Download as PDF, PPTX






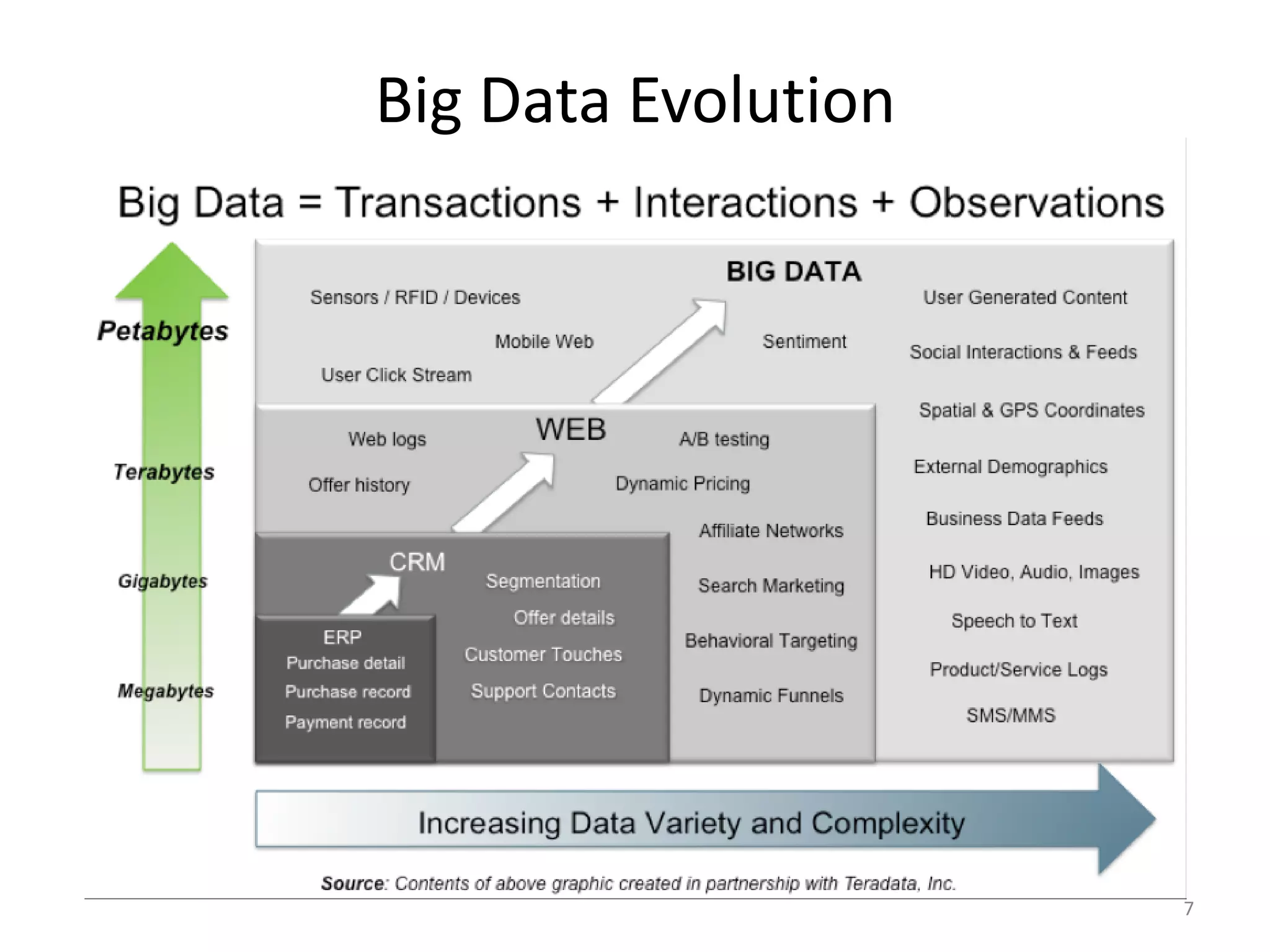







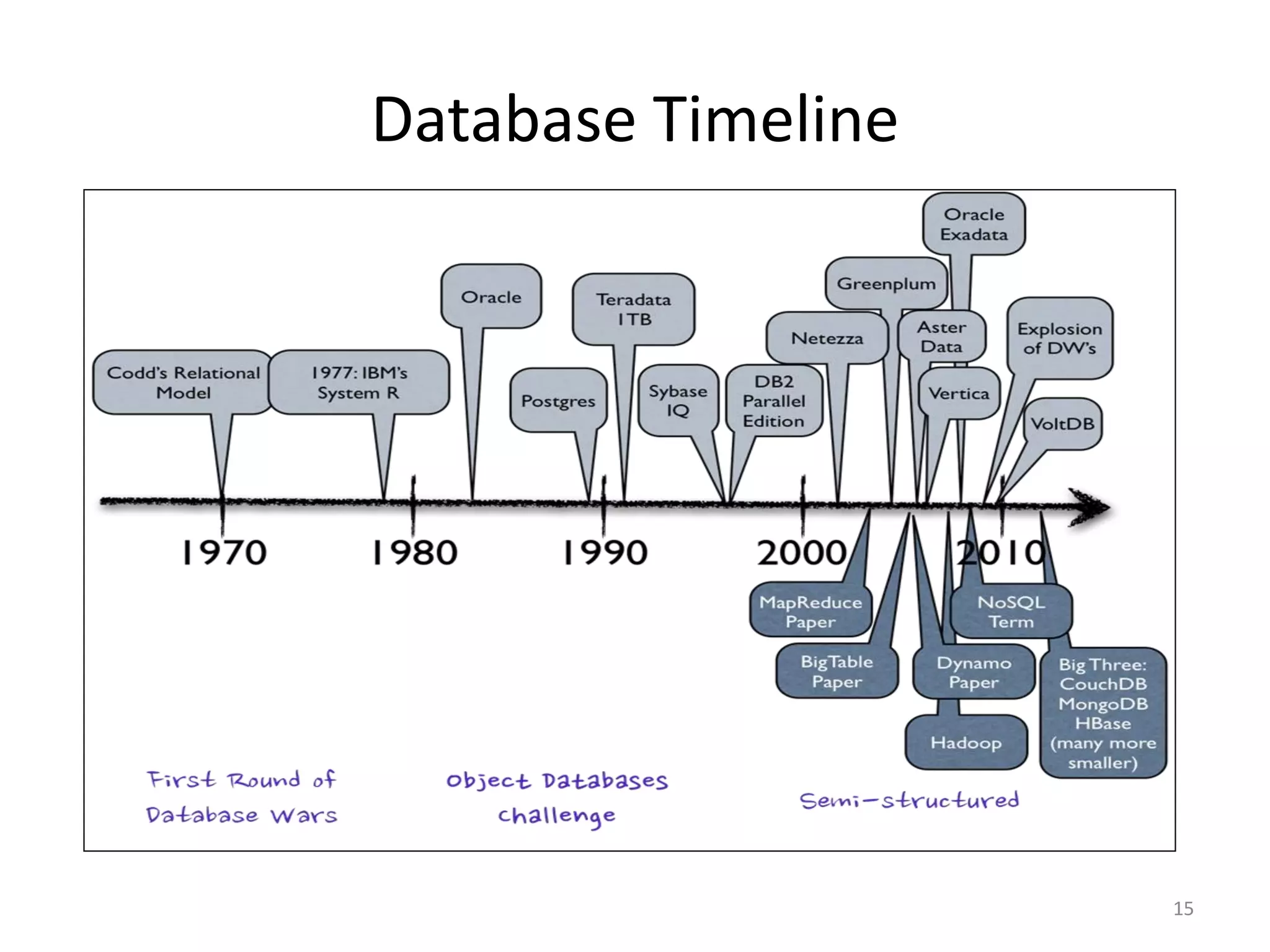








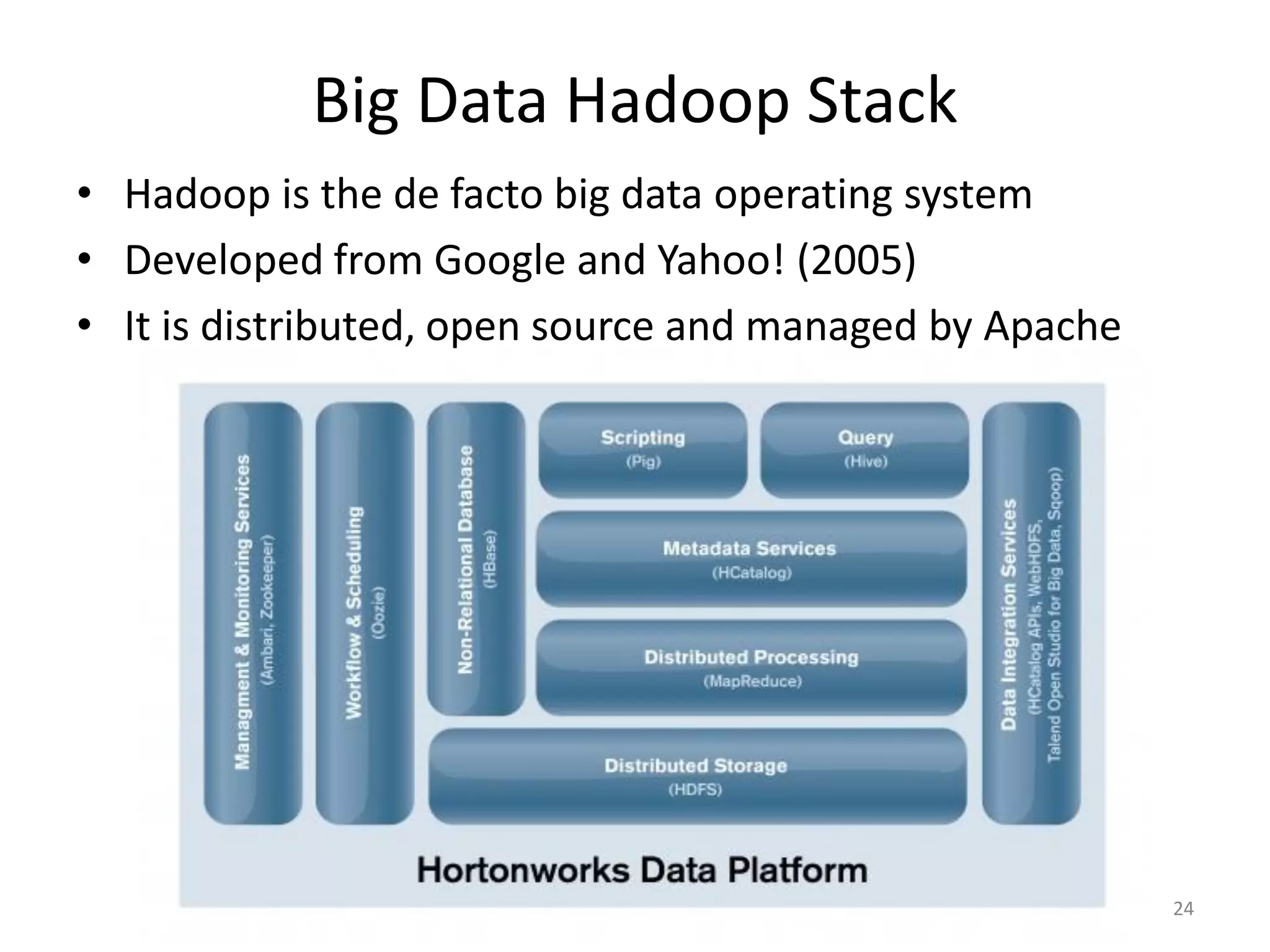





This document provides an overview of big data, including its definition, sources, databases, and analytics. It defines big data as large datasets greater than terabytes in size that are increasingly being collected from various sources such as science, social media, government and more. It notes that most data is unstructured. It also discusses the evolution of databases from relational SQL databases to non-relational NoSQL databases and Hadoop. Finally, it outlines the major tools and technologies used for big data analytics, including MapReduce, Hadoop, and machine learning.






























![Big_Data_ppt[1] (1).pptx](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatappt11-230720100552-10b674be-thumbnail.jpg?width=640&height=640&fit=bounds)











































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)





