Downloaded 28 times




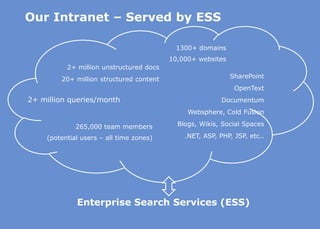
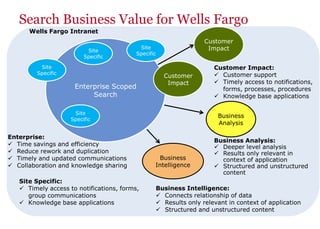
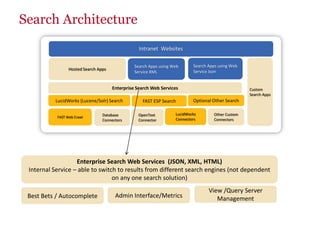
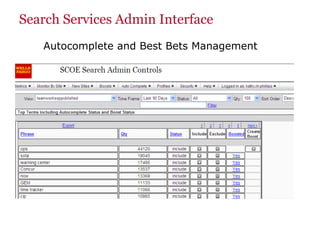
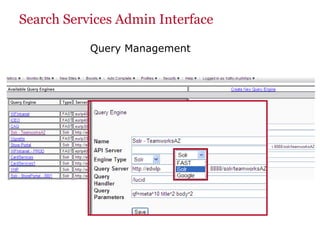
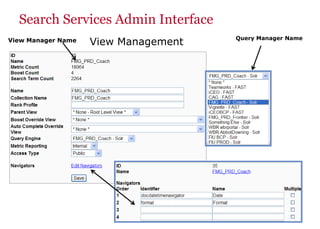
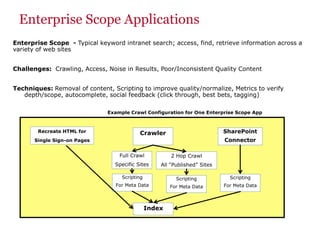

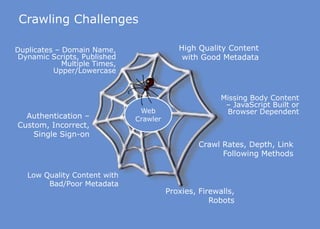
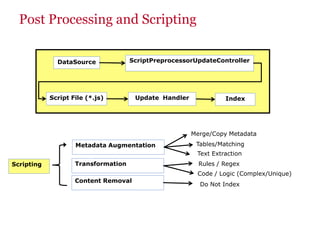
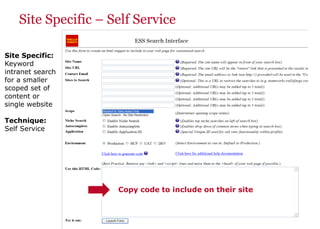
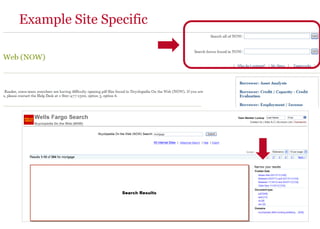
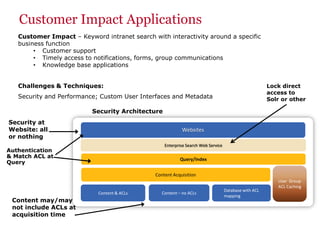
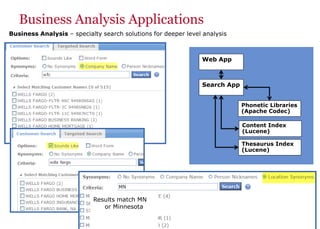
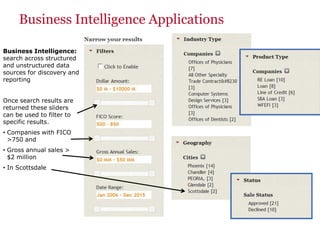





The document discusses the business value added by enterprise search services at Wells Fargo, detailing their intranet's search architecture and various applications. It highlights the challenges of content crawling and metadata management, while showcasing the benefits of search solutions in terms of efficiency and customer support. Future directions include integrating social feedback and enhancing data analysis to improve search relevance and personalization.


































































































