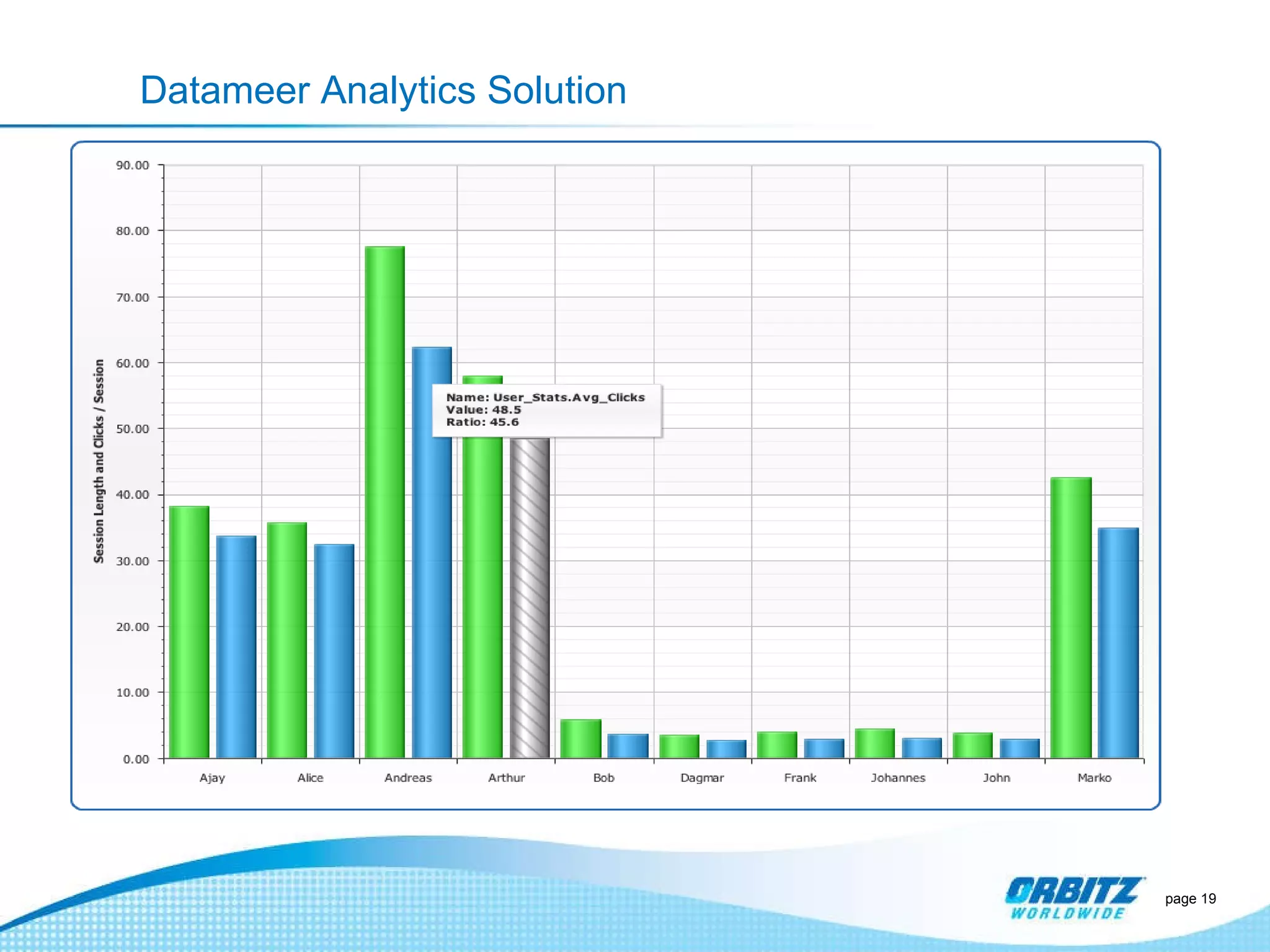


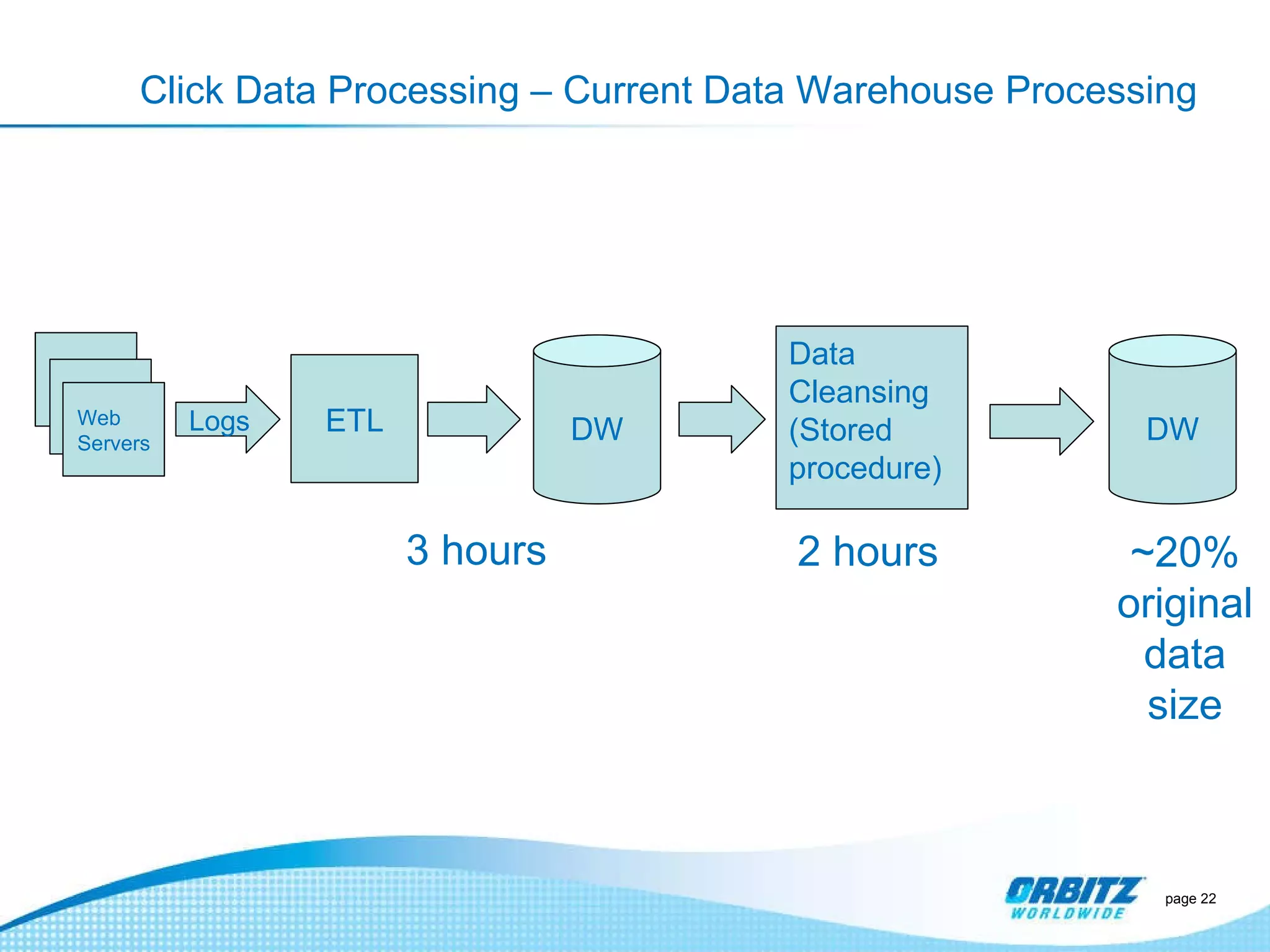
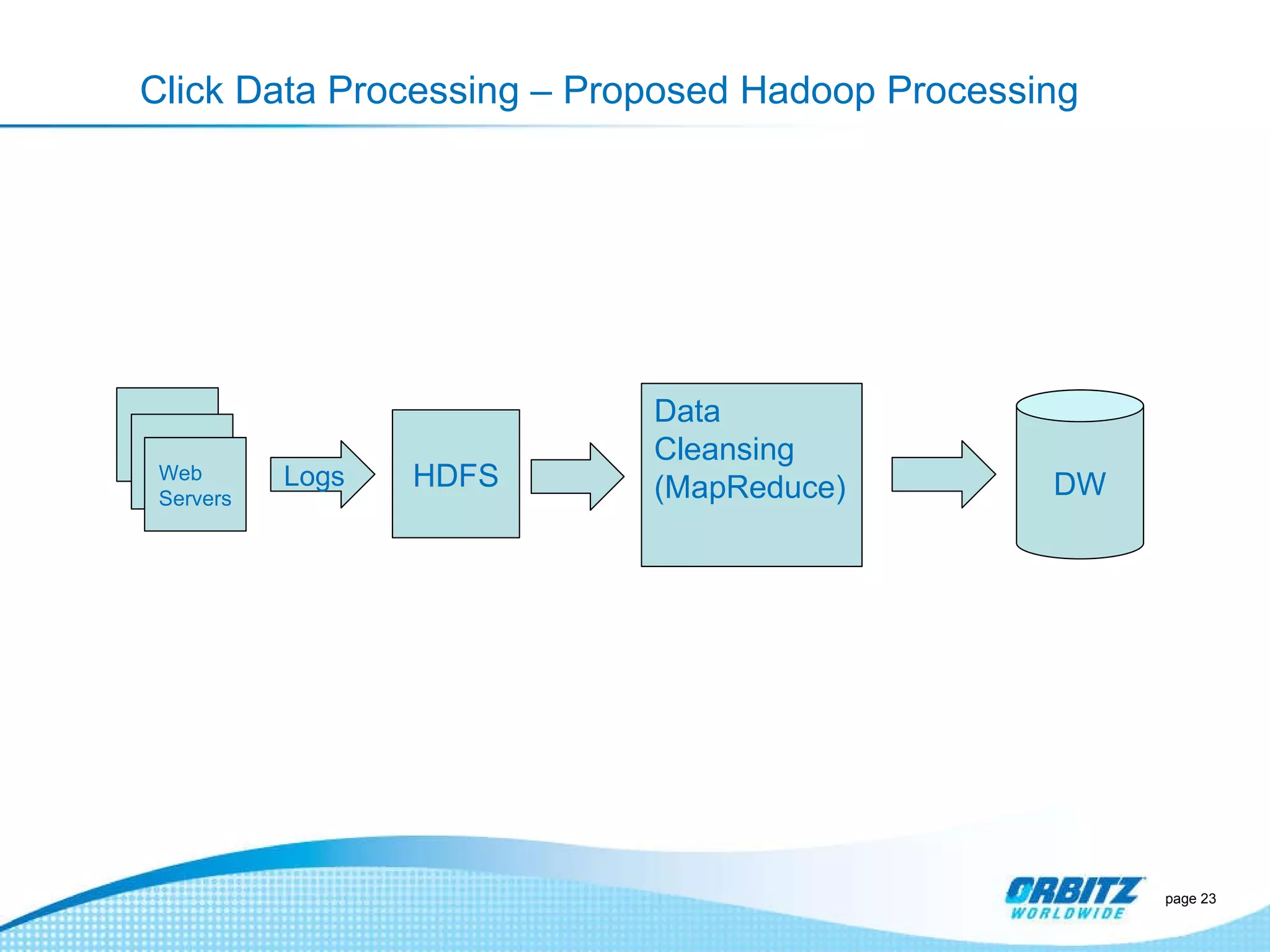










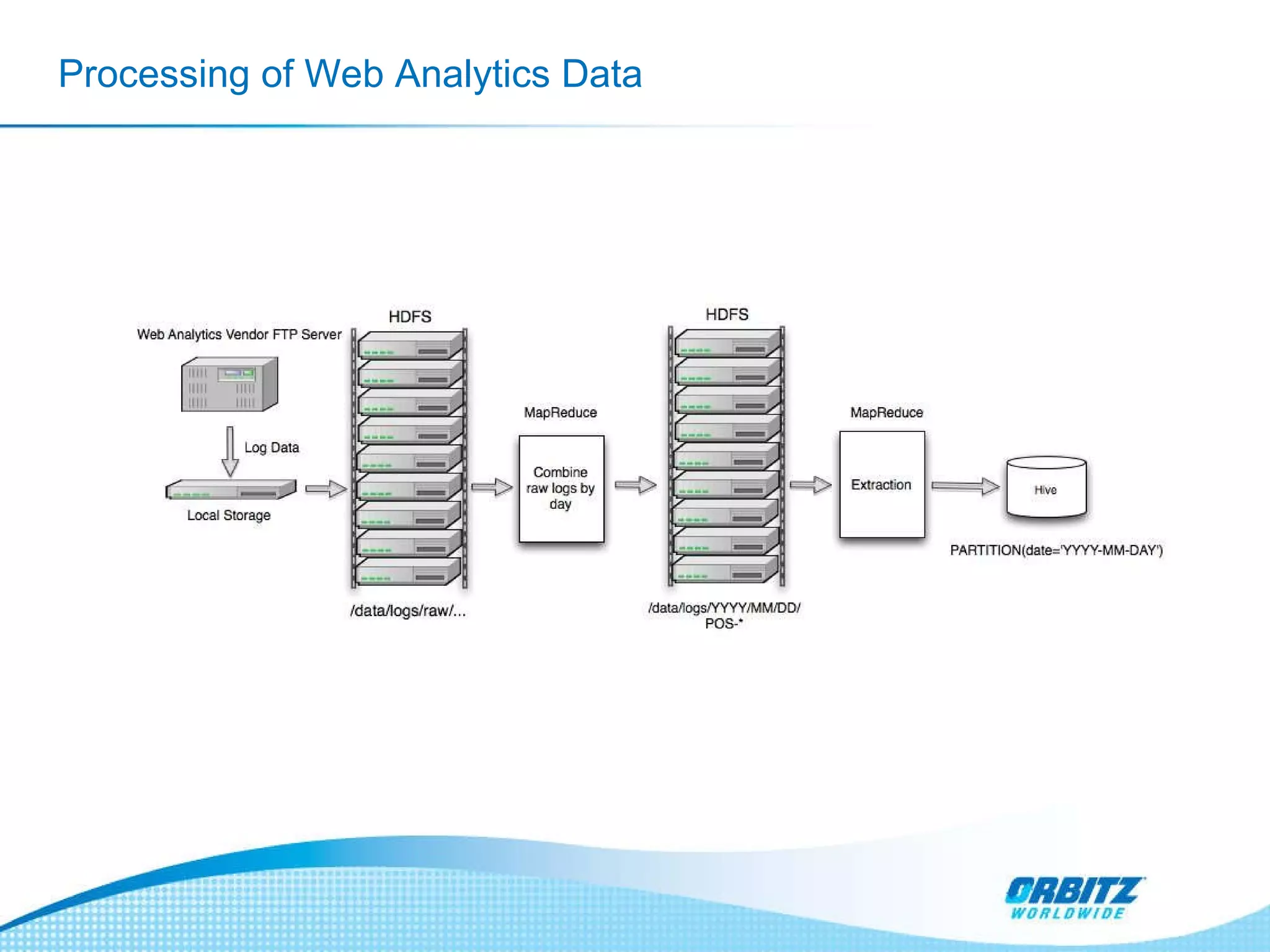
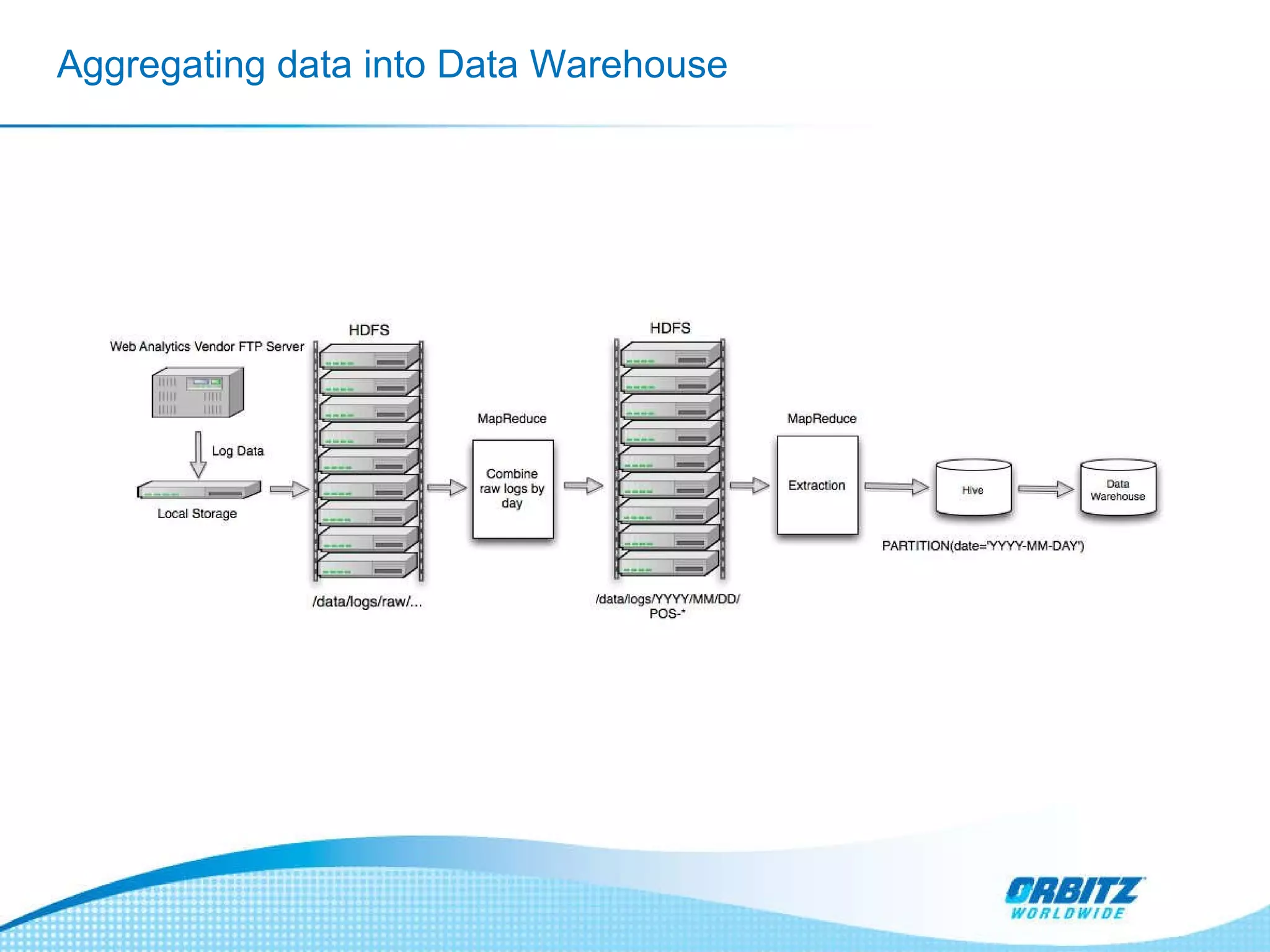






The document discusses how Orbitz Worldwide integrated Hadoop into its enterprise data infrastructure to handle large volumes of web analytics and transactional data. Some key points: - Orbitz used Hadoop to store and analyze large amounts of web log and behavioral data to improve services like hotel search. This allowed analyzing more data than their previous 2-week data archive. - They faced initial resistance but built a Hadoop cluster with 200TB of storage to enable machine learning and analytics applications. - The challenges now are providing analytics tools for non-technical users and further integrating Hadoop with their existing data warehouse.



























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)















