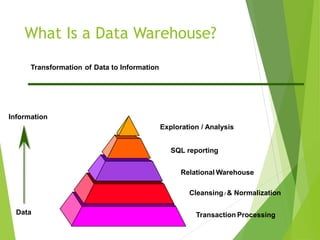
The document discusses various applications of data warehousing. It begins by describing problems with traditional transactional systems and how data warehouses address these issues. It then defines key components of a data warehouse including the extraction, transformation, and loading of data from various sources. The document outlines how online analytical processing (OLAP) tools, metadata repositories, and data mining techniques analyze and explore the collected data. Finally, it weighs the benefits of a data warehouse against the costs of implementation and maintenance.