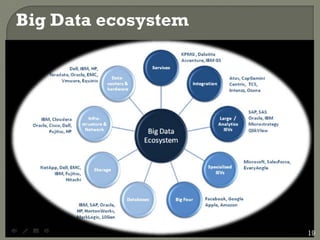
1. Big data refers to large and complex datasets that are difficult to process using traditional database and software techniques.
2. Hadoop is an open-source software platform that allows distributed processing of large datasets across clusters of computers. It solves the problems of big data by dividing it across nodes and processing it in parallel using MapReduce.
3. Hadoop provides reliable and scalable storage of big data using HDFS and efficient parallel processing of that data using MapReduce, allowing organizations to gain insights from large and diverse datasets.