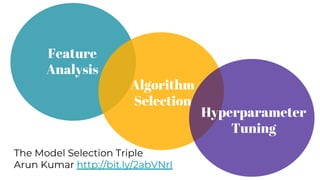
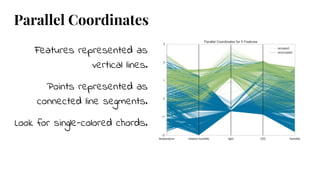
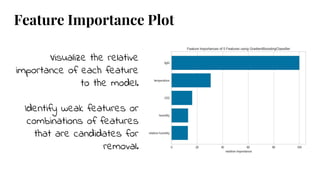
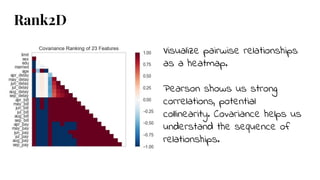
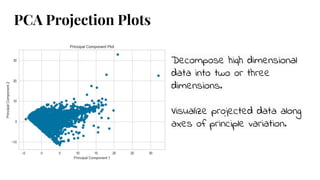
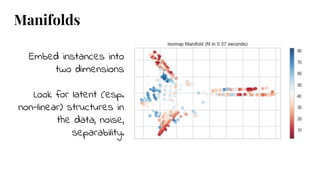
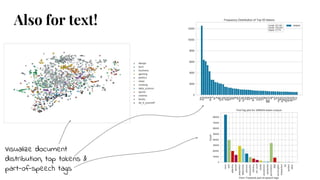
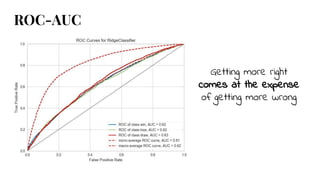
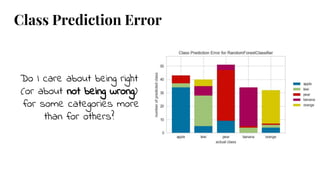
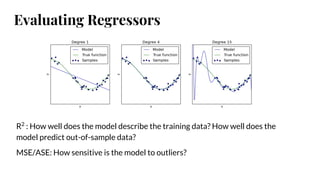
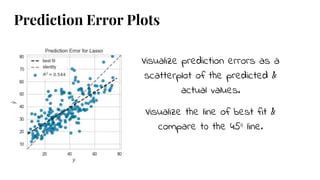
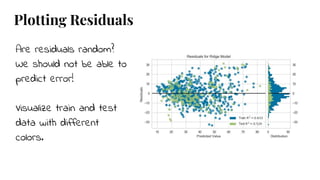
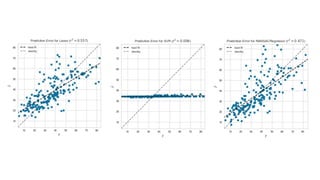
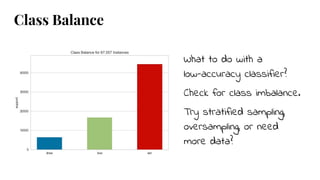
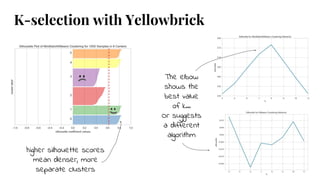
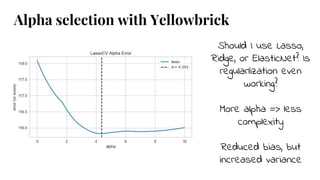
The document discusses model selection in machine learning, emphasizing the importance of feature analysis, algorithm selection, and hyperparameter tuning. Key techniques for evaluation include precision, recall, and F1 score for classifiers, as well as R² and MSE for regressors. Additionally, it introduces the Yellowbrick library for visual diagnostics in data science, providing tools for various analytical tasks.




































































![STOCK PRICE PREDICTION USING MACHINE LEARNING [RANDOM FOREST REGRESSION MODEL]](https://cdn.slidesharecdn.com/ss_thumbnails/irjet-v10i7108-230815114054-b07e3795-thumbnail.jpg?width=640&height=640&fit=bounds)










































