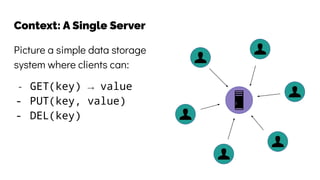
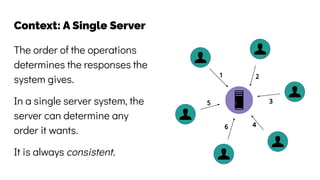
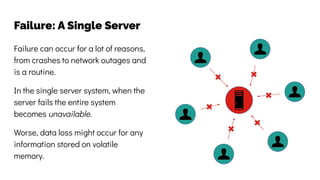
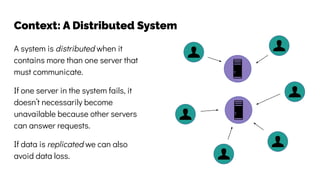
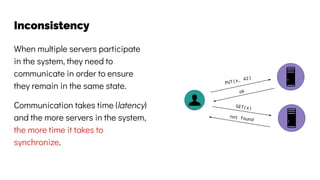
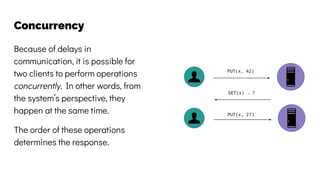
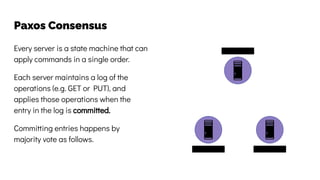
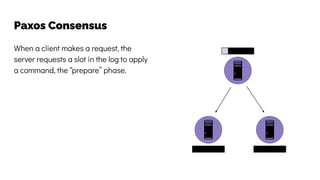
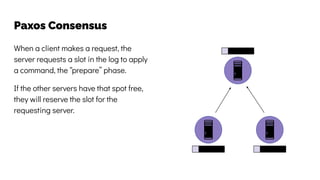
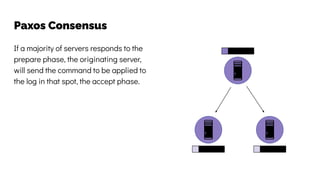
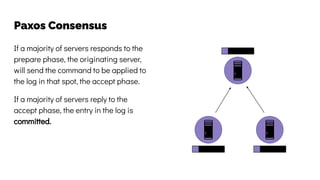
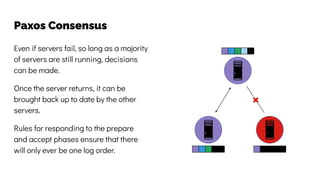
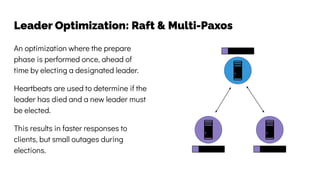
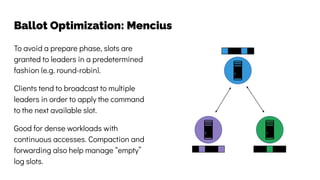
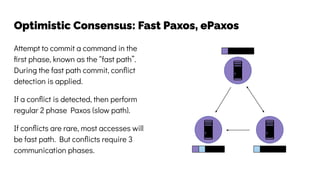
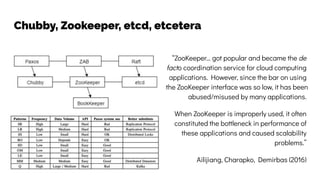
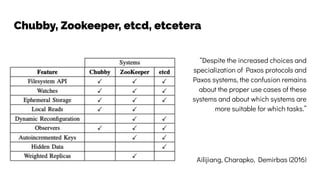
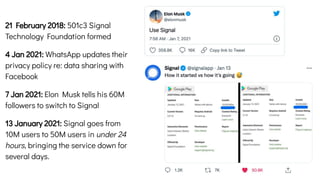
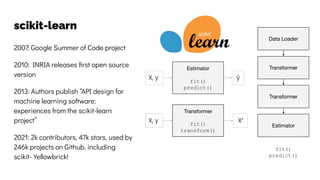
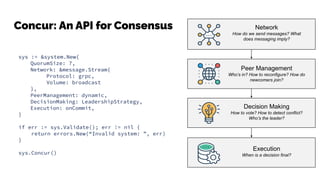
The document discusses the challenges and solutions related to data consistency in distributed systems. It highlights the importance of strong consistency for certain applications while detailing different consistency levels like eventual and causal consistency. Additionally, it addresses the complexities of scaling consensus and navigating data compliance in a global context.