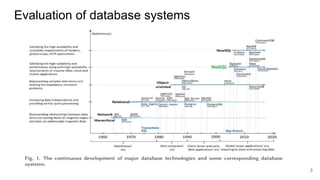
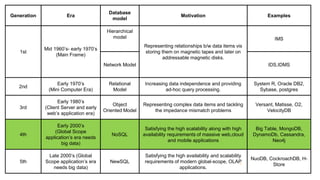
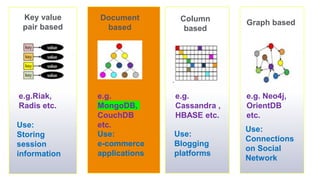
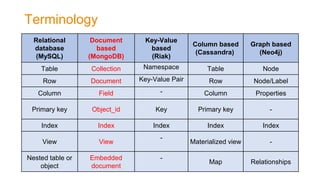
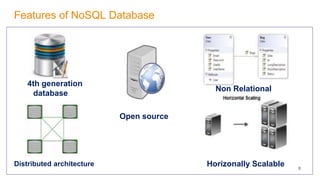
The document discusses document-oriented databases and MongoDB. It provides an overview of MongoDB, including that it is an open-source, document-based database that stores data in JSON-like documents with dynamic schemas. It supports common operations like CRUD and indexing to query and modify data efficiently. Some key features are that MongoDB is horizontally scalable, uses dynamic schemas, and is suitable for large, unstructured data like that needed in applications with big data requirements.












![Sample Database (“Studentinfo”)
{
"_id" : ObjectId("61f6f4e0dd0c8af093eb9255"),
"studentName" : "Gaurav",
"section" : "A",
"Marks" : 90,
"subject" : [
"English"
]
}
{
"_id" : ObjectId("61f6f4e0dd0c8af093eb9254"),
"studentName" : "Vijay",
"section" : "A",
"Marks" : 70,
"subject" : [
"Hindi",
"English",
"Math"
]
}
Collection
(“Student”)
Document 1
Document 2
19
.
.
.
.
Document n
Fields
Fields
Primary
key
Primary
key
Embedded/Nested
documents](https://image.slidesharecdn.com/copyofmongodb-230228063250-674c062c/85/Copy-of-MongoDB-pptx-18-320.jpg)


![1. create()
Basic Syntax: db.createCollection(name, options)
Query: Create a new collection “student”
Syntax: db.createCollection(“student”);
2. insert(): The insert() method is used to insert one or multiple documents in a
collection.
Basic Syntax: db.collection_Name.insert(JSON document)
Query: Insert the marks of a students named ‘Vijay, Gaurav’ in section ‘A’ having
subjects ‘Hindi, English, Math’,and ‘English’ respectively.
Syntax: db.student.insert ({studentName: “Vijay”, section: “A”, Marks: 70, subject:
[“Hindi”, “English”, “Math”]})
db.student.insert[{studentName: “Gaurav”, section: “A”, Marks: 90, subject:
[“English”]}])
22](https://image.slidesharecdn.com/copyofmongodb-230228063250-674c062c/85/Copy-of-MongoDB-pptx-21-320.jpg)
![2. insertOne(): Another way to insert documents is by using the insertOne()
method for a single document in a collection.
Basic Syntax: db.collection_Name.insertone(JSON document)
Query: Insert the marks of a student named ‘Vijay’ in section ‘A’ having subjects
‘Hindi, English, Math’.
Syntax: db.student.insert ({studentName: “Vijay”, section: “A”, Marks: 70, subject:
[“Hindi”, “English”, “Math”]})
3. insertMany(): is used for inserting multiple documents:
Basic Syntax: db.collection_Name.insertmany([array of JSON document])
Query: Insert the marks of a students named ‘Vijay, Gaurav’ in section ‘A’ having
subjects ‘Hindi, English, Math’,and ‘English’ respectively.
Syntax: db.student.insertMany( [ { studentName: “Vijay”, section: “A”, Marks: 70,
subject: [“Hindi”, “English”, “Math”]}, { studentName: “Gaurav”, section: “A”,
Marks: 90, subject: [“English”]}]);
23](https://image.slidesharecdn.com/copyofmongodb-230228063250-674c062c/85/Copy-of-MongoDB-pptx-22-320.jpg)



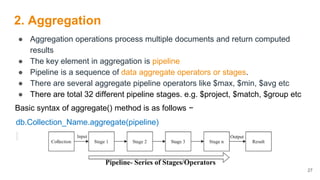


![Examples
Following are the three popular stages in aggregation framework:
1) $match − This is a filtering operation and thus this can reduce the amount of
documents that are given as input to the next stage.
Basic Syntax: { $match: { <query> } }
Query 1: Display the details of students belong to section “A”
Syntax: db.student.aggregate([{“$match:{“section”: “A”}}])
Query 2: Display the details of students belong to section “A” and marks greater
than 80
db.student.aggregate([{“$match”: { $and:[{“section”: “A”}, {Marks:
{“$gt”: 80}}]}}])
30](https://image.slidesharecdn.com/copyofmongodb-230228063250-674c062c/85/Copy-of-MongoDB-pptx-29-320.jpg)
![31
2) $project − Used to select some specific fields from a collection.
Basic Syntax:
Query 1: Display name, section and marks of all the students.
Syntax: db.student.aggregate([{“$project”: {studentName: 1, section: 1,
Marks: 1}}])
Query 2: Display the names and marks of students from section A.
Syntax: db.student.aggregate([{$match:{“section”: “A”}}, {“$project”:
{studentName: 1, Marks:1}}])
{ $project: { <specification(s)> } }](https://image.slidesharecdn.com/copyofmongodb-230228063250-674c062c/85/Copy-of-MongoDB-pptx-30-320.jpg)
![3) $group − This does the actual aggregation as discussed above.
Basic Syntax:
{ $group: { _id: <expression>, // Group By Expression <field1>: { <accumulator1> :
<expression1> },}}
Query 1: To find out total marks each section.
Syntax: db.student.aggregate([{“$group”:{“_id”: {“section : “$section”}, “Total
Marks”:{“$sum”: “$Marks”}}}])
Query 2: To find the total marks of section A.
Syntax: db.student.aggregate([{“$match”: {section: ‘A’}}, {“$group”:{“_id”: {“section :
“$section”}, “Total Marks”:{“$sum”: “$Marks”}}}])
32](https://image.slidesharecdn.com/copyofmongodb-230228063250-674c062c/85/Copy-of-MongoDB-pptx-31-320.jpg)
![Query 3: To find total and average marks of each section.
Syntax: db.student.aggregate([{“$group”:{“_id”: {“section : “$section”}, “Total
Marks”:{“$sum”: “$Marks”}, “Count”:{ “$sum”:1}, “Average”: {“$avg”: “$Marks”}}}])
33](https://image.slidesharecdn.com/copyofmongodb-230228063250-674c062c/85/Copy-of-MongoDB-pptx-32-320.jpg)











































![nosql [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/nosqlautosaved-230721181148-0ee7f758-thumbnail.jpg?width=640&height=640&fit=bounds)























![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)






![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)







