Downloaded 10 times









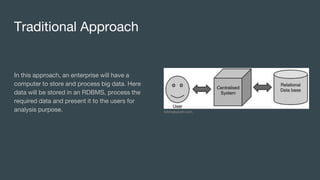




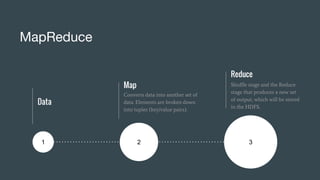


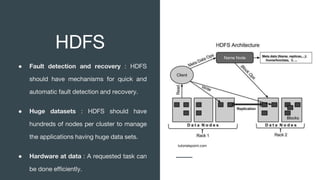





This document discusses big data, where it comes from, and how it is processed and analyzed. It notes that everything we do online now leaves a digital trace as data. This "big data" includes huge volumes of structured, semi-structured, and unstructured data from various sources like social media, sensors, and the internet of things. Traditional computing cannot handle such large datasets, so technologies like MapReduce, Hadoop, HDFS, and NoSQL databases were developed to distribute the work across clusters of machines and process the data in parallel.

















































































