Downloaded 37 times
















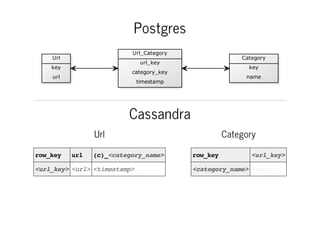








The document outlines a four-step process for migrating from PostgreSQL to Cassandra, targeting efficient data handling of terabytes of internet categorization data. It discusses the challenges of managing a PostgreSQL schema and contrasts it with Cassandra's easier management, scalability, and suitability for NoSQL databases. The migration involves running both databases in parallel, with a detailed strategy for data transfer and validation to ensure the integrity of the migration process.
















































































