Downloaded 305 times








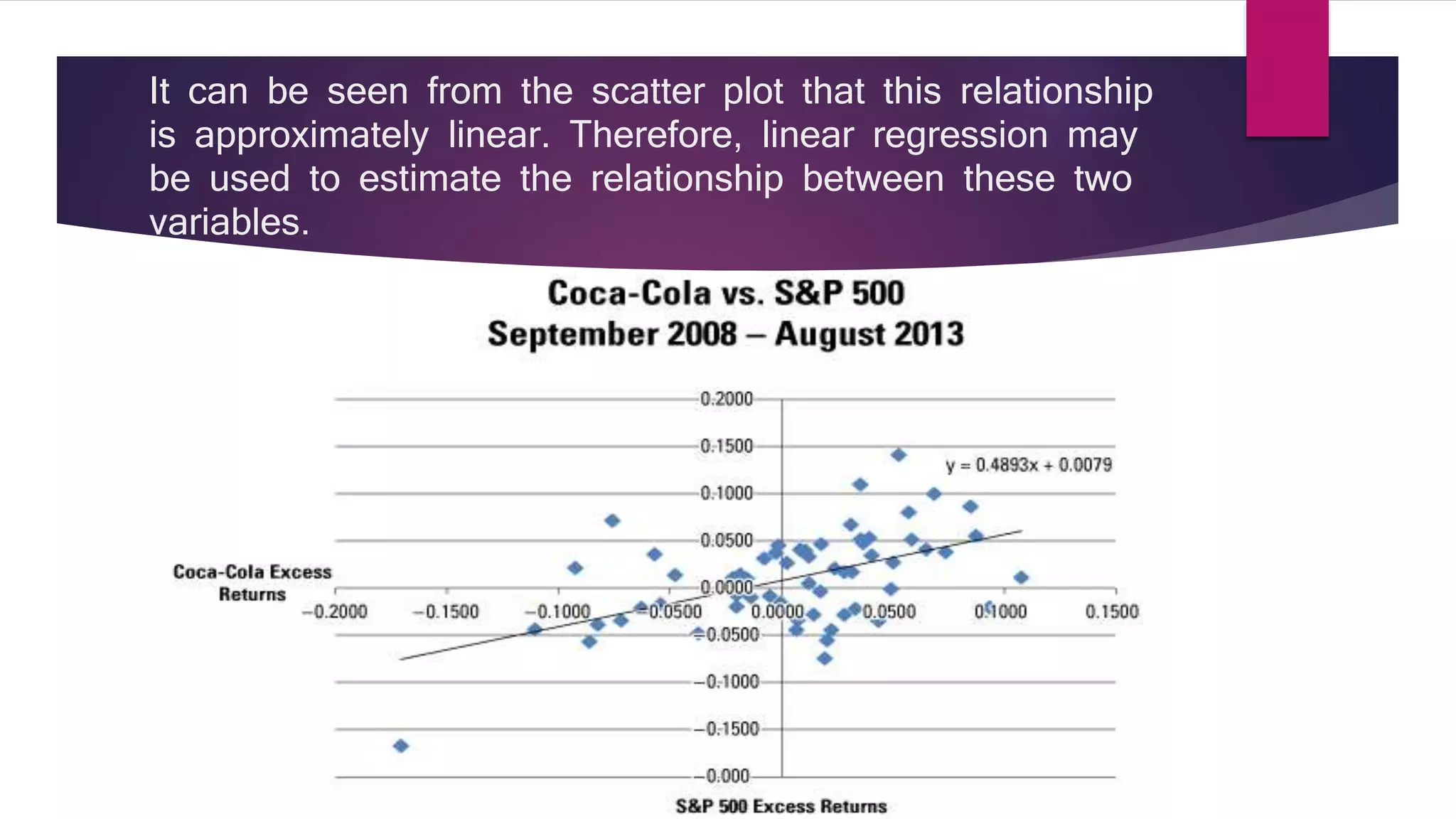















This document provides a summary of regression analysis in 9 steps: 1) Specify dependent and independent variables, 2) Check for linearity with scatter plots, 3) Transform variables if nonlinear, 4) Estimate the regression model, 5) Test the model fit with R2, 6) Perform a joint hypothesis test of the coefficients, 7) Test individual coefficients, 8) Check for violations of assumptions like autocorrelation and heteroscedasticity, 9) Interpret the intercept and slope coefficients. Regression analysis is used to determine relationships between variables and estimate how changes in independents impact dependents.


































































![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)
