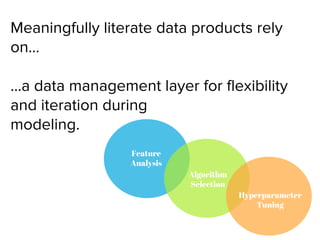
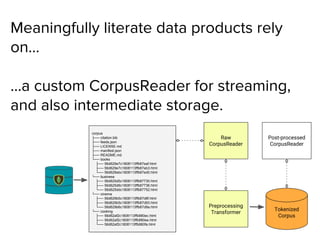
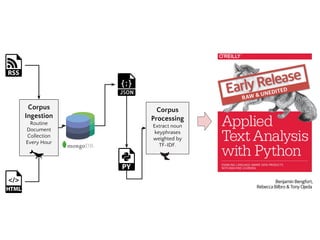
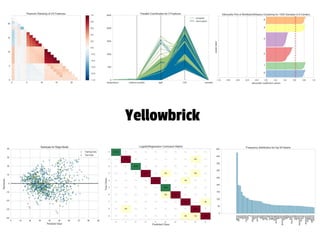
The document presents an overview of building a custom gigaword corpus for NLP, detailing the motivations, ingestion, management, and processing challenges encountered. It discusses tools and techniques used, such as the Natural Language Toolkit and Gensim for text analysis, and highlights lessons learned during the project. The author emphasizes the importance of a tailored data management layer and feature analysis for effective NLP modeling.







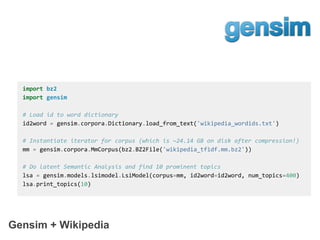
![The Natural Language Toolkit
import nltk
moby = nltk.text.Text(nltk.corpus.gutenberg.words('melville-moby_dick.txt'))
print(moby.similar("ahab"))
print(moby.common_contexts(["ahab", "starbuck"]))
print(moby.concordance("monstrous", 55, lines=10))](https://image.slidesharecdn.com/buildingagigawordcorpuspycon2017updated-170521143011/85/Building-a-Gigaword-Corpus-PyCon-2017-8-320.jpg)

![RSS
import os
import requests
import feedparser
feed = "http://feeds.washingtonpost.com/rss/national"
for entry in feedparser.parse(feed)['entries']:
r = requests.get(entry['link'])
path = entry['title'].lower().replace(" ", "-") + ".html"
with open(path, 'wb') as f:
f.write(r.content)](https://image.slidesharecdn.com/buildingagigawordcorpuspycon2017updated-170521143011/85/Building-a-Gigaword-Corpus-PyCon-2017-11-320.jpg)

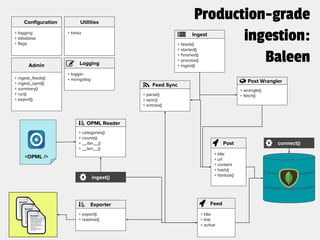

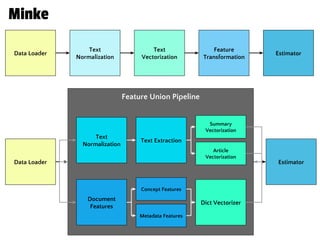
![From each doc, extract html, identify paras/sents/words, tag with part-of-speech
Raw Corpus
HTML
corpus = [(‘How’, ’WRB’),
(‘long’, ‘RB’),
(‘will’, ‘MD’),
(‘this’, ‘DT’),
(‘go’, ‘VB’),
(‘on’, ‘IN’),
(‘?’, ‘.’),
...
]
Paras
Sents
Tokens
Tags](https://image.slidesharecdn.com/buildingagigawordcorpuspycon2017updated-170521143011/85/Building-a-Gigaword-Corpus-PyCon-2017-16-320.jpg)