Download as PDF, PPTX






























![University of Sheffield, NLP
Hands-on with Semantic Search
Try these queries on the BBC News demo:
http://services.gate.ac.uk/mimir/gpd/search/index
● Gordon Brown
● Gordon Brown said
●
Gordon Brown [0..3] root:say
●
{Person} [0..3] root:say
●
{Person.gender=female}[0..3] root:say
●
Make sure you type the queries EXACTLY or they probably won't
work!
●
Try making up some of your own queries.](https://image.slidesharecdn.com/text-analysis-with-gate-150424090133-conversion-gate02/75/GATE-a-text-analysis-tool-for-social-media-39-2048.jpg)
![University of Sheffield, NLP
Try your hand with some SPARQL
(for the more adventurous!)
●
{Person inst ="http://dbpedia.org/resource/Gordon_Brown"} [0..3]
root:say
●
{Person sparql="SELECT ?inst WHERE { ?inst a :Politician }"}
[0..3] root:say
●
{Person sparql = "SELECT ?inst WHERE { ?inst :party
<http://dbpedia.org/resource/Labour_Party_%28UK%29> }" }
[0..3] root:say
●
{Person sparql = "SELECT ?inst WHERE {
?inst :party <http://dbpedia.org/resource/Labour_Party_%28UK
%29> .
?inst :almaMater
<http://dbpedia.org/resource/University_of_Edinburgh> }"
} [0..3] root:say
Can you work out what these do?](https://image.slidesharecdn.com/text-analysis-with-gate-150424090133-conversion-gate02/75/GATE-a-text-analysis-tool-for-social-media-40-2048.jpg)

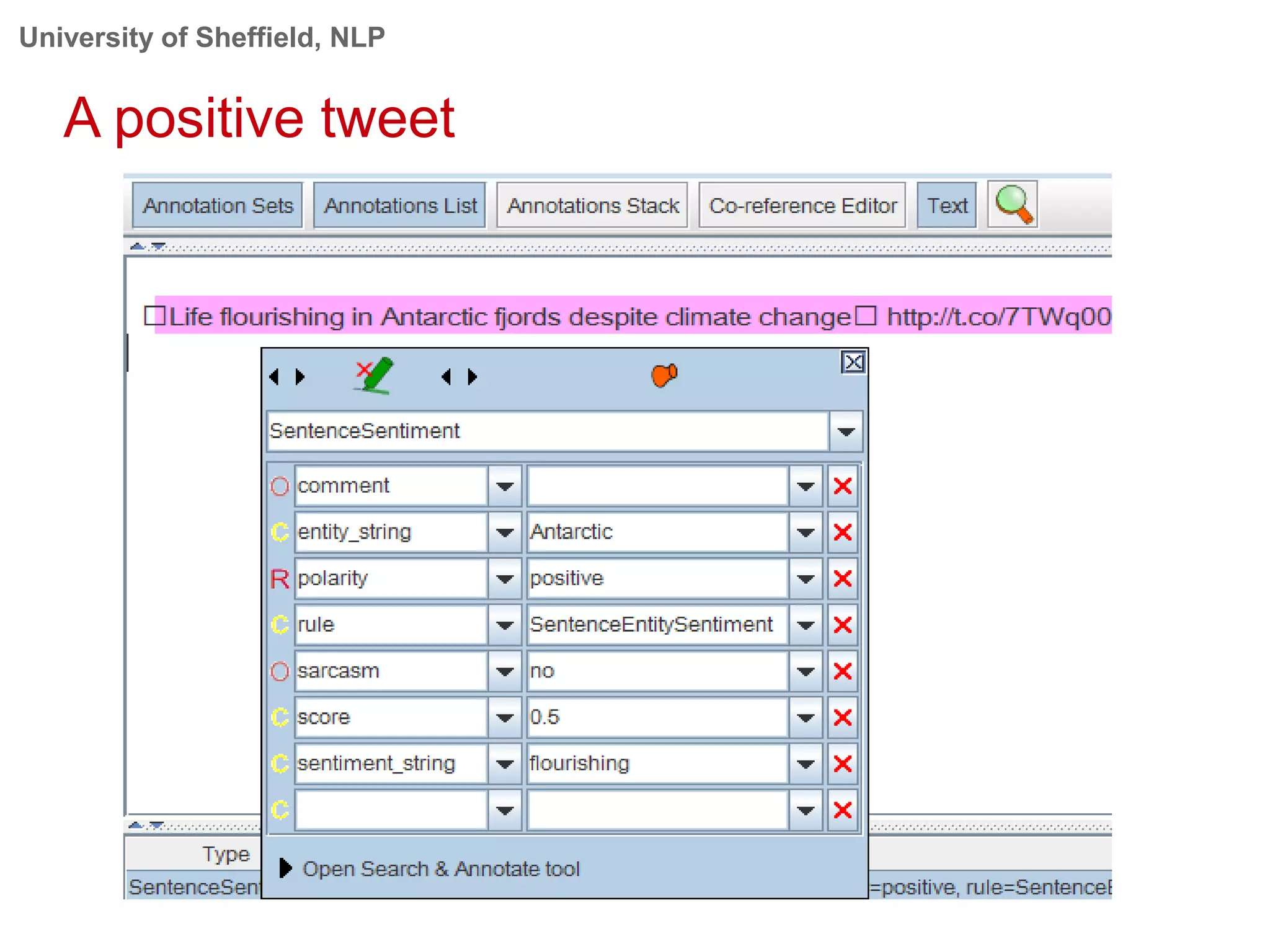
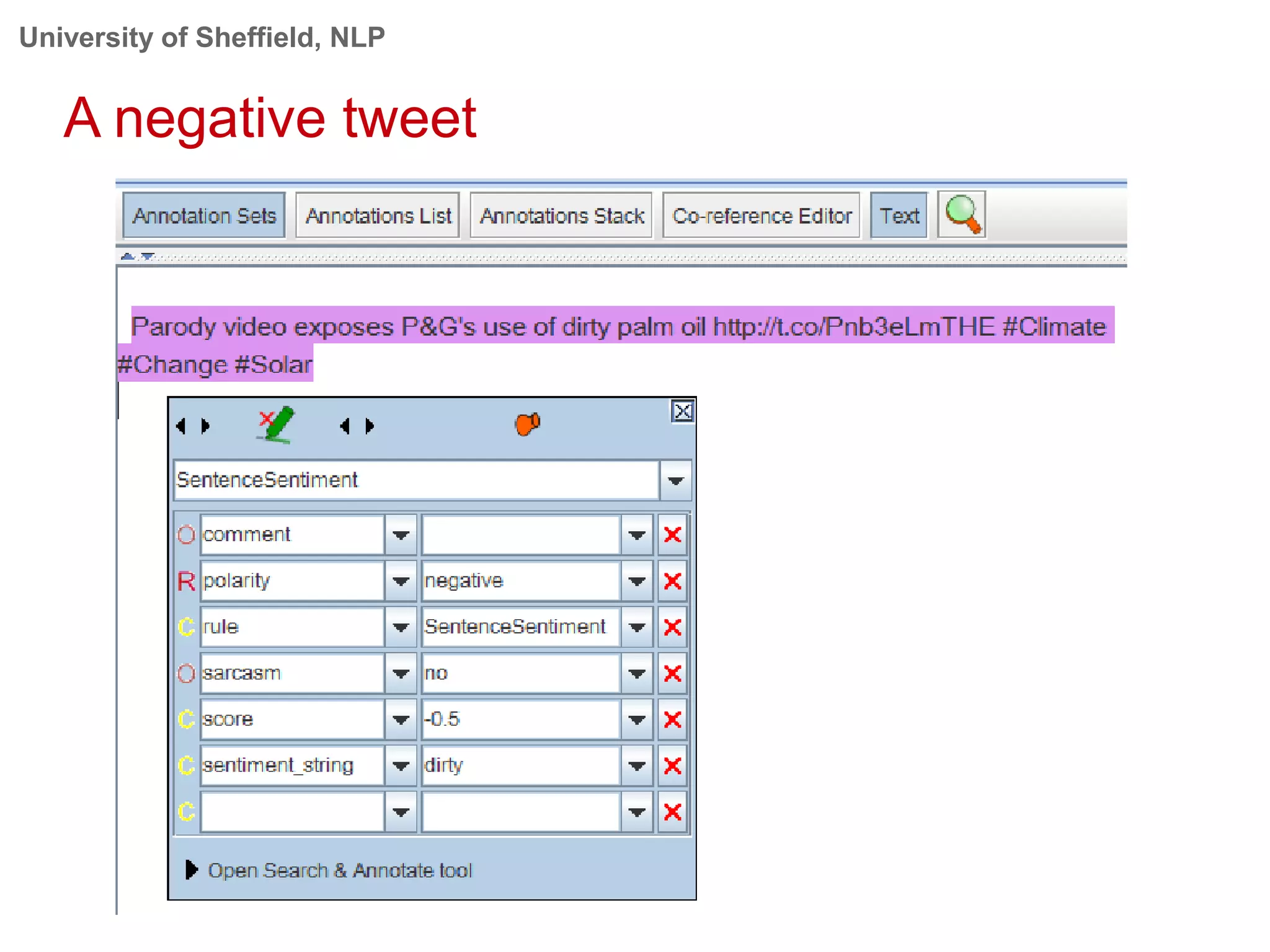
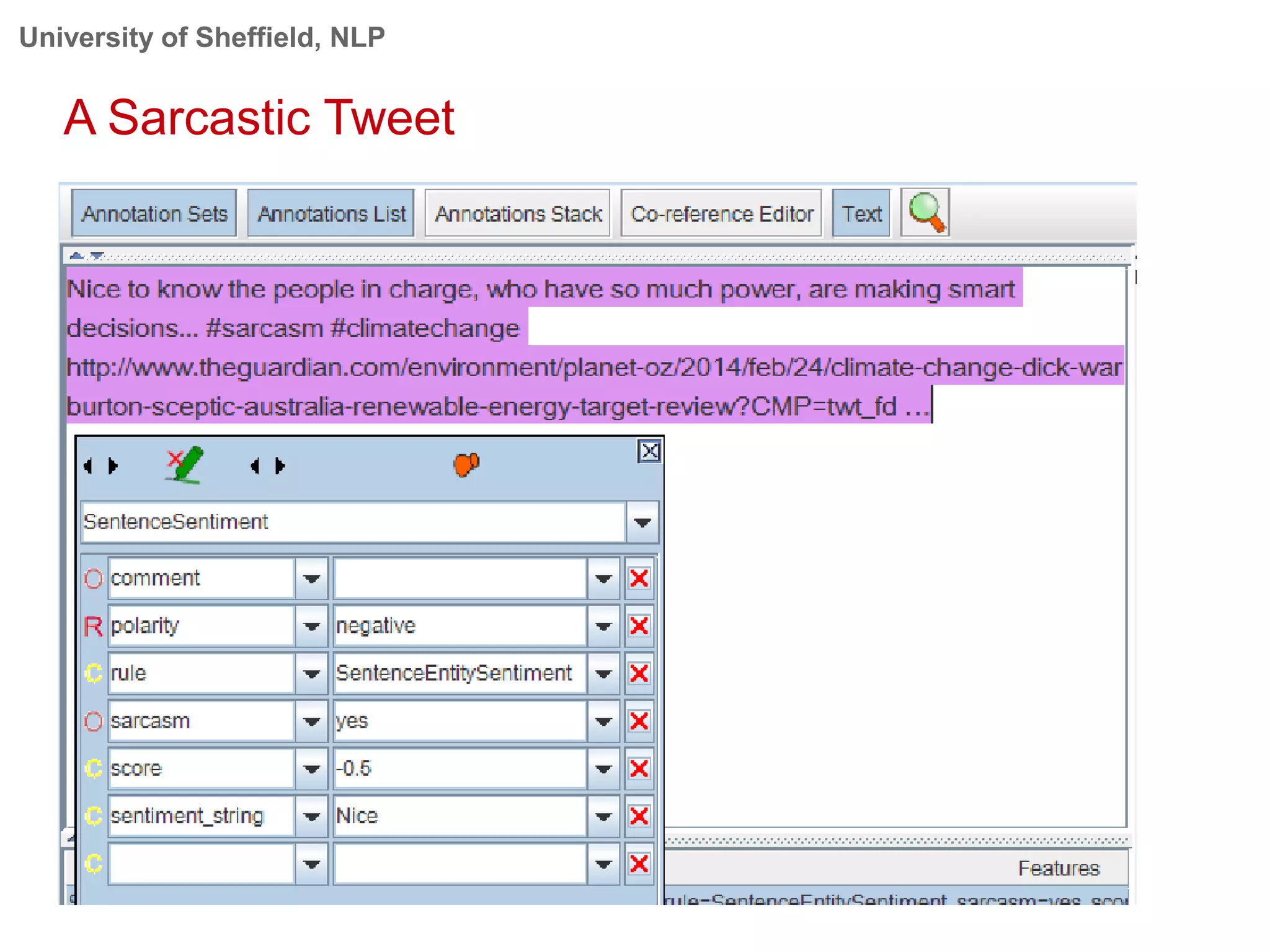
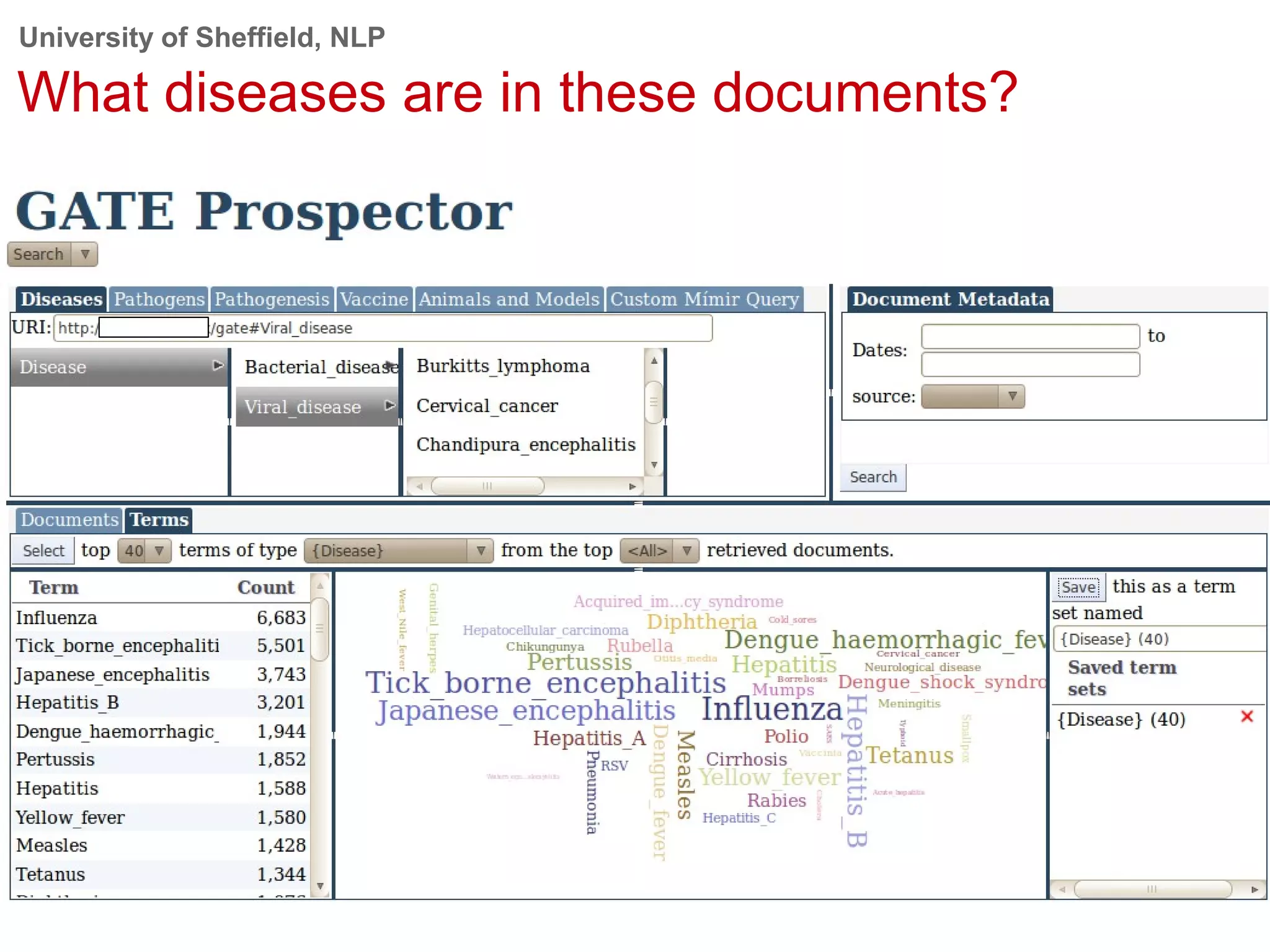

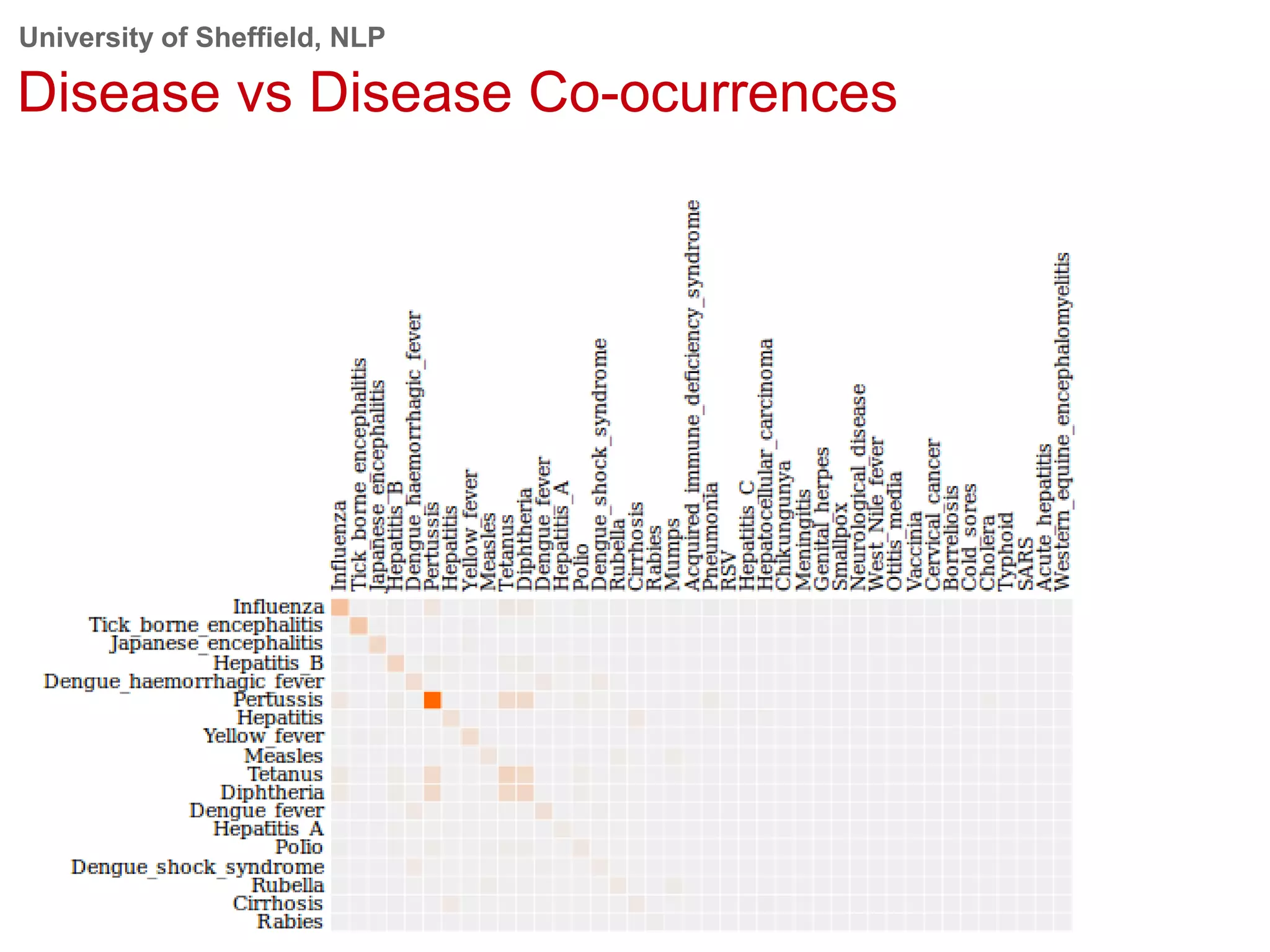
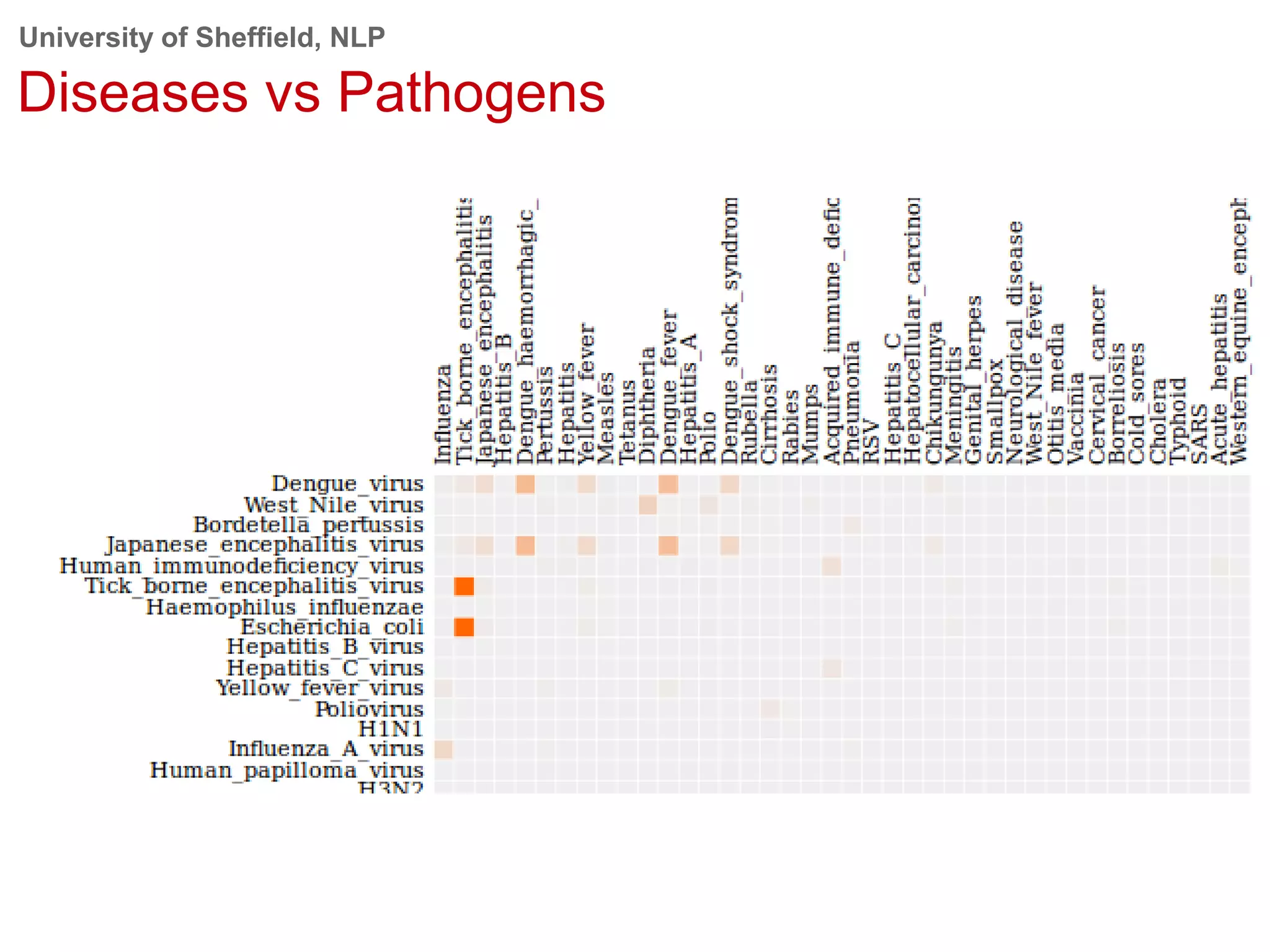

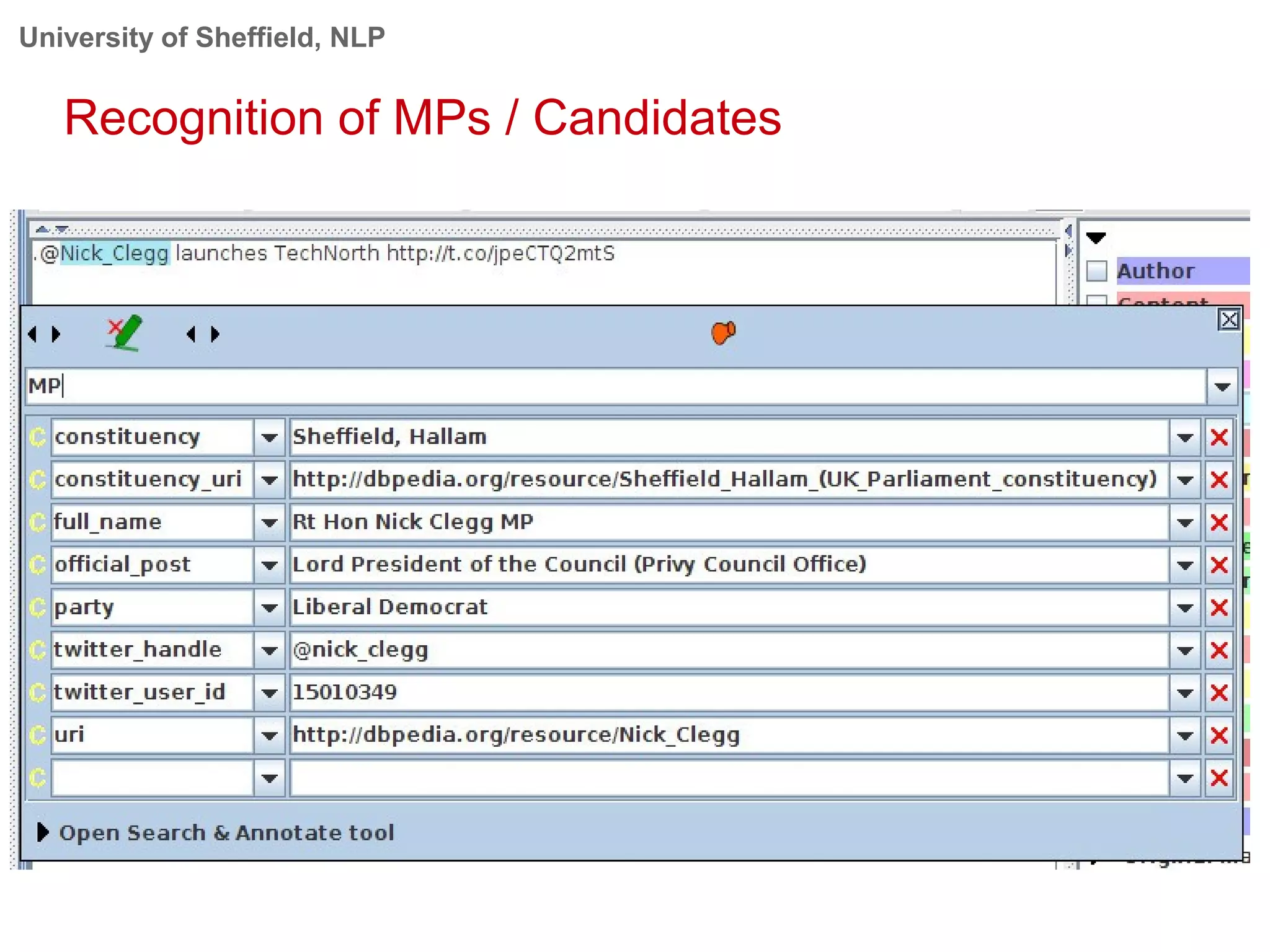
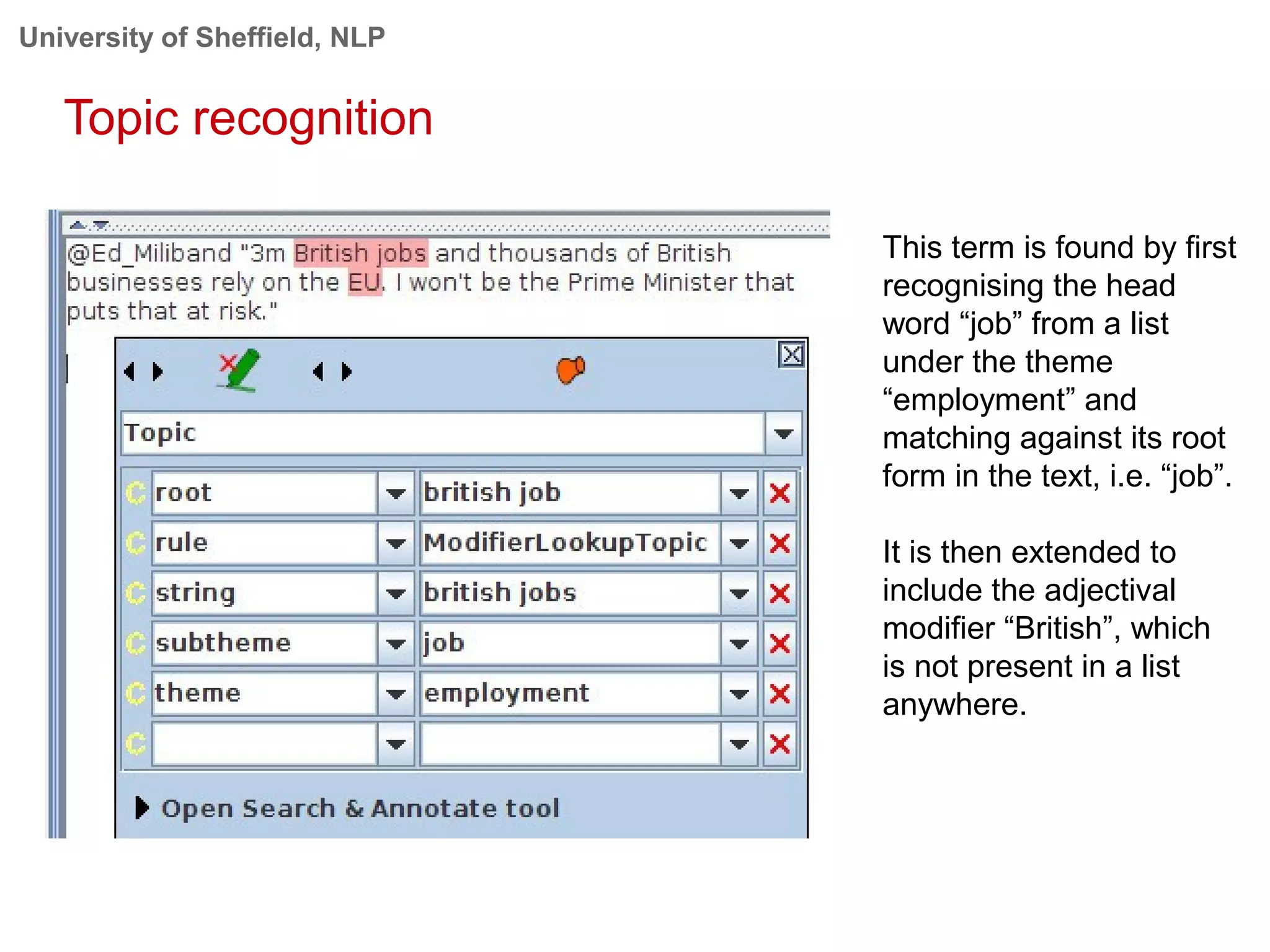





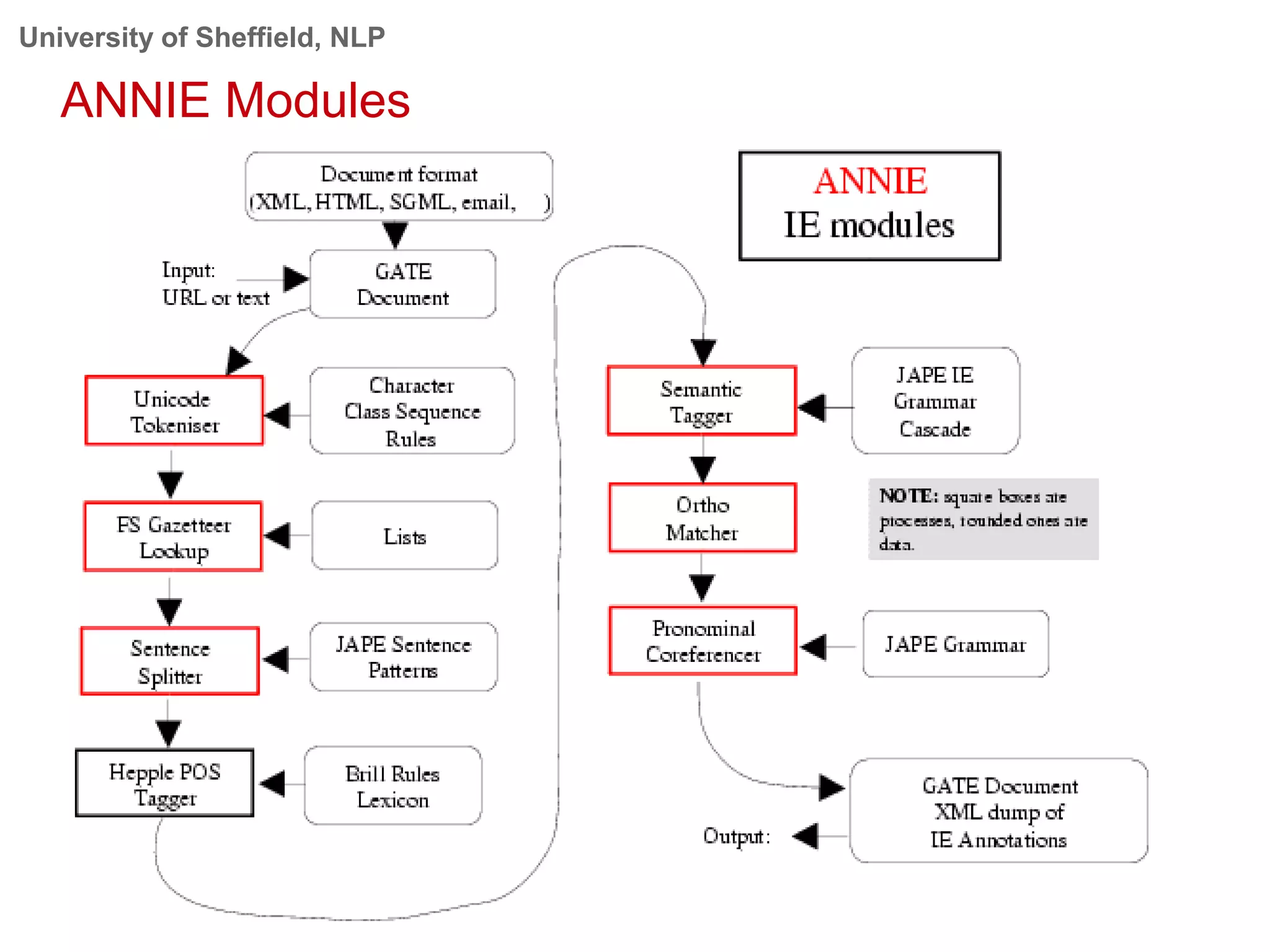
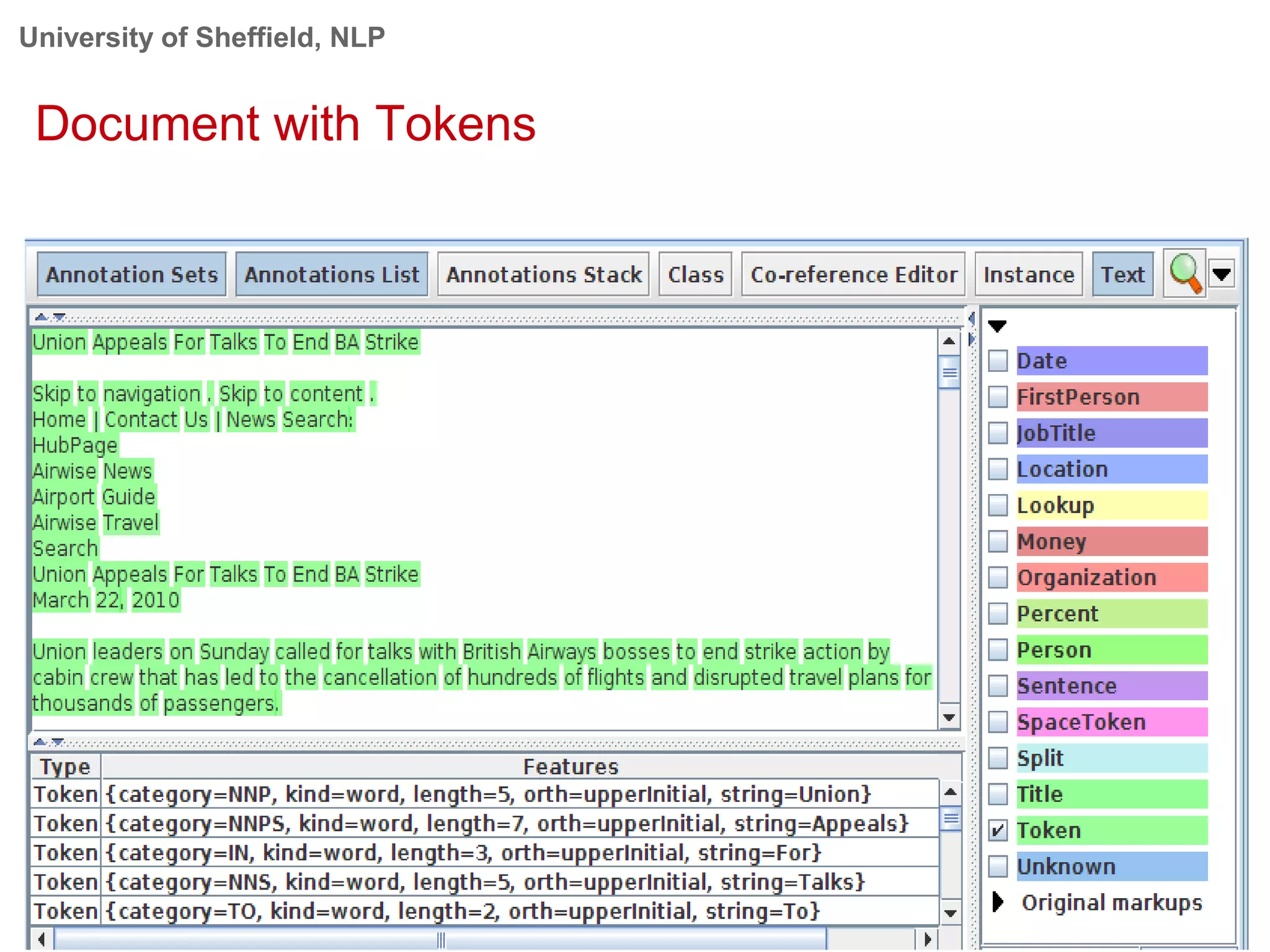
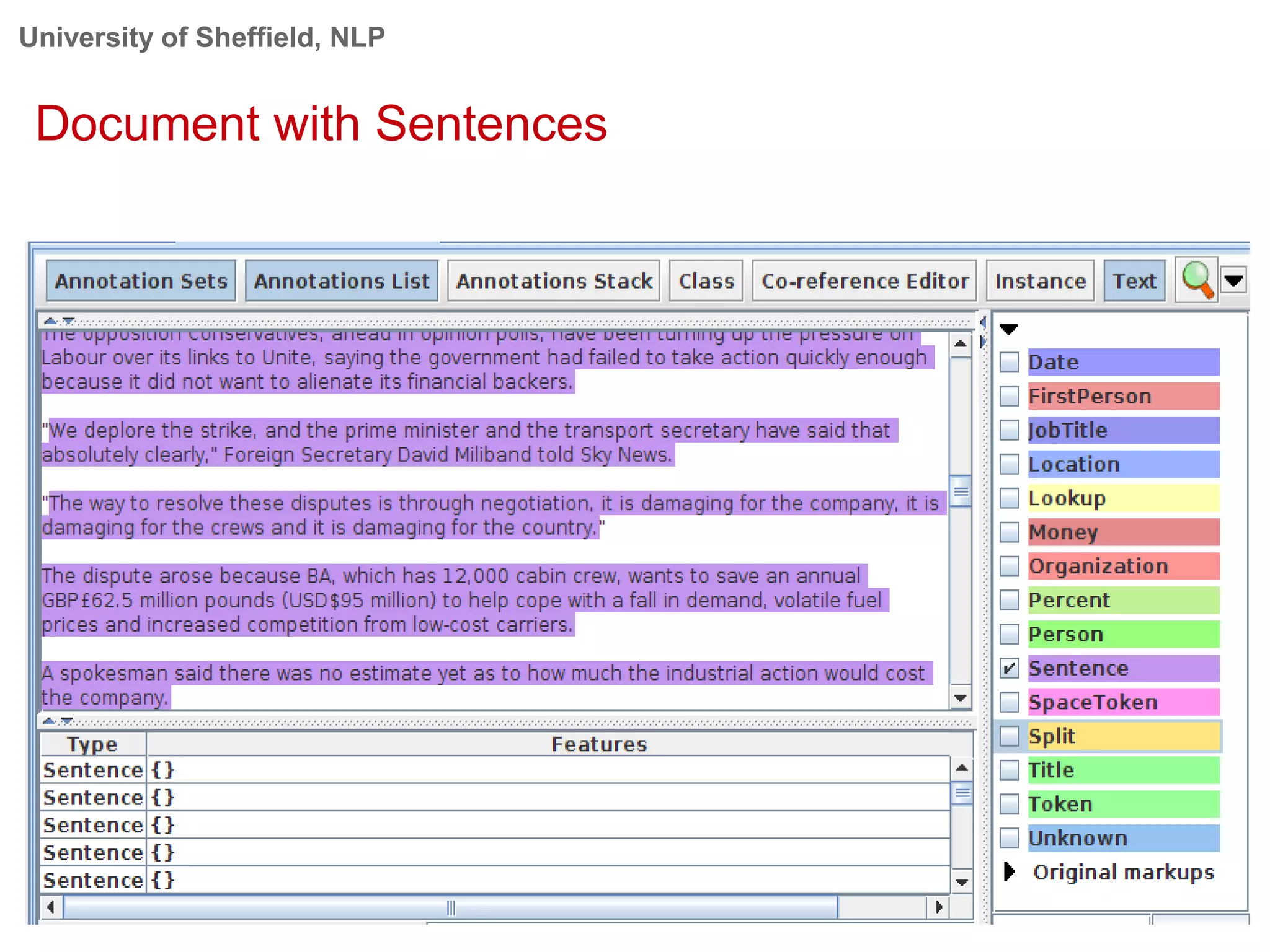
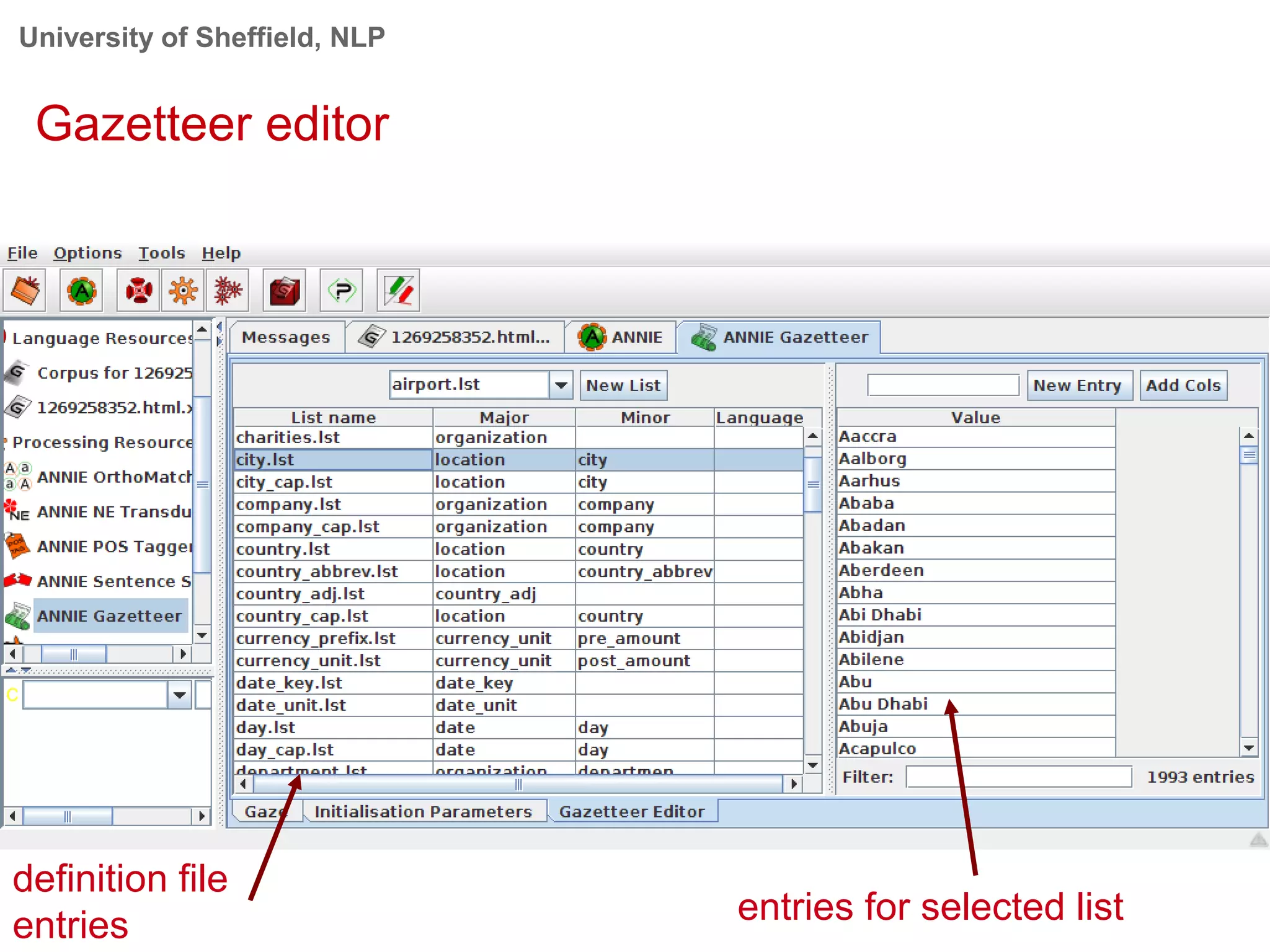
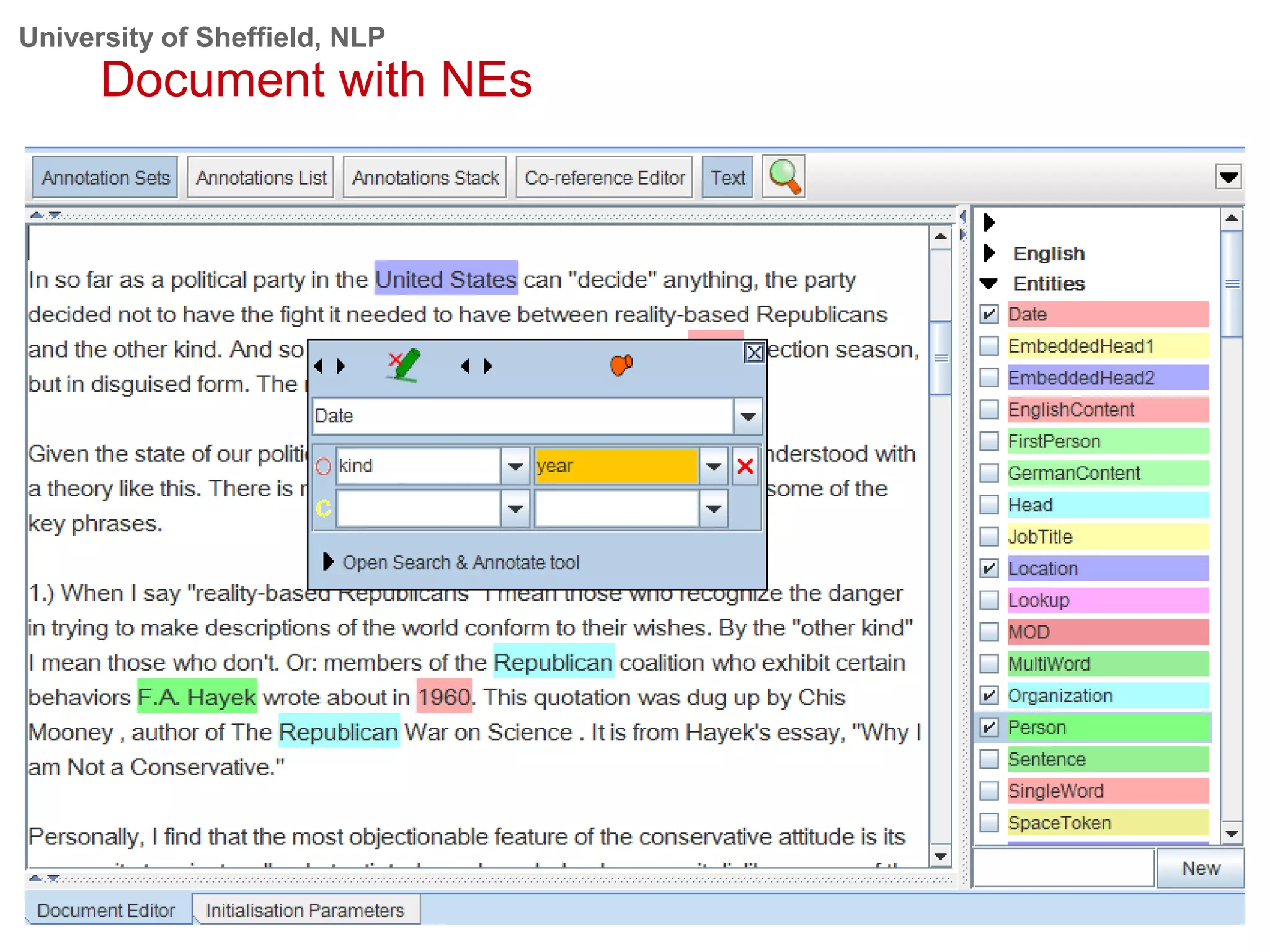
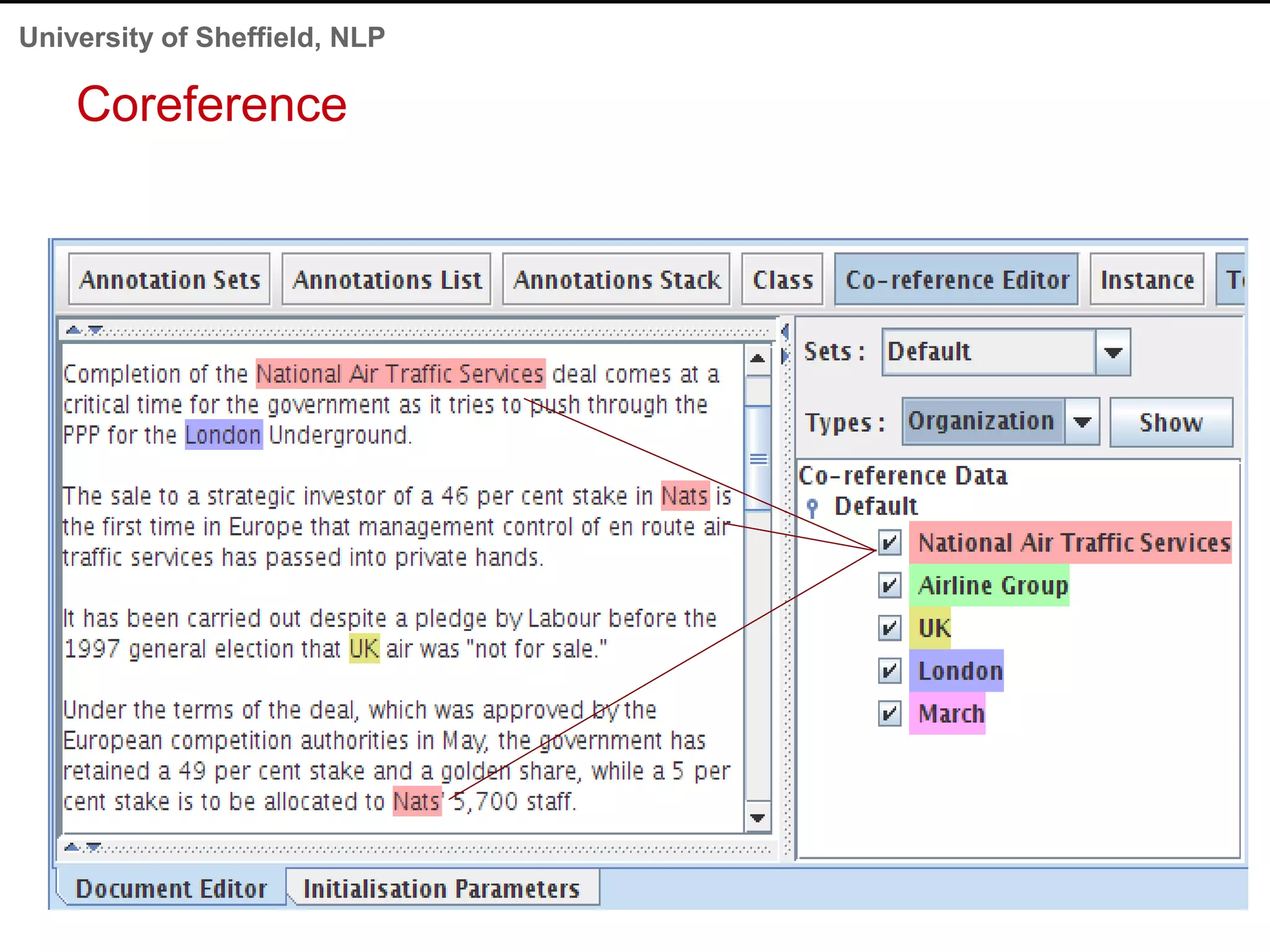
This document provides an overview of the GATE (General Architecture for Text Engineering) natural language processing toolkit. It discusses how GATE can be used to analyze social media texts, recognize entities and events, perform semantic search, and extract information. GATE includes components for language processing, information extraction tools, and resources for visualizing and annotating text. The document demonstrates running GATE's ANNIE information extraction system on news texts and tweets to recognize named entities. It also shows how GATE's semantic search tool Mimir can query annotated texts and semantic metadata.












































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)






![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


