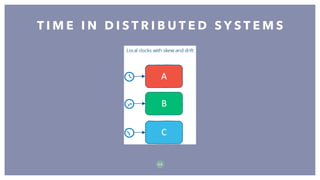
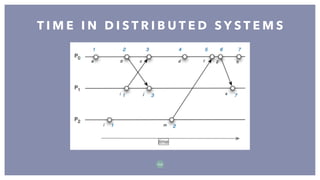
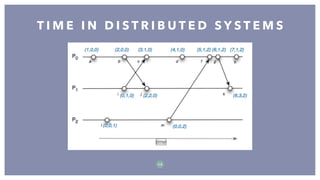
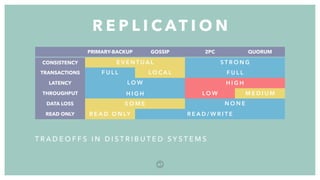
The document discusses distributed systems, defining them as collections of independent computers that function as a single coherent system. It highlights key challenges such as scalability, fault tolerance, and common fallacies associated with distributed computing, such as assuming network reliability and infinite bandwidth. The document further explores concepts like partitioning, replication, consistency models, and communication methods within distributed systems.