Download as PDF, PPTX














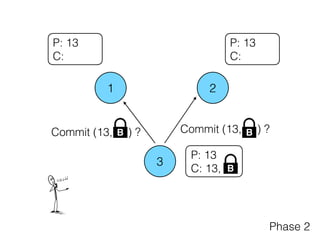
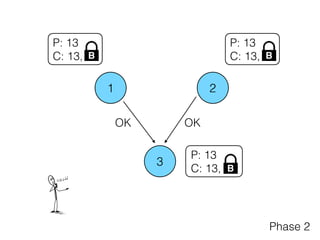
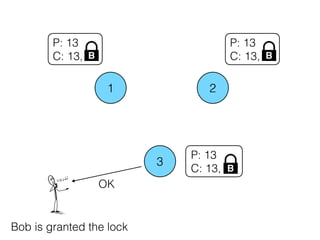

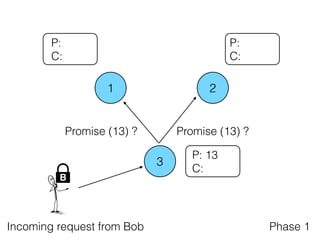
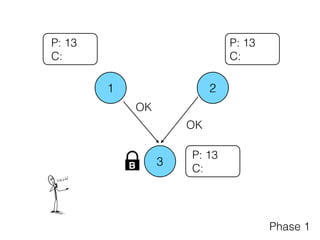
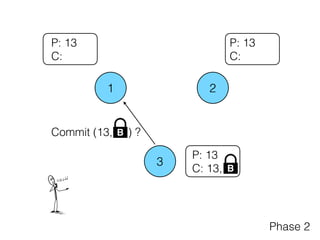
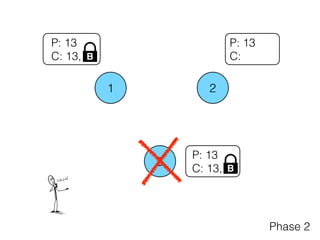
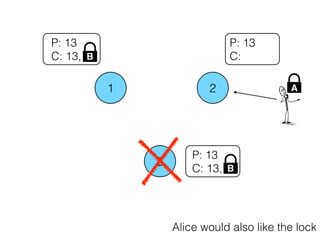
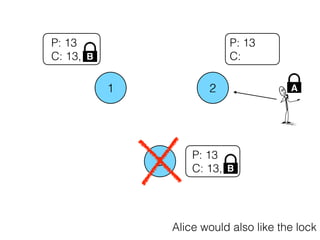
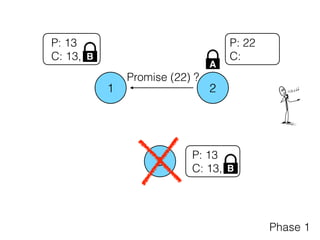
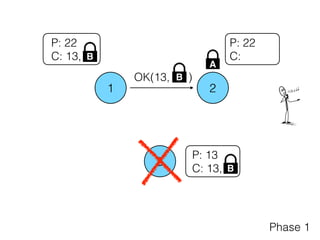
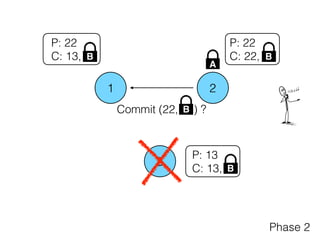
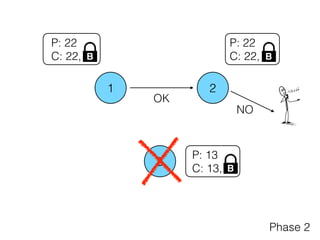

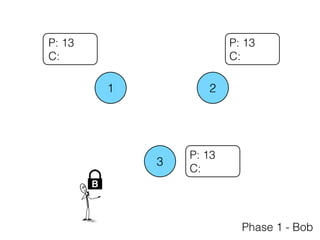
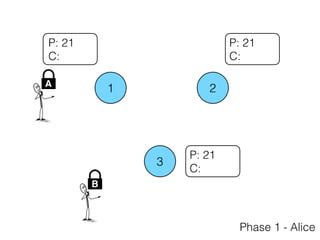
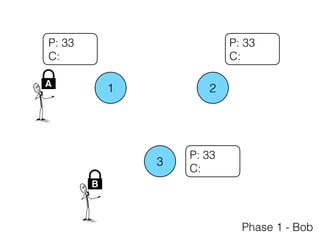
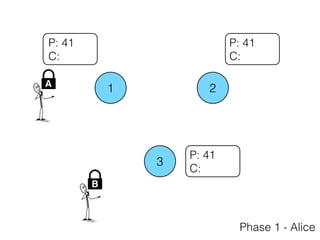




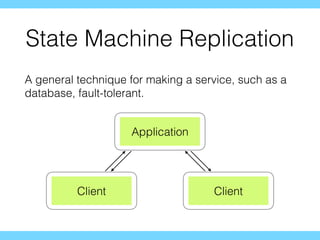

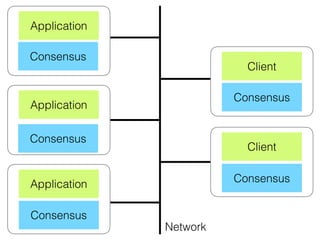


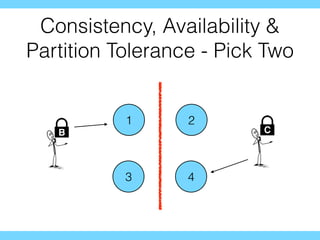











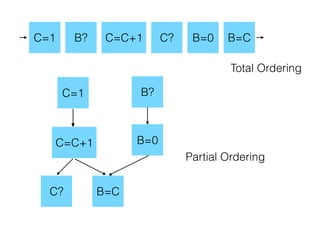
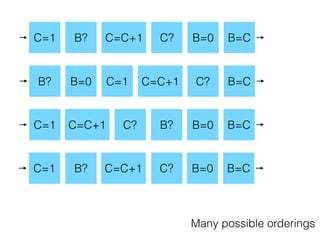



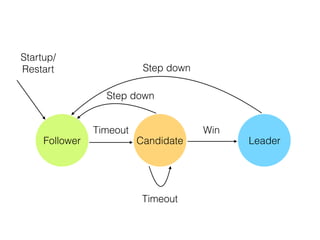










The document discusses the evolution of distributed consensus mechanisms over three decades, covering foundational theories such as the FLP impossibility result and various algorithms, including Paxos and Raft. It emphasizes the importance of achieving consensus in unreliable systems while balancing factors such as consistency, availability, and partition tolerance, encapsulated in the CAP theorem. Additionally, it highlights practical implementations and variations of consensus algorithms, stressing the importance of selecting the right algorithm for specific applications.





























































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)





