Downloaded 49 times











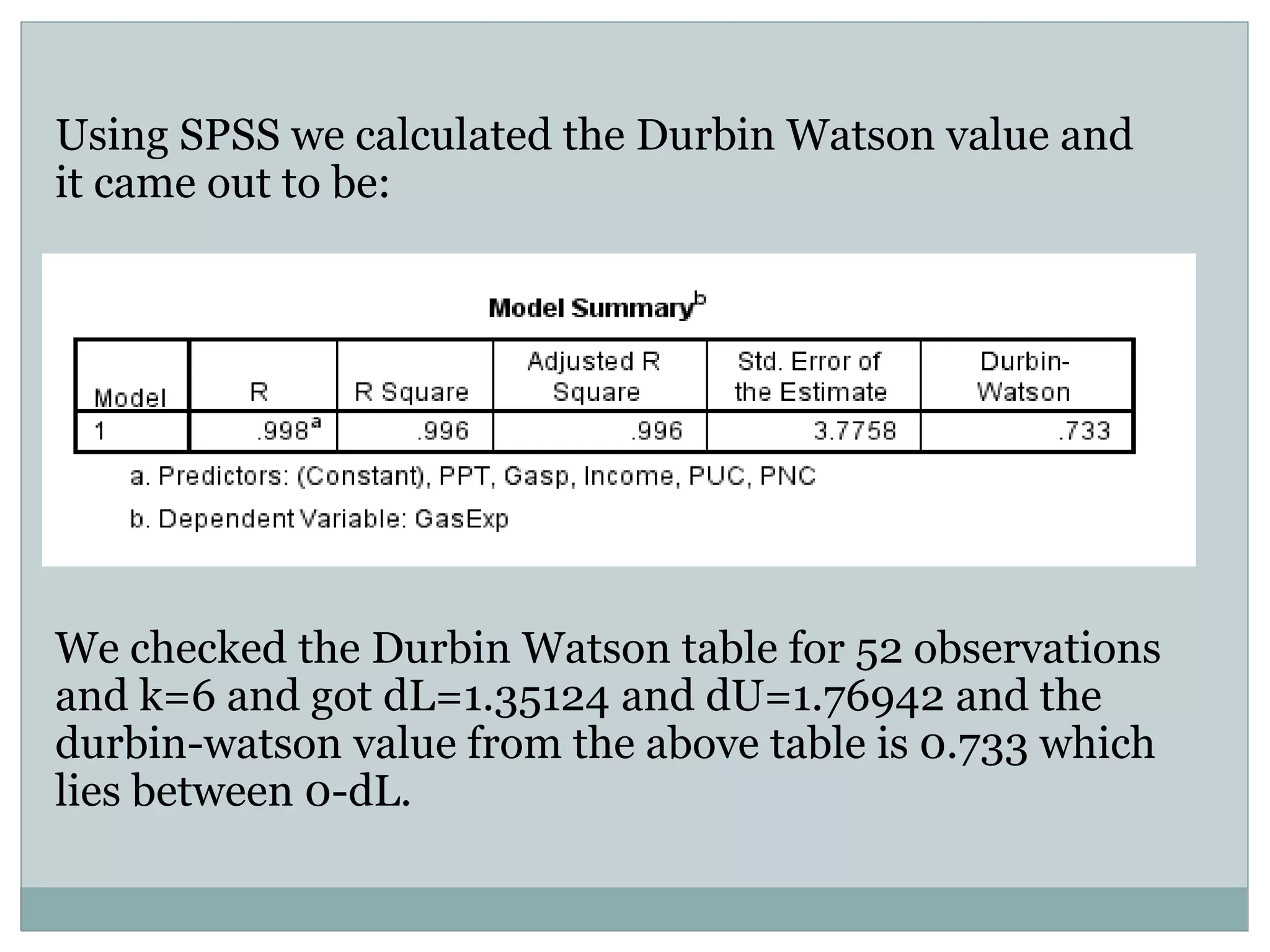
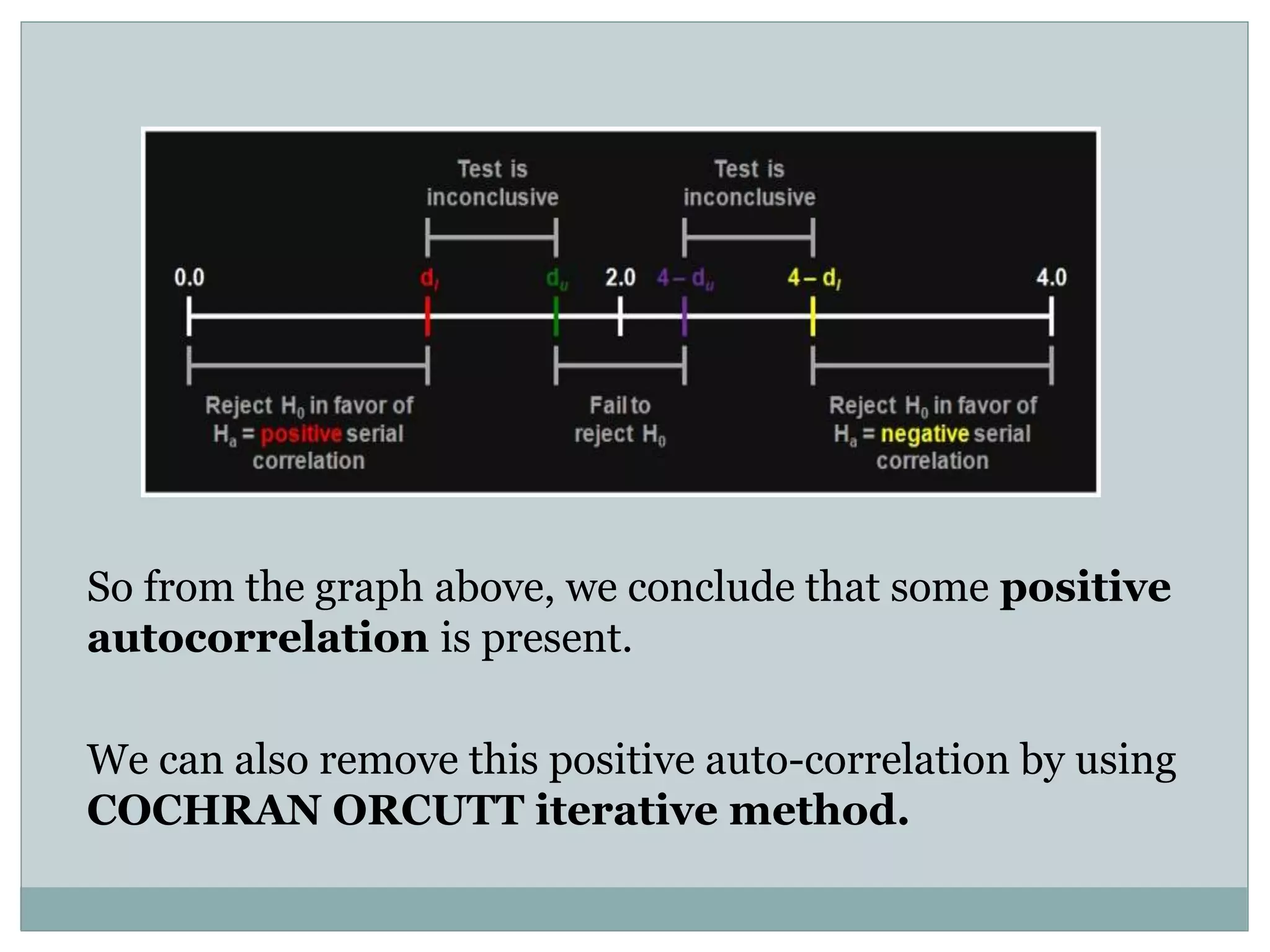
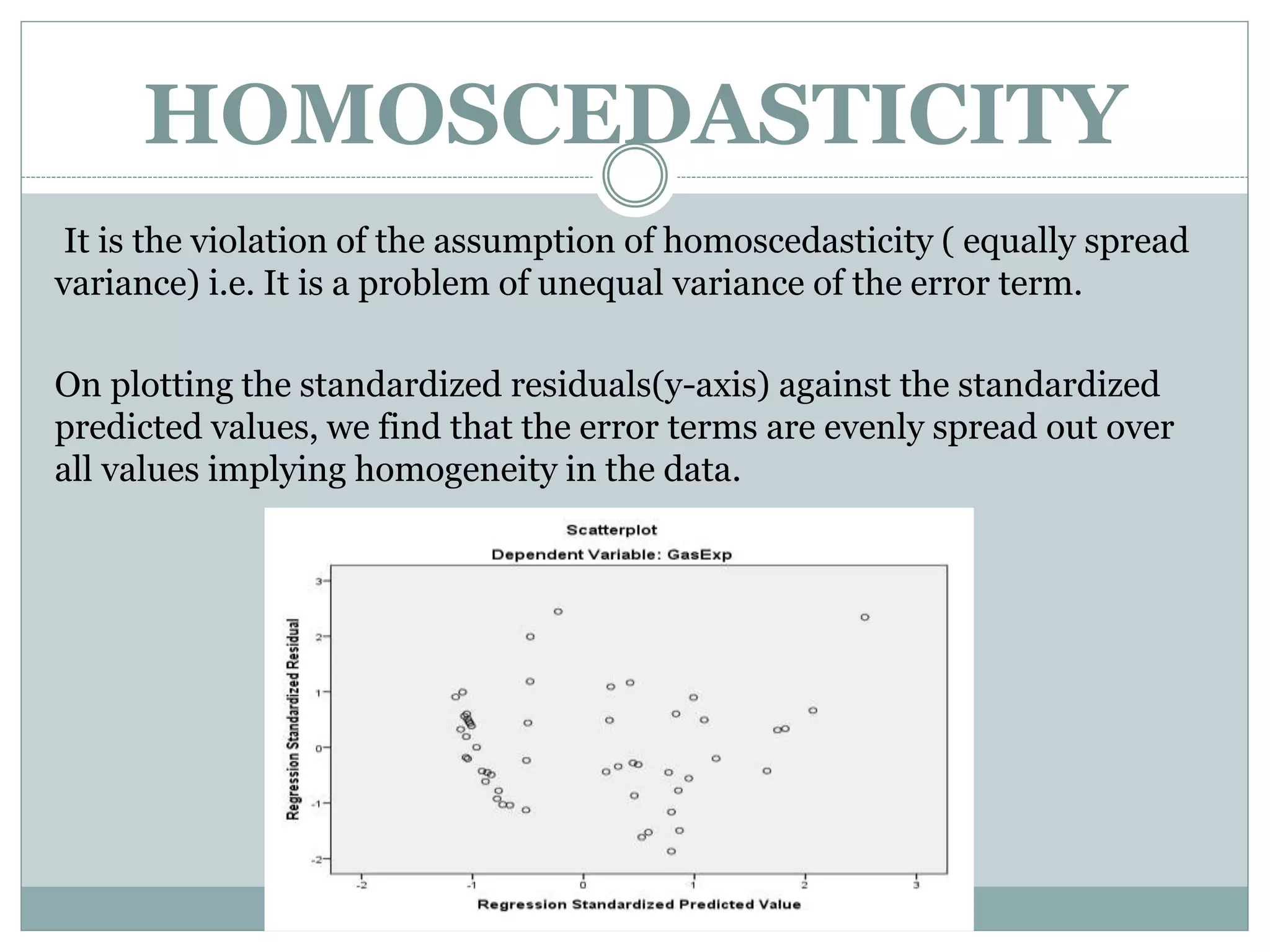
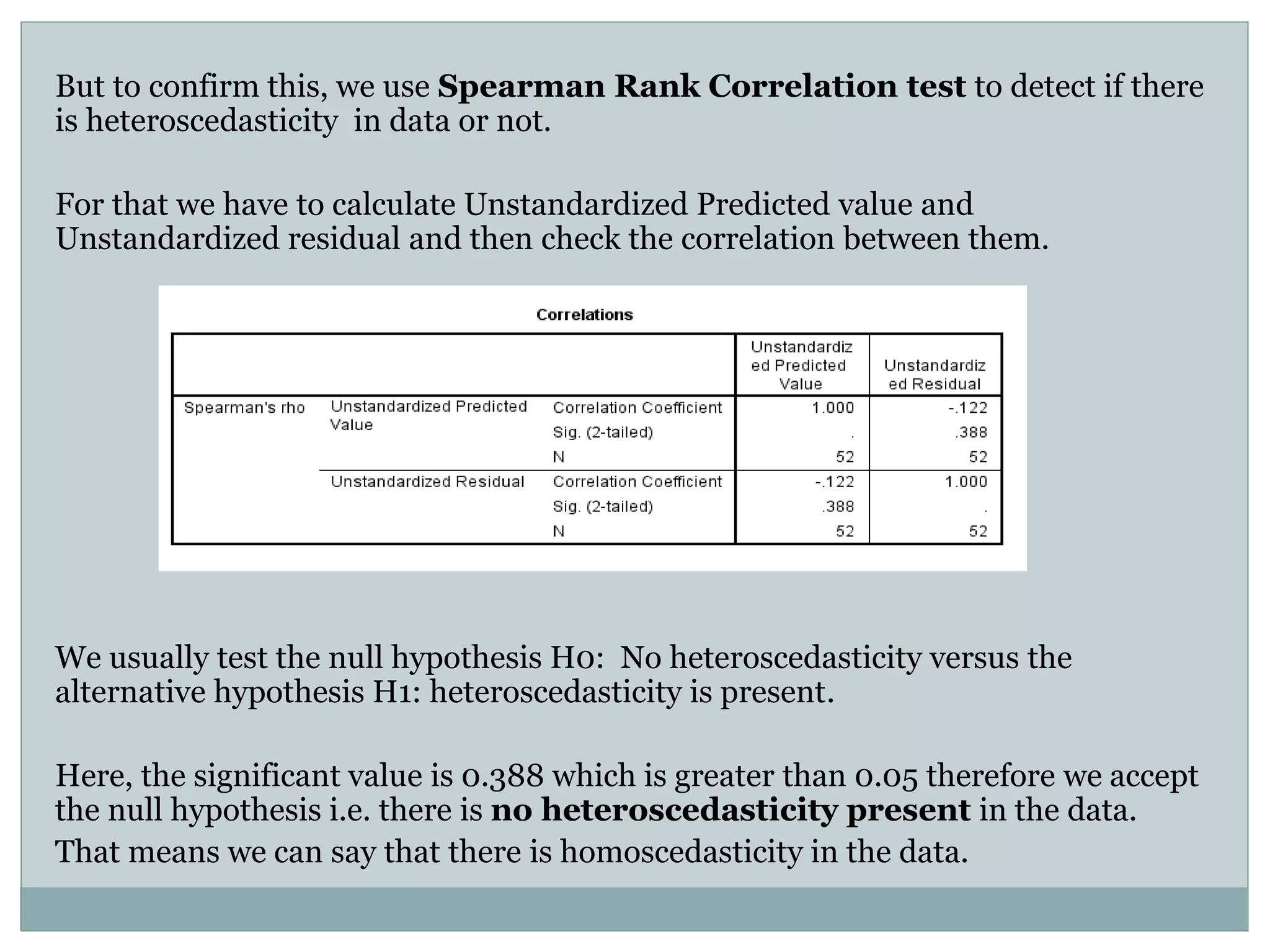

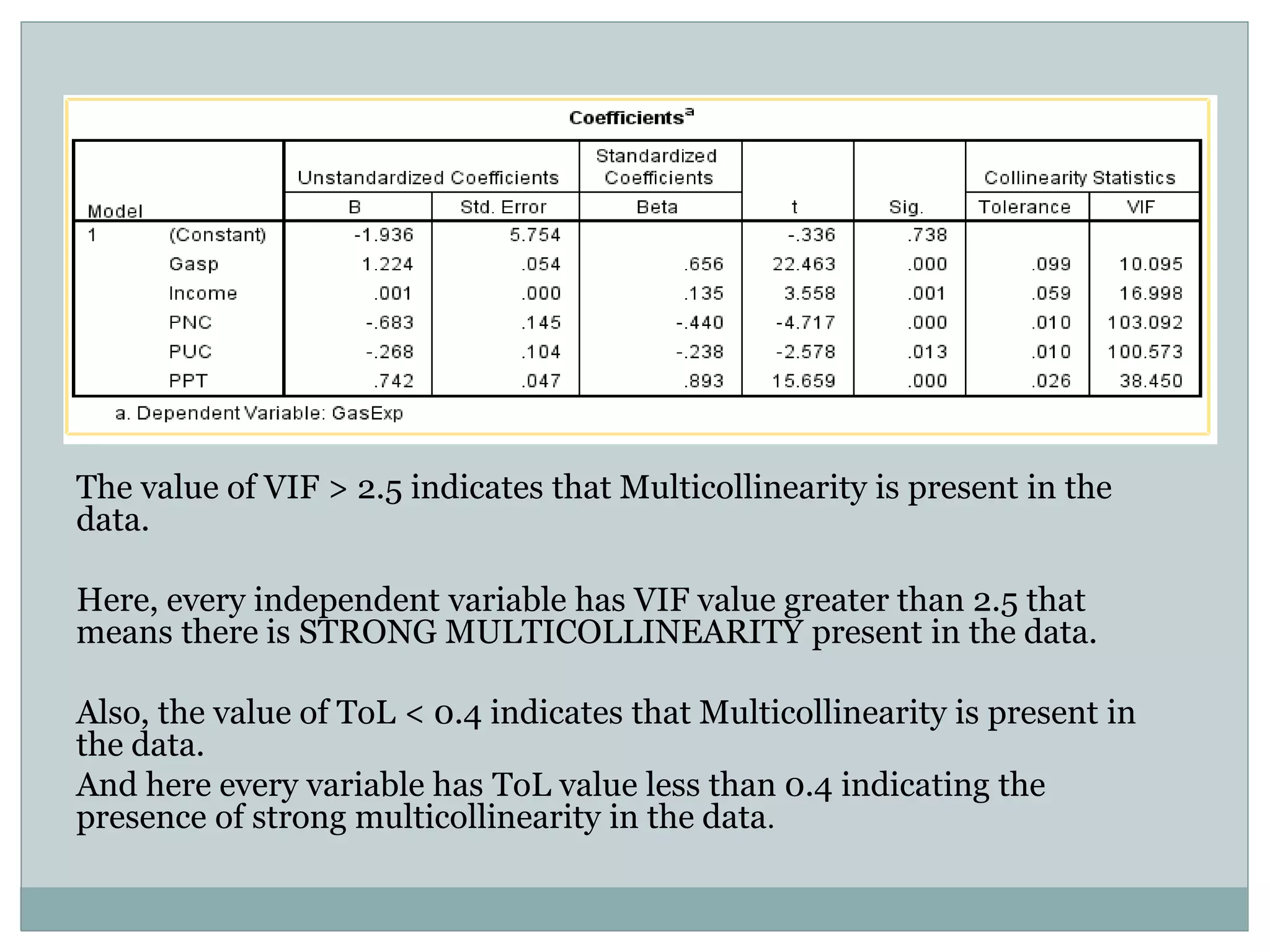





The project analyzes the relationship between U.S. gasoline expenditure and various economic factors from 1953 to 2004 using multiple linear regression. The regression model shows a strong fit, with 99.6% of the variation in gasoline expenditure explained by the independent variables, although it identifies strong multicollinearity among predictors and some positive autocorrelation. Despite these issues, the overall model remains statistically significant, indicating important relationships between the factors studied.



































































