The document summarizes Pablo Duboue's presentation on the Apache UIMA framework for unstructured information processing. It includes an outline describing an introduction and tutorial on UIMA, a discussion of W3C corpus processing, advanced topics in UIMA, and a summary. Key points about UIMA are that it is an open source framework for integrating text analytics tools and it uses standoff annotations to allow interoperability between tools.




![Intro and Tutorial
W3C Corpus Processing UIMA
Advanced Topics Tutorial
Summary
Analytics Frameworks
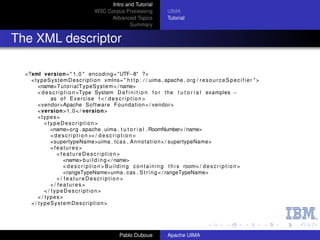
Find all telephone numbers in running text
(((([0-9]{3}))|[0-9]{3})-?
[0-9]{3}-?[0-9]{4}
Nice but...
How are you going to feed this further processing?
What about finding non-standard proper names in text?
Acquiring technology from external vendors, free software
projects, etc?
Pablo Duboue Apache UIMA](https://image.slidesharecdn.com/20100224uima-100312155748-phpapp01/85/UIMA-5-320.jpg)






![Intro and Tutorial
W3C Corpus Processing UIMA
Advanced Topics Tutorial
Summary
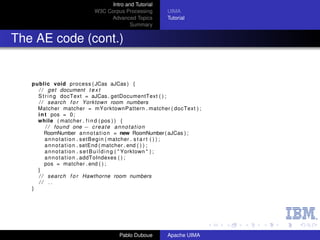
Room annotator
From the UIMA tutorial, write an Analysis Engine that
identifies room numbers in text.
Yorktown patterns: 20-001, 31-206, 04-123 (Regular
Expression Pattern: [0-9][0-9]-[0-2][0-9][0-9])
Hawthorne patterns: GN-K35, 1S-L07, 4N-B21 (Regular
Expression Pattern: [G1-4][NS]-[A-Z][0-9])
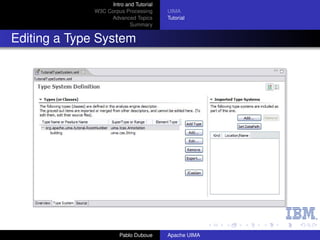
Steps:
1 Define the CAS types that the annotator will use.
2 Generate the Java classes for these types.
3 Write the actual annotator Java code.
4 Create the Analysis Engine descriptor.
5 Test the annotator.
Pablo Duboue Apache UIMA](https://image.slidesharecdn.com/20100224uima-100312155748-phpapp01/85/UIMA-14-320.jpg)
![Intro and Tutorial
W3C Corpus Processing UIMA
Advanced Topics Tutorial
Summary
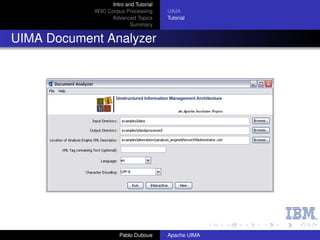
The AE code
package org . apache . uima . t u t o r i a l . ex1 ;
import j a v a . u t i l . regex . Matcher ;
import j a v a . u t i l . regex . P a t t e r n ;
import org . apache . uima . analysis_component . JCasAnnotator_ImplBase ;
import org . apache . uima . j c a s . JCas ;
import org . apache . uima . t u t o r i a l . RoomNumber ;
/∗∗
∗ Example a n n o t a t o r t h a t d e t e c t s room numbers u s i n g
∗ Java 1 . 4 r e g u l a r e x p r e s s i o n s .
∗/
public class RoomNumberAnnotator extends JCasAnnotator_ImplBase {
p r i v a t e P a t t e r n mYorktownPattern =
P a t t e r n . compile ( " b [ 0 − 4 ] d−[0 −2]d d b " ) ;
p r i v a t e P a t t e r n mHawthornePattern =
P a t t e r n . compile ( " b [ G1−4][NS] −[A ] d d b " ) ;
−Z
public void process ( JCas aJCas ) {
/ / next s l i d e
}
}
Pablo Duboue Apache UIMA](https://image.slidesharecdn.com/20100224uima-100312155748-phpapp01/85/UIMA-17-320.jpg)
































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)

























